 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynchronous vs Asynchronous Reinforcement Learning in a Real World Robot
Mar 17, 2025



In recent times, reinforcement learning (RL) with physical robots has attracted the attention of a wide range of researchers. However, state-of-the-art RL algorithms do not consider that physical environments do not wait for the RL agent to make decisions or updates. RL agents learn by periodically conducting computationally expensive gradient updates. When decision-making and gradient update tasks are carried out sequentially by the RL agent in a physical robot, it significantly increases the agent's response time. In a rapidly changing environment, this increased response time may be detrimental to the performance of the learning agent. Asynchronous RL methods, which separate the computation of decision-making and gradient updates, are a potential solution to this problem. However, only a few comparisons between asynchronous and synchronous RL have been made with physical robots. For this reason, the exact performance benefits of using asynchronous RL methods over synchronous RL methods are still unclear. In this study, we provide a performance comparison between asynchronous and synchronous RL using a physical robotic arm called Franka Emika Panda. Our experiments show that the agents learn faster and attain significantly more returns using asynchronous RL. Our experiments also demonstrate that the learning agent with a faster response time performs better than the agent with a slower response time, even if the agent with a slower response time performs a higher number of gradient updates.
Design and Implementation of a Scalable Clinical Data Warehouse for Resource-Constrained Healthcare Systems
Feb 23, 2025



Centralized electronic health record repositories are critical for advancing disease surveillance, public health research, and evidence-based policymaking. However, developing countries face persistent challenges in achieving this due to fragmented healthcare data sources, inconsistent record-keeping practices, and the absence of standardized patient identifiers, limiting reliable record linkage, compromise data interoperability, and limit scalability-obstacles exacerbated by infrastructural constraints and privacy concerns. To address these barriers, this study proposes a scalable, privacy-preserving clinical data warehouse, NCDW, designed for heterogeneous EHR integration in resource-limited settings and tested with 1.16 million clinical records. The framework incorporates a wrapper-based data acquisition layer for secure, automated ingestion of multisource health data and introduces a soundex algorithm to resolve patient identity mismatches in the absence of unique IDs. A modular data mart is designed for disease-specific analytics, demonstrated through a dengue fever case study in Bangladesh, integrating clinical, demographic, and environmental data for outbreak prediction and resource planning. Quantitative assessment of the data mart underscores its utility in strengthening national decision-support systems, highlighting the model's adaptability for infectious disease management. Comparative evaluation of database technologies reveals NoSQL outperforms relational SQL by 40-69% in complex query processing, while system load estimates validate the architecture's capacity to manage 19 million daily records (34TB over 5 years). The framework can be adapted to various healthcare settings across developing nations by modifying the ingestion layer to accommodate standards like ICD-11 and HL7 FHIR, facilitating interoperability for managing infectious diseases (i.e., COVID, tuberculosis).
Revisiting Sparse Rewards for Goal-Reaching Reinforcement Learning
Jul 08, 2024



Many real-world robot learning problems, such as pick-and-place or arriving at a destination, can be seen as a problem of reaching a goal state as soon as possible. These problems, when formulated as episodic reinforcement learning tasks, can easily be specified to align well with our intended goal: -1 reward every time step with termination upon reaching the goal state, called minimum-time tasks. Despite this simplicity, such formulations are often overlooked in favor of dense rewards due to their perceived difficulty and lack of informativeness. Our studies contrast the two reward paradigms, revealing that the minimum-time task specification not only facilitates learning higher-quality policies but can also surpass dense-reward-based policies on their own performance metrics. Crucially, we also identify the goal-hit rate of the initial policy as a robust early indicator for learning success in such sparse feedback settings. Finally, using four distinct real-robotic platforms, we show that it is possible to learn pixel-based policies from scratch within two to three hours using constant negative rewards.
Revisiting Constant Negative Rewards for Goal-Reaching Tasks in Robot Learning
Jun 29, 2024Many real-world robot learning problems, such as pick-and-place or arriving at a destination, can be seen as a problem of reaching a goal state as soon as possible. These problems, when formulated as episodic reinforcement learning tasks, can easily be specified to align well with our intended goal: -1 reward every time step with termination upon reaching the goal state, called minimum-time tasks. Despite this simplicity, such formulations are often overlooked in favor of dense rewards due to their perceived difficulty and lack of informativeness. Our studies contrast the two reward paradigms, revealing that the minimum-time task specification not only facilitates learning higher-quality policies but can also surpass dense-reward-based policies on their own performance metrics. Crucially, we also identify the goal-hit rate of the initial policy as a robust early indicator for learning success in such sparse feedback settings. Finally, using four distinct real-robotic platforms, we show that it is possible to learn pixel-based policies from scratch within two to three hours using constant negative rewards.
Automatic Monitoring Social Dynamics During Big Incidences: A Case Study of COVID-19 in Bangladesh
Jan 31, 2021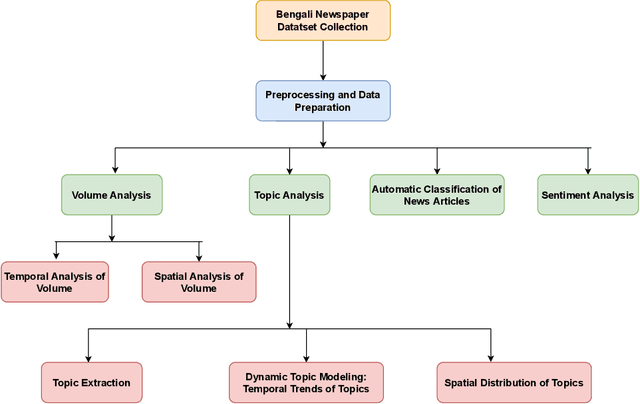

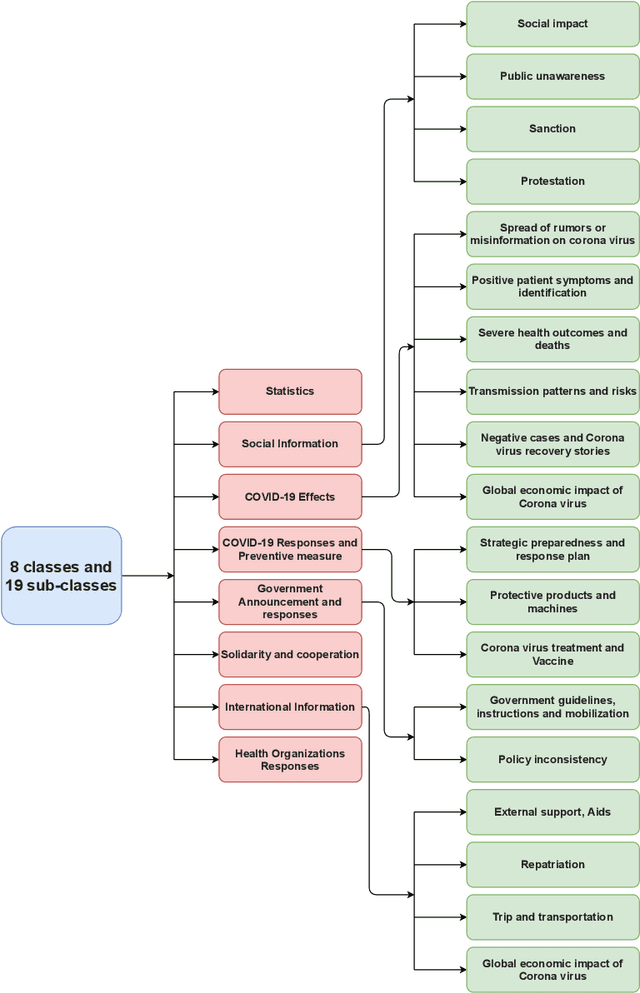
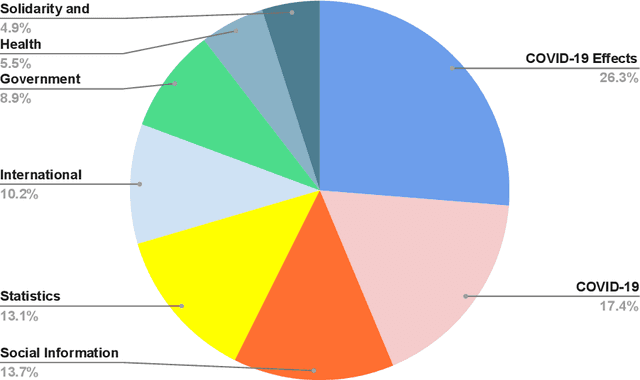
Newspapers are trustworthy media where people get the most reliable and credible information compared with other sources. On the other hand, social media often spread rumors and misleading news to get more traffic and attention. Careful characterization, evaluation, and interpretation of newspaper data can provide insight into intrigue and passionate social issues to monitor any big social incidence. This study analyzed a large set of spatio-temporal Bangladeshi newspaper data related to the COVID-19 pandemic. The methodology included volume analysis, topic analysis, automated classification, and sentiment analysis of news articles to get insight into the COVID-19 pandemic in different sectors and regions in Bangladesh over a period of time. This analysis will help the government and other organizations to figure out the challenges that have arisen in society due to this pandemic, what steps should be taken immediately and in the post-pandemic period, how the government and its allies can come together to address the crisis in the future, keeping these problems in mind.