 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImmersive Human-in-the-Loop Control: Real-Time 3D Surface Meshing and Physics Simulation
Dec 18, 2024



This paper introduces the TactiMesh Teleoperator Interface (TTI), a novel predictive visual and haptic system designed explicitly for human-in-the-loop robot control using a head-mounted display (HMD). By employing simultaneous localization and mapping (SLAM)in tandem with a space carving method (CARV), TTI creates a real time 3D surface mesh of remote environments from an RGB camera mounted on a Barrett WAM arm. The generated mesh is integrated into a physics simulator, featuring a digital twin of the WAM robot arm to create a virtual environment. In this virtual environment, TTI provides haptic feedback directly in response to the operator's movements, eliminating the problem with delayed response from the haptic follower robot. Furthermore, texturing the 3D mesh with keyframes from SLAM allows the operator to control the viewpoint of their Head Mounted Display (HMD) independently of the arm-mounted robot camera, giving a better visual immersion and improving manipulation speed. Incorporating predictive visual and haptic feedback significantly improves teleoperation in applications such as search and rescue, inspection, and remote maintenance.
* IROS 2024
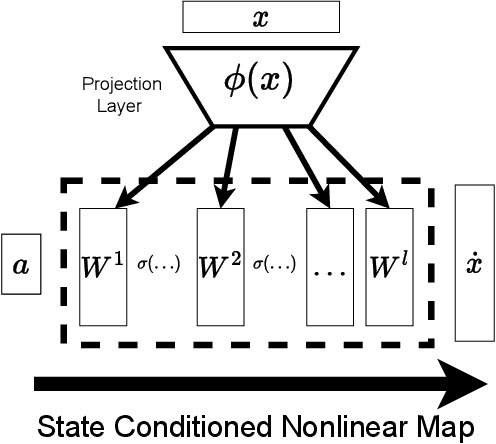
Learning State Conditioned Linear Mappings for Low-Dimensional Control of Robotic Manipulators
Oct 28, 2024



Identifying an appropriate task space that simplifies control solutions is important for solving robotic manipulation problems. One approach to this problem is learning an appropriate low-dimensional action space. Linear and nonlinear action mapping methods have trade-offs between simplicity on the one hand and the ability to express motor commands outside of a single low-dimensional subspace on the other. We propose that learning local linear action representations that adapt based on the current configuration of the robot achieves both of these benefits. Our state-conditioned linear maps ensure that for any given state, the high-dimensional robotic actuations are linear in the low-dimensional action. As the robot state evolves, so do the action mappings, ensuring the ability to represent motions that are immediately necessary. These local linear representations guarantee desirable theoretical properties by design, and we validate these findings empirically through two user studies. Results suggest state-conditioned linear maps outperform conditional autoencoder and PCA baselines on a pick-and-place task and perform comparably to mode switching in a more complex pouring task.
* 7 Pages, 8 Figures, Presented at the 2023 IEEE International Conference on Robotics and Automation (ICRA)
Investigating the Benefits of Nonlinear Action Maps in Data-Driven Teleoperation
Oct 28, 2024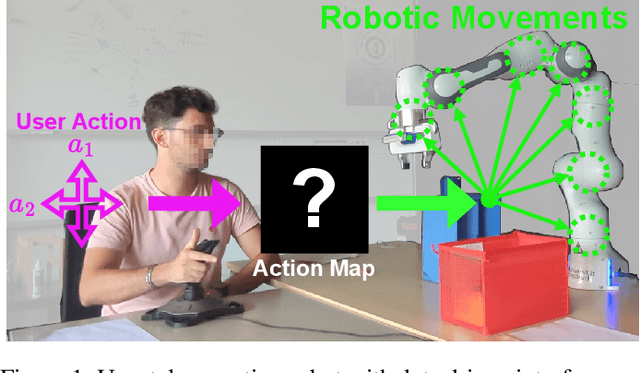


As robots become more common for both able-bodied individuals and those living with a disability, it is increasingly important that lay people be able to drive multi-degree-of-freedom platforms with low-dimensional controllers. One approach is to use state-conditioned action mapping methods to learn mappings between low-dimensional controllers and high DOF manipulators -- prior research suggests these mappings can simplify the teleoperation experience for users. Recent works suggest that neural networks predicting a local linear function are superior to the typical end-to-end multi-layer perceptrons because they allow users to more easily undo actions, providing more control over the system. However, local linear models assume actions exist on a linear subspace and may not capture nuanced actions in training data. We observe that the benefit of these mappings is being an odd function concerning user actions, and propose end-to-end nonlinear action maps which achieve this property. Unfortunately, our experiments show that such modifications offer minimal advantages over previous solutions. We find that nonlinear odd functions behave linearly for most of the control space, suggesting architecture structure improvements are not the primary factor in data-driven teleoperation. Our results suggest other avenues, such as data augmentation techniques and analysis of human behavior, are necessary for action maps to become practical in real-world applications, such as in assistive robotics to improve the quality of life of people living with w disability.
Robot Manipulation in Salient Vision through Referring Image Segmentation and Geometric Constraints
Sep 17, 2024



In this paper, we perform robot manipulation activities in real-world environments with language contexts by integrating a compact referring image segmentation model into the robot's perception module. First, we propose CLIPU$^2$Net, a lightweight referring image segmentation model designed for fine-grain boundary and structure segmentation from language expressions. Then, we deploy the model in an eye-in-hand visual servoing system to enact robot control in the real world. The key to our system is the representation of salient visual information as geometric constraints, linking the robot's visual perception to actionable commands. Experimental results on 46 real-world robot manipulation tasks demonstrate that our method outperforms traditional visual servoing methods relying on labor-intensive feature annotations, excels in fine-grain referring image segmentation with a compact decoder size of 6.6 MB, and supports robot control across diverse contexts.
Revisiting Sparse Rewards for Goal-Reaching Reinforcement Learning
Jul 08, 2024



Many real-world robot learning problems, such as pick-and-place or arriving at a destination, can be seen as a problem of reaching a goal state as soon as possible. These problems, when formulated as episodic reinforcement learning tasks, can easily be specified to align well with our intended goal: -1 reward every time step with termination upon reaching the goal state, called minimum-time tasks. Despite this simplicity, such formulations are often overlooked in favor of dense rewards due to their perceived difficulty and lack of informativeness. Our studies contrast the two reward paradigms, revealing that the minimum-time task specification not only facilitates learning higher-quality policies but can also surpass dense-reward-based policies on their own performance metrics. Crucially, we also identify the goal-hit rate of the initial policy as a robust early indicator for learning success in such sparse feedback settings. Finally, using four distinct real-robotic platforms, we show that it is possible to learn pixel-based policies from scratch within two to three hours using constant negative rewards.
Revisiting Constant Negative Rewards for Goal-Reaching Tasks in Robot Learning
Jun 29, 2024Many real-world robot learning problems, such as pick-and-place or arriving at a destination, can be seen as a problem of reaching a goal state as soon as possible. These problems, when formulated as episodic reinforcement learning tasks, can easily be specified to align well with our intended goal: -1 reward every time step with termination upon reaching the goal state, called minimum-time tasks. Despite this simplicity, such formulations are often overlooked in favor of dense rewards due to their perceived difficulty and lack of informativeness. Our studies contrast the two reward paradigms, revealing that the minimum-time task specification not only facilitates learning higher-quality policies but can also surpass dense-reward-based policies on their own performance metrics. Crucially, we also identify the goal-hit rate of the initial policy as a robust early indicator for learning success in such sparse feedback settings. Finally, using four distinct real-robotic platforms, we show that it is possible to learn pixel-based policies from scratch within two to three hours using constant negative rewards.
Bridging Low-level Geometry to High-level Concepts in Visual Servoing of Robot Manipulation Task Using Event Knowledge Graphs and Vision-Language Models
Oct 05, 2023



In this paper, we propose a framework of building knowledgeable robot control in the scope of smart human-robot interaction, by empowering a basic uncalibrated visual servoing controller with contextual knowledge through the joint usage of event knowledge graphs (EKGs) and large-scale pretrained vision-language models (VLMs). The framework is expanded in twofold: first, we interpret low-level image geometry as high-level concepts, allowing us to prompt VLMs and to select geometric features of points and lines for motor control skills; then, we create an event knowledge graph (EKG) to conceptualize a robot manipulation task of interest, where the main body of the EKG is characterized by an executable behavior tree, and the leaves by semantic concepts relevant to the manipulation context. We demonstrate, in an uncalibrated environment with real robot trials, that our method lowers the reliance of human annotation during task interfacing, allows the robot to perform activities of daily living more easily by treating low-level geometric-based motor control skills as high-level concepts, and is beneficial in building cognitive thinking for smart robot applications.
CLIPUNetr: Assisting Human-robot Interface for Uncalibrated Visual Servoing Control with CLIP-driven Referring Expression Segmentation
Sep 17, 2023



The classical human-robot interface in uncalibrated image-based visual servoing (UIBVS) relies on either human annotations or semantic segmentation with categorical labels. Both methods fail to match natural human communication and convey rich semantics in manipulation tasks as effectively as natural language expressions. In this paper, we tackle this problem by using referring expression segmentation, which is a prompt-based approach, to provide more in-depth information for robot perception. To generate high-quality segmentation predictions from referring expressions, we propose CLIPUNetr - a new CLIP-driven referring expression segmentation network. CLIPUNetr leverages CLIP's strong vision-language representations to segment regions from referring expressions, while utilizing its ``U-shaped'' encoder-decoder architecture to generate predictions with sharper boundaries and finer structures. Furthermore, we propose a new pipeline to integrate CLIPUNetr into UIBVS and apply it to control robots in real-world environments. In experiments, our method improves boundary and structure measurements by an average of 120% and can successfully assist real-world UIBVS control in an unstructured manipulation environment.
Deep Probabilistic Movement Primitives with a Bayesian Aggregator
Jul 11, 2023



Movement primitives are trainable parametric models that reproduce robotic movements starting from a limited set of demonstrations. Previous works proposed simple linear models that exhibited high sample efficiency and generalization power by allowing temporal modulation of movements (reproducing movements faster or slower), blending (merging two movements into one), via-point conditioning (constraining a movement to meet some particular via-points) and context conditioning (generation of movements based on an observed variable, e.g., position of an object). Previous works have proposed neural network-based motor primitive models, having demonstrated their capacity to perform tasks with some forms of input conditioning or time-modulation representations. However, there has not been a single unified deep motor primitive's model proposed that is capable of all previous operations, limiting neural motor primitive's potential applications. This paper proposes a deep movement primitive architecture that encodes all the operations above and uses a Bayesian context aggregator that allows a more sound context conditioning and blending. Our results demonstrate our approach can scale to reproduce complex motions on a larger variety of input choices compared to baselines while maintaining operations of linear movement primitives provide.
A Simple Decentralized Cross-Entropy Method
Dec 16, 2022



Cross-Entropy Method (CEM) is commonly used for planning in model-based reinforcement learning (MBRL) where a centralized approach is typically utilized to update the sampling distribution based on only the top-$k$ operation's results on samples. In this paper, we show that such a centralized approach makes CEM vulnerable to local optima, thus impairing its sample efficiency. To tackle this issue, we propose Decentralized CEM (DecentCEM), a simple but effective improvement over classical CEM, by using an ensemble of CEM instances running independently from one another, and each performing a local improvement of its own sampling distribution. We provide both theoretical and empirical analysis to demonstrate the effectiveness of this simple decentralized approach. We empirically show that, compared to the classical centralized approach using either a single or even a mixture of Gaussian distributions, our DecentCEM finds the global optimum much more consistently thus improves the sample efficiency. Furthermore, we plug in our DecentCEM in the planning problem of MBRL, and evaluate our approach in several continuous control environments, with comparison to the state-of-art CEM based MBRL approaches (PETS and POPLIN). Results show sample efficiency improvement by simply replacing the classical CEM module with our DecentCEM module, while only sacrificing a reasonable amount of computational cost. Lastly, we conduct ablation studies for more in-depth analysis. Code is available at https://github.com/vincentzhang/decentCEM