 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Geometric Perspective on Visual Imitation Learning
Paper and Code
Mar 05, 2020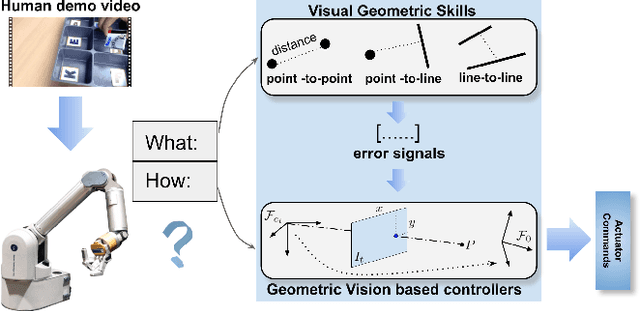
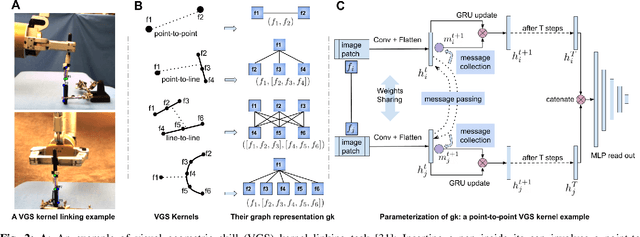
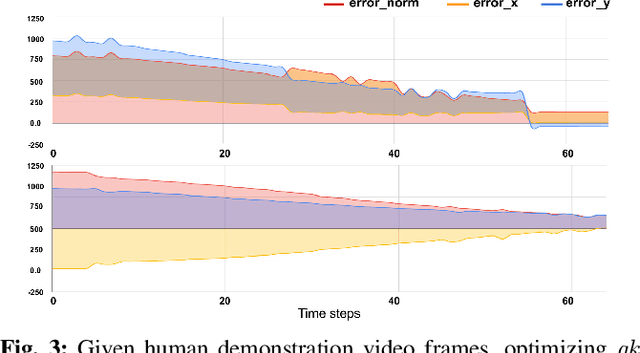
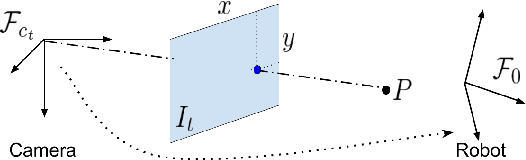
We consider the problem of visual imitation learning without human supervision (e.g. kinesthetic teaching or teleoperation), nor access to an interactive reinforcement learning (RL) training environment. We present a geometric perspective to derive solutions to this problem. Specifically, we propose VGS-IL (Visual Geometric Skill Imitation Learning), an end-to-end geometry-parameterized task concept inference method, to infer globally consistent geometric feature association rules from human demonstration video frames. We show that, instead of learning actions from image pixels, learning a geometry-parameterized task concept provides an explainable and invariant representation across demonstrator to imitator under various environmental settings. Moreover, such a task concept representation provides a direct link with geometric vision based controllers (e.g. visual servoing), allowing for efficient mapping of high-level task concepts to low-level robot actions.