 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Deep Reinforcement Learning in Continuing Tasks
Jan 12, 2025In reinforcement learning (RL), continuing tasks refer to tasks where the agent-environment interaction is ongoing and can not be broken down into episodes. These tasks are suitable when environment resets are unavailable, agent-controlled, or predefined but where all rewards-including those beyond resets-are critical. These scenarios frequently occur in real-world applications and can not be modeled by episodic tasks. While modern deep RL algorithms have been extensively studied and well understood in episodic tasks, their behavior in continuing tasks remains underexplored. To address this gap, we provide an empirical study of several well-known deep RL algorithms using a suite of continuing task testbeds based on Mujoco and Atari environments, highlighting several key insights concerning continuing tasks. Using these testbeds, we also investigate the effectiveness of a method for improving temporal-difference-based RL algorithms in continuing tasks by centering rewards, as introduced by Naik et al. (2024). While their work primarily focused on this method in conjunction with Q-learning, our results extend their findings by demonstrating that this method is effective across a broader range of algorithms, scales to larger tasks, and outperforms two other reward-centering approaches.
Pearl: A Production-ready Reinforcement Learning Agent
Dec 06, 2023



Reinforcement Learning (RL) offers a versatile framework for achieving long-term goals. Its generality allows us to formalize a wide range of problems that real-world intelligent systems encounter, such as dealing with delayed rewards, handling partial observability, addressing the exploration and exploitation dilemma, utilizing offline data to improve online performance, and ensuring safety constraints are met. Despite considerable progress made by the RL research community in addressing these issues, existing open-source RL libraries tend to focus on a narrow portion of the RL solution pipeline, leaving other aspects largely unattended. This paper introduces Pearl, a Production-ready RL agent software package explicitly designed to embrace these challenges in a modular fashion. In addition to presenting preliminary benchmark results, this paper highlights Pearl's industry adoptions to demonstrate its readiness for production usage. Pearl is open sourced on Github at github.com/facebookresearch/pearl and its official website is located at pearlagent.github.io.
Offline Reinforcement Learning for Optimizing Production Bidding Policies
Oct 13, 2023The online advertising market, with its thousands of auctions run per second, presents a daunting challenge for advertisers who wish to optimize their spend under a budget constraint. Thus, advertising platforms typically provide automated agents to their customers, which act on their behalf to bid for impression opportunities in real time at scale. Because these proxy agents are owned by the platform but use advertiser funds to operate, there is a strong practical need to balance reliability and explainability of the agent with optimizing power. We propose a generalizable approach to optimizing bidding policies in production environments by learning from real data using offline reinforcement learning. This approach can be used to optimize any differentiable base policy (practically, a heuristic policy based on principles which the advertiser can easily understand), and only requires data generated by the base policy itself. We use a hybrid agent architecture that combines arbitrary base policies with deep neural networks, where only the optimized base policy parameters are eventually deployed, and the neural network part is discarded after training. We demonstrate that such an architecture achieves statistically significant performance gains in both simulated and at-scale production bidding environments. Our approach does not incur additional infrastructure, safety, or explainability costs, as it directly optimizes parameters of existing production routines without replacing them with black box-style models like neural networks.
Optimizing Long-term Value for Auction-Based Recommender Systems via On-Policy Reinforcement Learning
May 24, 2023Auction-based recommender systems are prevalent in online advertising platforms, but they are typically optimized to allocate recommendation slots based on immediate expected return metrics, neglecting the downstream effects of recommendations on user behavior. In this study, we employ reinforcement learning to optimize for long-term return metrics in an auction-based recommender system. Utilizing temporal difference learning, a fundamental reinforcement learning algorithm, we implement an one-step policy improvement approach that biases the system towards recommendations with higher long-term user engagement metrics. This optimizes value over long horizons while maintaining compatibility with the auction framework. Our approach is grounded in dynamic programming ideas which show that our method provably improves upon the existing auction-based base policy. Through an online A/B test conducted on an auction-based recommender system which handles billions of impressions and users daily, we empirically establish that our proposed method outperforms the current production system in terms of long-term user engagement metrics.
Autoregressive Policies for Continuous Control Deep Reinforcement Learning
Mar 27, 2019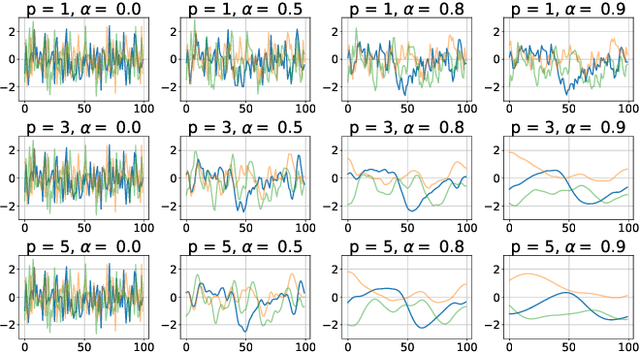
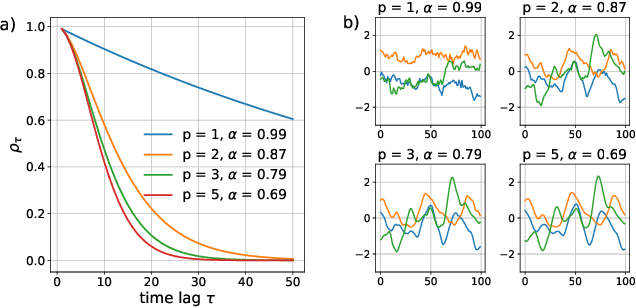
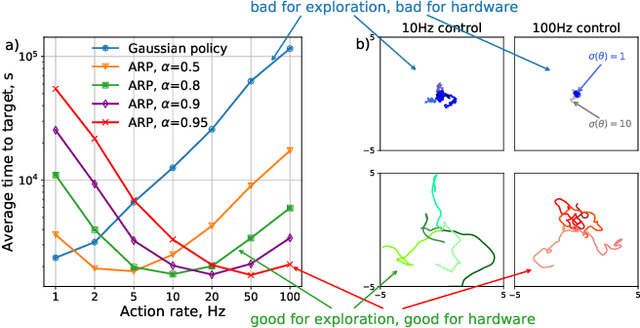
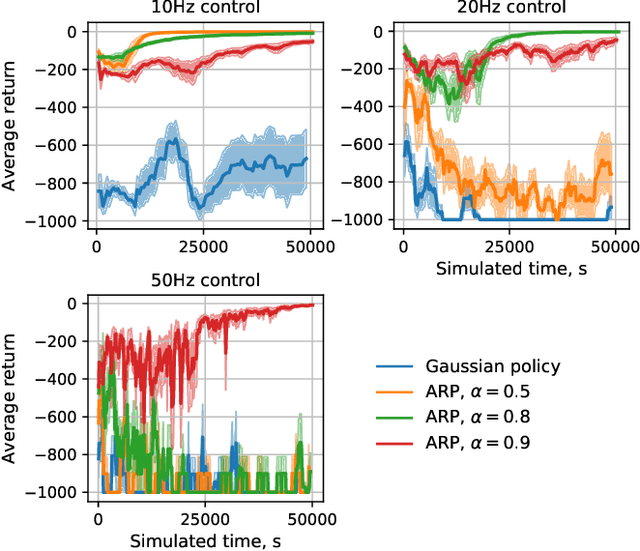
Reinforcement learning algorithms rely on exploration to discover new behaviors, which is typically achieved by following a stochastic policy. In continuous control tasks, policies with a Gaussian distribution have been widely adopted. Gaussian exploration however does not result in smooth trajectories that generally correspond to safe and rewarding behaviors in practical tasks. In addition, Gaussian policies do not result in an effective exploration of an environment and become increasingly inefficient as the action rate increases. This contributes to a low sample efficiency often observed in learning continuous control tasks. We introduce a family of stationary autoregressive (AR) stochastic processes to facilitate exploration in continuous control domains. We show that proposed processes possess two desirable features: subsequent process observations are temporally coherent with continuously adjustable degree of coherence, and the process stationary distribution is standard normal. We derive an autoregressive policy (ARP) that implements such processes maintaining the standard agent-environment interface. We show how ARPs can be easily used with the existing off-the-shelf learning algorithms. Empirically we demonstrate that using ARPs results in improved exploration and sample efficiency in both simulated and real world domains, and, furthermore, provides smooth exploration trajectories that enable safe operation of robotic hardware.
Benchmarking Reinforcement Learning Algorithms on Real-World Robots
Sep 20, 2018
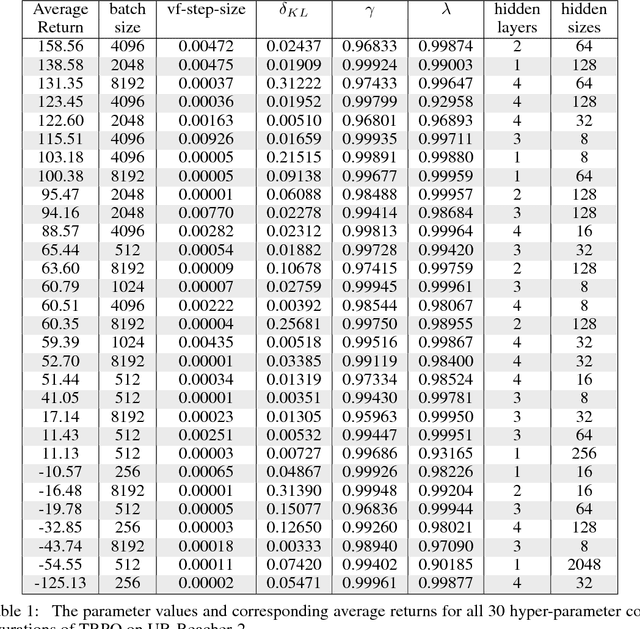
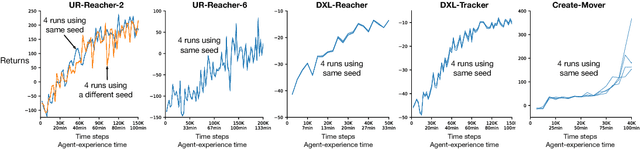
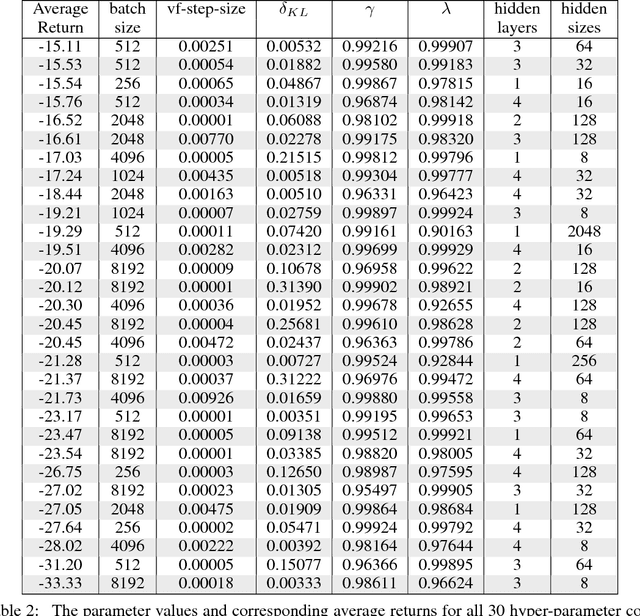
Through many recent successes in simulation, model-free reinforcement learning has emerged as a promising approach to solving continuous control robotic tasks. The research community is now able to reproduce, analyze and build quickly on these results due to open source implementations of learning algorithms and simulated benchmark tasks. To carry forward these successes to real-world applications, it is crucial to withhold utilizing the unique advantages of simulations that do not transfer to the real world and experiment directly with physical robots. However, reinforcement learning research with physical robots faces substantial resistance due to the lack of benchmark tasks and supporting source code. In this work, we introduce several reinforcement learning tasks with multiple commercially available robots that present varying levels of learning difficulty, setup, and repeatability. On these tasks, we test the learning performance of off-the-shelf implementations of four reinforcement learning algorithms and analyze sensitivity to their hyper-parameters to determine their readiness for applications in various real-world tasks. Our results show that with a careful setup of the task interface and computations, some of these implementations can be readily applicable to physical robots. We find that state-of-the-art learning algorithms are highly sensitive to their hyper-parameters and their relative ordering does not transfer across tasks, indicating the necessity of re-tuning them for each task for best performance. On the other hand, the best hyper-parameter configuration from one task may often result in effective learning on held-out tasks even with different robots, providing a reasonable default. We make the benchmark tasks publicly available to enhance reproducibility in real-world reinforcement learning.
Setting up a Reinforcement Learning Task with a Real-World Robot
Mar 19, 2018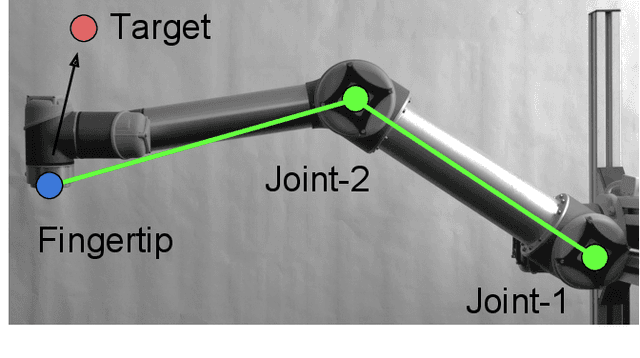
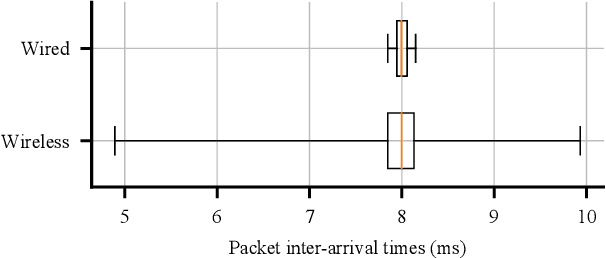

Reinforcement learning is a promising approach to developing hard-to-engineer adaptive solutions for complex and diverse robotic tasks. However, learning with real-world robots is often unreliable and difficult, which resulted in their low adoption in reinforcement learning research. This difficulty is worsened by the lack of guidelines for setting up learning tasks with robots. In this work, we develop a learning task with a UR5 robotic arm to bring to light some key elements of a task setup and study their contributions to the challenges with robots. We find that learning performance can be highly sensitive to the setup, and thus oversights and omissions in setup details can make effective learning, reproducibility, and fair comparison hard. Our study suggests some mitigating steps to help future experimenters avoid difficulties and pitfalls. We show that highly reliable and repeatable experiments can be performed in our setup, indicating the possibility of reinforcement learning research extensively based on real-world robots.
Benchmarking Quantum Hardware for Training of Fully Visible Boltzmann Machines
Nov 14, 2016
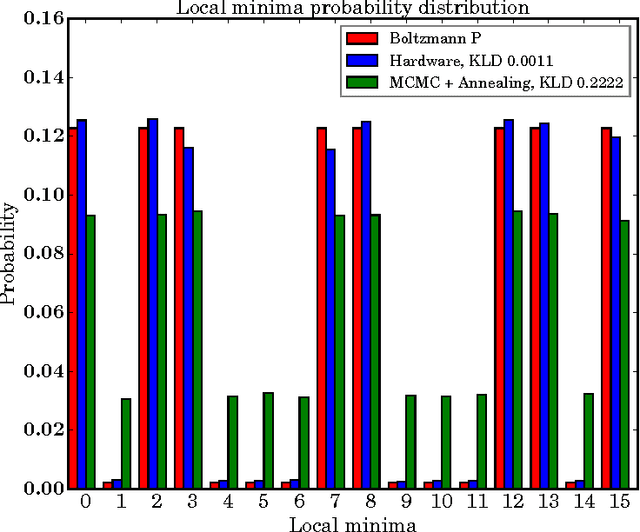
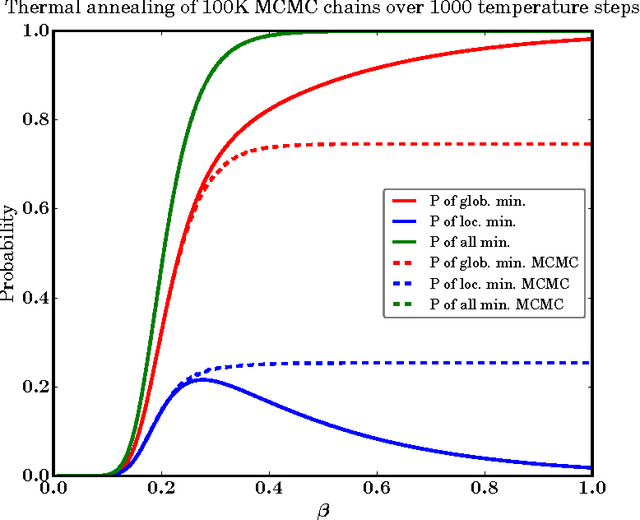
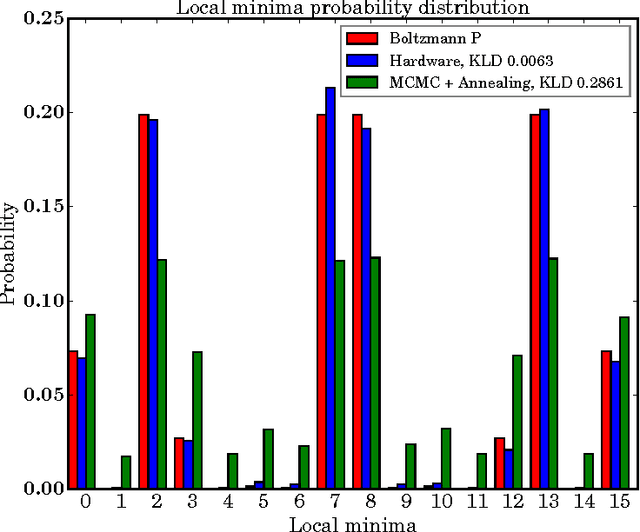
Quantum annealing (QA) is a hardware-based heuristic optimization and sampling method applicable to discrete undirected graphical models. While similar to simulated annealing, QA relies on quantum, rather than thermal, effects to explore complex search spaces. For many classes of problems, QA is known to offer computational advantages over simulated annealing. Here we report on the ability of recent QA hardware to accelerate training of fully visible Boltzmann machines. We characterize the sampling distribution of QA hardware, and show that in many cases, the quantum distributions differ significantly from classical Boltzmann distributions. In spite of this difference, training (which seeks to match data and model statistics) using standard classical gradient updates is still effective. We investigate the use of QA for seeding Markov chains as an alternative to contrastive divergence (CD) and persistent contrastive divergence (PCD). Using $k=50$ Gibbs steps, we show that for problems with high-energy barriers between modes, QA-based seeds can improve upon chains with CD and PCD initializations. For these hard problems, QA gradient estimates are more accurate, and allow for faster learning. Furthermore, and interestingly, even the case of raw QA samples (that is, $k=0$) achieved similar improvements. We argue that this relates to the fact that we are training a quantum rather than classical Boltzmann distribution in this case. The learned parameters give rise to hardware QA distributions closely approximating classical Boltzmann distributions that are hard to train with CD/PCD.