 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Policy Gradient Methods Without Batch Updates, Target Networks, or Replay Buffers
Nov 22, 2024Modern deep policy gradient methods achieve effective performance on simulated robotic tasks, but they all require large replay buffers or expensive batch updates, or both, making them incompatible for real systems with resource-limited computers. We show that these methods fail catastrophically when limited to small replay buffers or during incremental learning, where updates only use the most recent sample without batch updates or a replay buffer. We propose a novel incremental deep policy gradient method -- Action Value Gradient (AVG) and a set of normalization and scaling techniques to address the challenges of instability in incremental learning. On robotic simulation benchmarks, we show that AVG is the only incremental method that learns effectively, often achieving final performance comparable to batch policy gradient methods. This advancement enabled us to show for the first time effective deep reinforcement learning with real robots using only incremental updates, employing a robotic manipulator and a mobile robot.
Streaming Deep Reinforcement Learning Finally Works
Oct 18, 2024Natural intelligence processes experience as a continuous stream, sensing, acting, and learning moment-by-moment in real time. Streaming learning, the modus operandi of classic reinforcement learning (RL) algorithms like Q-learning and TD, mimics natural learning by using the most recent sample without storing it. This approach is also ideal for resource-constrained, communication-limited, and privacy-sensitive applications. However, in deep RL, learners almost always use batch updates and replay buffers, making them computationally expensive and incompatible with streaming learning. Although the prevalence of batch deep RL is often attributed to its sample efficiency, a more critical reason for the absence of streaming deep RL is its frequent instability and failure to learn, which we refer to as stream barrier. This paper introduces the stream-x algorithms, the first class of deep RL algorithms to overcome stream barrier for both prediction and control and match sample efficiency of batch RL. Through experiments in Mujoco Gym, DM Control Suite, and Atari Games, we demonstrate stream barrier in existing algorithms and successful stable learning with our stream-x algorithms: stream Q, stream AC, and stream TD, achieving the best model-free performance in DM Control Dog environments. A set of common techniques underlies the stream-x algorithms, enabling their success with a single set of hyperparameters and allowing for easy extension to other algorithms, thereby reviving streaming RL.
Revisiting Sparse Rewards for Goal-Reaching Reinforcement Learning
Jul 08, 2024



Many real-world robot learning problems, such as pick-and-place or arriving at a destination, can be seen as a problem of reaching a goal state as soon as possible. These problems, when formulated as episodic reinforcement learning tasks, can easily be specified to align well with our intended goal: -1 reward every time step with termination upon reaching the goal state, called minimum-time tasks. Despite this simplicity, such formulations are often overlooked in favor of dense rewards due to their perceived difficulty and lack of informativeness. Our studies contrast the two reward paradigms, revealing that the minimum-time task specification not only facilitates learning higher-quality policies but can also surpass dense-reward-based policies on their own performance metrics. Crucially, we also identify the goal-hit rate of the initial policy as a robust early indicator for learning success in such sparse feedback settings. Finally, using four distinct real-robotic platforms, we show that it is possible to learn pixel-based policies from scratch within two to three hours using constant negative rewards.
Revisiting Constant Negative Rewards for Goal-Reaching Tasks in Robot Learning
Jun 29, 2024Many real-world robot learning problems, such as pick-and-place or arriving at a destination, can be seen as a problem of reaching a goal state as soon as possible. These problems, when formulated as episodic reinforcement learning tasks, can easily be specified to align well with our intended goal: -1 reward every time step with termination upon reaching the goal state, called minimum-time tasks. Despite this simplicity, such formulations are often overlooked in favor of dense rewards due to their perceived difficulty and lack of informativeness. Our studies contrast the two reward paradigms, revealing that the minimum-time task specification not only facilitates learning higher-quality policies but can also surpass dense-reward-based policies on their own performance metrics. Crucially, we also identify the goal-hit rate of the initial policy as a robust early indicator for learning success in such sparse feedback settings. Finally, using four distinct real-robotic platforms, we show that it is possible to learn pixel-based policies from scratch within two to three hours using constant negative rewards.
MaDi: Learning to Mask Distractions for Generalization in Visual Deep Reinforcement Learning
Dec 23, 2023



The visual world provides an abundance of information, but many input pixels received by agents often contain distracting stimuli. Autonomous agents need the ability to distinguish useful information from task-irrelevant perceptions, enabling them to generalize to unseen environments with new distractions. Existing works approach this problem using data augmentation or large auxiliary networks with additional loss functions. We introduce MaDi, a novel algorithm that learns to mask distractions by the reward signal only. In MaDi, the conventional actor-critic structure of deep reinforcement learning agents is complemented by a small third sibling, the Masker. This lightweight neural network generates a mask to determine what the actor and critic will receive, such that they can focus on learning the task. The masks are created dynamically, depending on the current input. We run experiments on the DeepMind Control Generalization Benchmark, the Distracting Control Suite, and a real UR5 Robotic Arm. Our algorithm improves the agent's focus with useful masks, while its efficient Masker network only adds 0.2% more parameters to the original structure, in contrast to previous work. MaDi consistently achieves generalization results better than or competitive to state-of-the-art methods.
Correcting discount-factor mismatch in on-policy policy gradient methods
Jun 23, 2023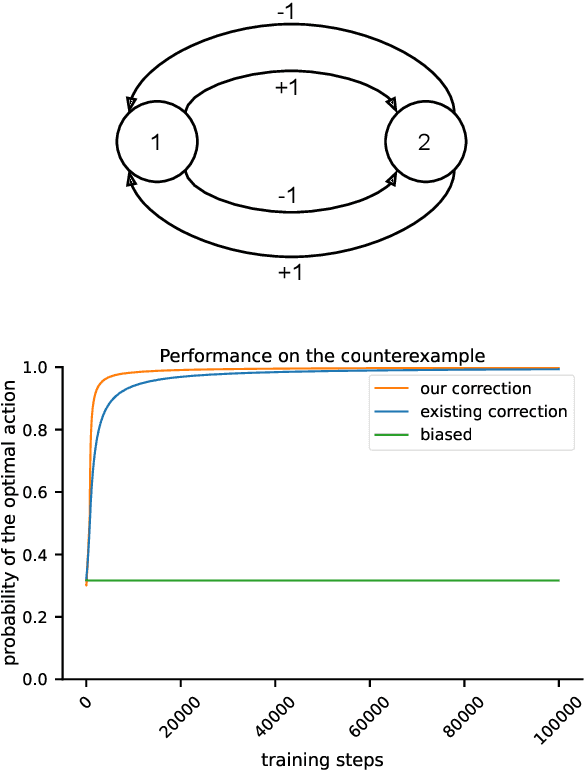
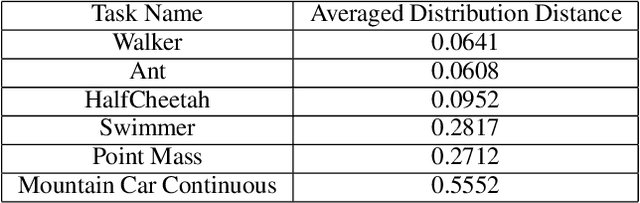
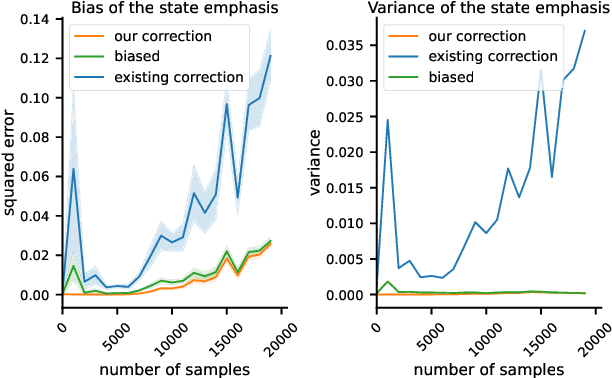
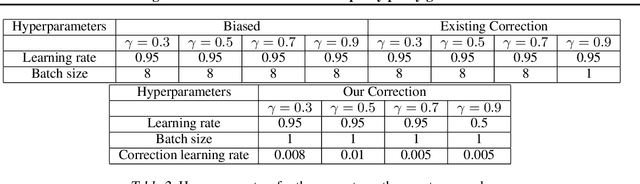
The policy gradient theorem gives a convenient form of the policy gradient in terms of three factors: an action value, a gradient of the action likelihood, and a state distribution involving discounting called the \emph{discounted stationary distribution}. But commonly used on-policy methods based on the policy gradient theorem ignores the discount factor in the state distribution, which is technically incorrect and may even cause degenerate learning behavior in some environments. An existing solution corrects this discrepancy by using $\gamma^t$ as a factor in the gradient estimate. However, this solution is not widely adopted and does not work well in tasks where the later states are similar to earlier states. We introduce a novel distribution correction to account for the discounted stationary distribution that can be plugged into many existing gradient estimators. Our correction circumvents the performance degradation associated with the $\gamma^t$ correction with a lower variance. Importantly, compared to the uncorrected estimators, our algorithm provides improved state emphasis to evade suboptimal policies in certain environments and consistently matches or exceeds the original performance on several OpenAI gym and DeepMind suite benchmarks.
Real-Time Reinforcement Learning for Vision-Based Robotics Utilizing Local and Remote Computers
Oct 05, 2022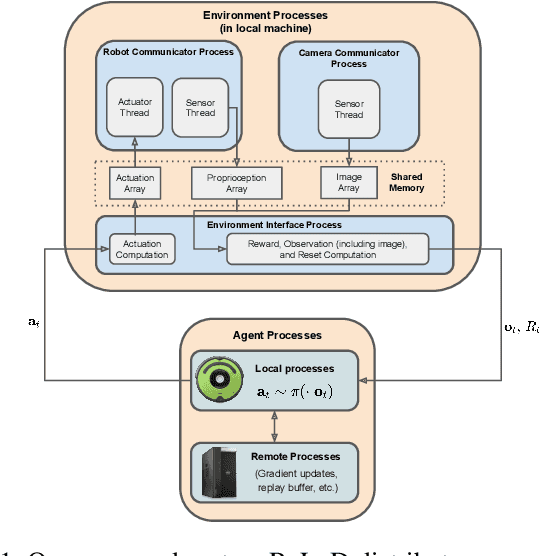
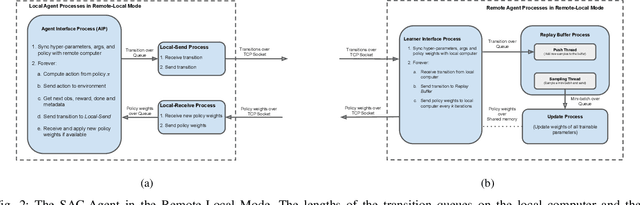
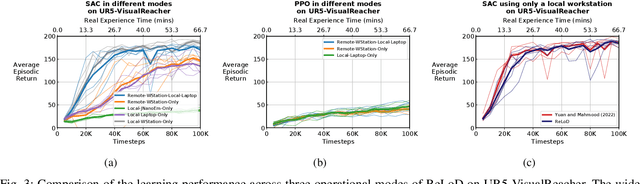
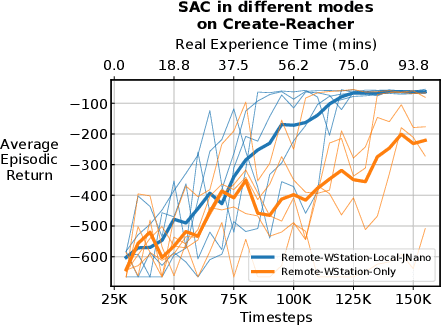
Real-time learning is crucial for robotic agents adapting to ever-changing, non-stationary environments. A common setup for a robotic agent is to have two different computers simultaneously: a resource-limited local computer tethered to the robot and a powerful remote computer connected wirelessly. Given such a setup, it is unclear to what extent the performance of a learning system can be affected by resource limitations and how to efficiently use the wirelessly connected powerful computer to compensate for any performance loss. In this paper, we implement a real-time learning system called the Remote-Local Distributed (ReLoD) system to distribute computations of two deep reinforcement learning (RL) algorithms, Soft Actor-Critic (SAC) and Proximal Policy Optimization (PPO), between a local and a remote computer. The performance of the system is evaluated on two vision-based control tasks developed using a robotic arm and a mobile robot. Our results show that SAC's performance degrades heavily on a resource-limited local computer. Strikingly, when all computations of the learning system are deployed on a remote workstation, SAC fails to compensate for the performance loss, indicating that, without careful consideration, using a powerful remote computer may not result in performance improvement. However, a carefully chosen distribution of computations of SAC consistently and substantially improves its performance on both tasks. On the other hand, the performance of PPO remains largely unaffected by the distribution of computations. In addition, when all computations happen solely on a powerful tethered computer, the performance of our system remains on par with an existing system that is well-tuned for using a single machine. ReLoD is the only publicly available system for real-time RL that applies to multiple robots for vision-based tasks.
Autoregressive Policies for Continuous Control Deep Reinforcement Learning
Mar 27, 2019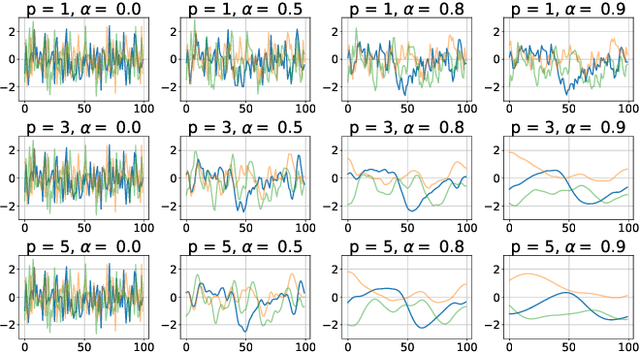
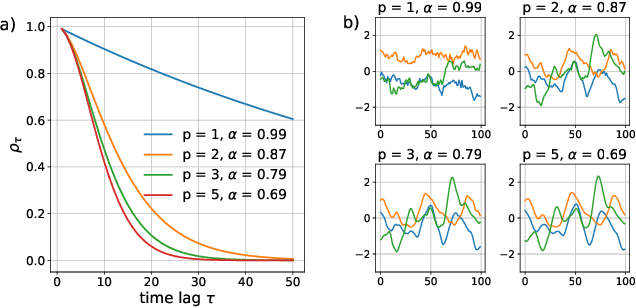
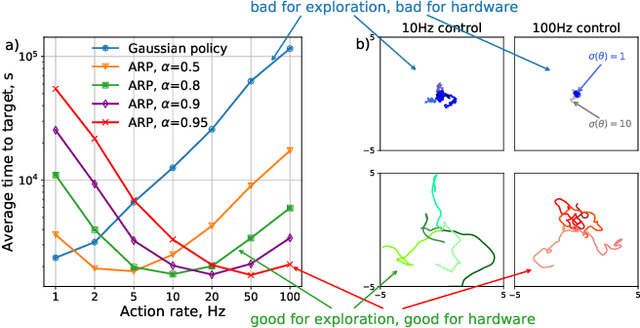
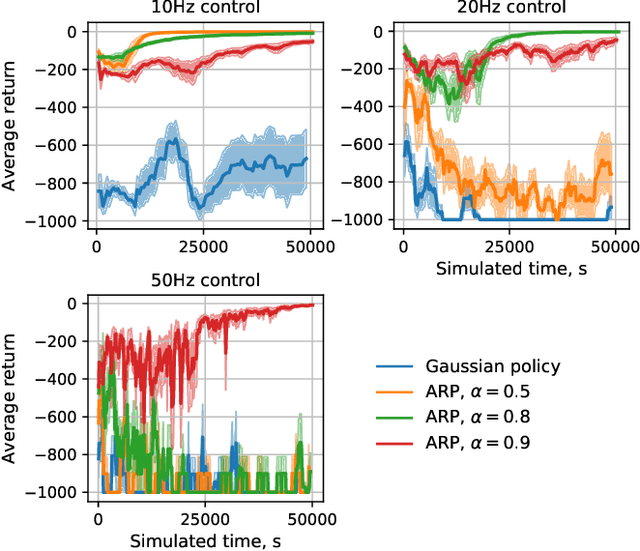
Reinforcement learning algorithms rely on exploration to discover new behaviors, which is typically achieved by following a stochastic policy. In continuous control tasks, policies with a Gaussian distribution have been widely adopted. Gaussian exploration however does not result in smooth trajectories that generally correspond to safe and rewarding behaviors in practical tasks. In addition, Gaussian policies do not result in an effective exploration of an environment and become increasingly inefficient as the action rate increases. This contributes to a low sample efficiency often observed in learning continuous control tasks. We introduce a family of stationary autoregressive (AR) stochastic processes to facilitate exploration in continuous control domains. We show that proposed processes possess two desirable features: subsequent process observations are temporally coherent with continuously adjustable degree of coherence, and the process stationary distribution is standard normal. We derive an autoregressive policy (ARP) that implements such processes maintaining the standard agent-environment interface. We show how ARPs can be easily used with the existing off-the-shelf learning algorithms. Empirically we demonstrate that using ARPs results in improved exploration and sample efficiency in both simulated and real world domains, and, furthermore, provides smooth exploration trajectories that enable safe operation of robotic hardware.
Benchmarking Reinforcement Learning Algorithms on Real-World Robots
Sep 20, 2018
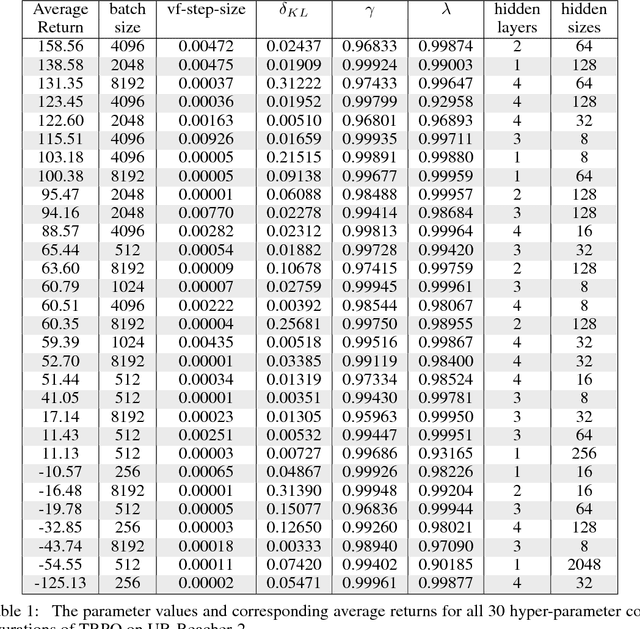
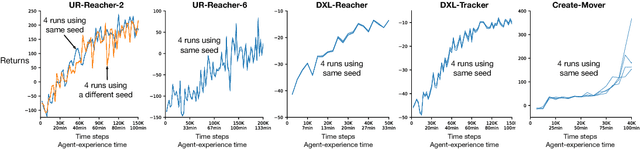
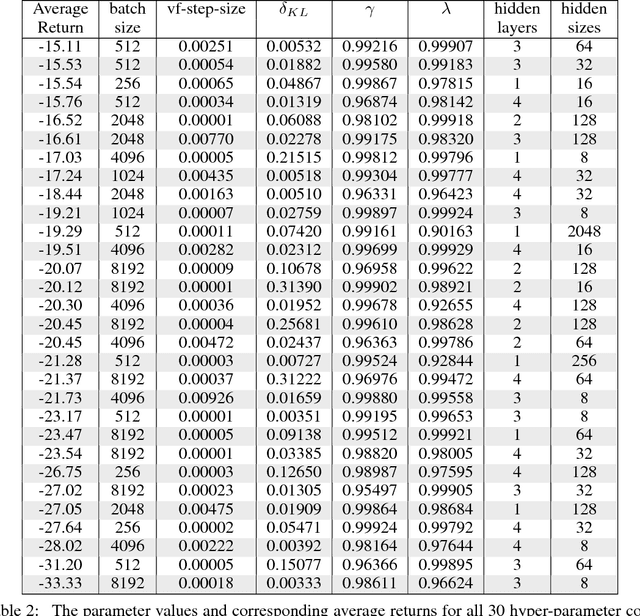
Through many recent successes in simulation, model-free reinforcement learning has emerged as a promising approach to solving continuous control robotic tasks. The research community is now able to reproduce, analyze and build quickly on these results due to open source implementations of learning algorithms and simulated benchmark tasks. To carry forward these successes to real-world applications, it is crucial to withhold utilizing the unique advantages of simulations that do not transfer to the real world and experiment directly with physical robots. However, reinforcement learning research with physical robots faces substantial resistance due to the lack of benchmark tasks and supporting source code. In this work, we introduce several reinforcement learning tasks with multiple commercially available robots that present varying levels of learning difficulty, setup, and repeatability. On these tasks, we test the learning performance of off-the-shelf implementations of four reinforcement learning algorithms and analyze sensitivity to their hyper-parameters to determine their readiness for applications in various real-world tasks. Our results show that with a careful setup of the task interface and computations, some of these implementations can be readily applicable to physical robots. We find that state-of-the-art learning algorithms are highly sensitive to their hyper-parameters and their relative ordering does not transfer across tasks, indicating the necessity of re-tuning them for each task for best performance. On the other hand, the best hyper-parameter configuration from one task may often result in effective learning on held-out tasks even with different robots, providing a reasonable default. We make the benchmark tasks publicly available to enhance reproducibility in real-world reinforcement learning.
Neurohex: A Deep Q-learning Hex Agent
Apr 26, 2016


DeepMind's recent spectacular success in using deep convolutional neural nets and machine learning to build superhuman level agents --- e.g. for Atari games via deep Q-learning and for the game of Go via Reinforcement Learning --- raises many questions, including to what extent these methods will succeed in other domains. In this paper we consider DQL for the game of Hex: after supervised initialization, we use selfplay to train NeuroHex, an 11-layer CNN that plays Hex on the 13x13 board. Hex is the classic two-player alternate-turn stone placement game played on a rhombus of hexagonal cells in which the winner is whomever connects their two opposing sides. Despite the large action and state space, our system trains a Q-network capable of strong play with no search. After two weeks of Q-learning, NeuroHex achieves win-rates of 20.4% as first player and 2.1% as second player against a 1-second/move version of MoHex, the current ICGA Olympiad Hex champion. Our data suggests further improvement might be possible with more training time.