 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Multimodal Learning for Tumor Protein-Metal Binding: Progress, Challenges, and Perspectives
Apr 04, 2025In cancer therapeutics, protein-metal binding mechanisms critically govern drug pharmacokinetics and targeting efficacy, thereby fundamentally shaping the rational design of anticancer metallodrugs. While conventional laboratory methods used to study such mechanisms are often costly, low throughput, and limited in capturing dynamic biological processes, machine learning (ML) has emerged as a promising alternative. Despite increasing efforts to develop protein-metal binding datasets and ML algorithms, the application of ML in tumor protein-metal binding remains limited. Key challenges include a shortage of high-quality, tumor-specific datasets, insufficient consideration of multiple data modalities, and the complexity of interpreting results due to the ''black box'' nature of complex ML models. This paper summarizes recent progress and ongoing challenges in using ML to predict tumor protein-metal binding, focusing on data, modeling, and interpretability. We present multimodal protein-metal binding datasets and outline strategies for acquiring, curating, and preprocessing them for training ML models. Moreover, we explore the complementary value provided by different data modalities and examine methods for their integration. We also review approaches for improving model interpretability to support more trustworthy decisions in cancer research. Finally, we offer our perspective on research opportunities and propose strategies to address the scarcity of tumor protein data and the limited number of predictive models for tumor protein-metal binding. We also highlight two promising directions for effective metal-based drug design: integrating protein-protein interaction data to provide structural insights into metal-binding events and predicting structural changes in tumor proteins after metal binding.
An Empirical Study of Deep Reinforcement Learning in Continuing Tasks
Jan 12, 2025In reinforcement learning (RL), continuing tasks refer to tasks where the agent-environment interaction is ongoing and can not be broken down into episodes. These tasks are suitable when environment resets are unavailable, agent-controlled, or predefined but where all rewards-including those beyond resets-are critical. These scenarios frequently occur in real-world applications and can not be modeled by episodic tasks. While modern deep RL algorithms have been extensively studied and well understood in episodic tasks, their behavior in continuing tasks remains underexplored. To address this gap, we provide an empirical study of several well-known deep RL algorithms using a suite of continuing task testbeds based on Mujoco and Atari environments, highlighting several key insights concerning continuing tasks. Using these testbeds, we also investigate the effectiveness of a method for improving temporal-difference-based RL algorithms in continuing tasks by centering rewards, as introduced by Naik et al. (2024). While their work primarily focused on this method in conjunction with Q-learning, our results extend their findings by demonstrating that this method is effective across a broader range of algorithms, scales to larger tasks, and outperforms two other reward-centering approaches.
Exploiting Structure in Offline Multi-Agent RL: The Benefits of Low Interaction Rank
Oct 01, 2024We study the problem of learning an approximate equilibrium in the offline multi-agent reinforcement learning (MARL) setting. We introduce a structural assumption -- the interaction rank -- and establish that functions with low interaction rank are significantly more robust to distribution shift compared to general ones. Leveraging this observation, we demonstrate that utilizing function classes with low interaction rank, when combined with regularization and no-regret learning, admits decentralized, computationally and statistically efficient learning in offline MARL. Our theoretical results are complemented by experiments that showcase the potential of critic architectures with low interaction rank in offline MARL, contrasting with commonly used single-agent value decomposition architectures.
Uncertainty of Joint Neural Contextual Bandit
Jun 04, 2024Contextual bandit learning is increasingly favored in modern large-scale recommendation systems. To better utlize the contextual information and available user or item features, the integration of neural networks have been introduced to enhance contextual bandit learning and has triggered significant interest from both academia and industry. However, a major challenge arises when implementing a disjoint neural contextual bandit solution in large-scale recommendation systems, where each item or user may correspond to a separate bandit arm. The huge number of items to recommend poses a significant hurdle for real world production deployment. This paper focuses on a joint neural contextual bandit solution which serves all recommending items in one single model. The output consists of a predicted reward $\mu$, an uncertainty $\sigma$ and a hyper-parameter $\alpha$ which balances exploitation and exploration, e.g., $\mu + \alpha \sigma$. The tuning of the parameter $\alpha$ is typically heuristic and complex in practice due to its stochastic nature. To address this challenge, we provide both theoretical analysis and experimental findings regarding the uncertainty $\sigma$ of the joint neural contextual bandit model. Our analysis reveals that $\alpha$ demonstrates an approximate square root relationship with the size of the last hidden layer $F$ and inverse square root relationship with the amount of training data $N$, i.e., $\sigma \propto \sqrt{\frac{F}{N}}$. The experiments, conducted with real industrial data, align with the theoretical analysis, help understanding model behaviors and assist the hyper-parameter tuning during both offline training and online deployment.
Pearl: A Production-ready Reinforcement Learning Agent
Dec 06, 2023



Reinforcement Learning (RL) offers a versatile framework for achieving long-term goals. Its generality allows us to formalize a wide range of problems that real-world intelligent systems encounter, such as dealing with delayed rewards, handling partial observability, addressing the exploration and exploitation dilemma, utilizing offline data to improve online performance, and ensuring safety constraints are met. Despite considerable progress made by the RL research community in addressing these issues, existing open-source RL libraries tend to focus on a narrow portion of the RL solution pipeline, leaving other aspects largely unattended. This paper introduces Pearl, a Production-ready RL agent software package explicitly designed to embrace these challenges in a modular fashion. In addition to presenting preliminary benchmark results, this paper highlights Pearl's industry adoptions to demonstrate its readiness for production usage. Pearl is open sourced on Github at github.com/facebookresearch/pearl and its official website is located at pearlagent.github.io.
Non-Stationary Contextual Bandit Learning via Neural Predictive Ensemble Sampling
Oct 14, 2023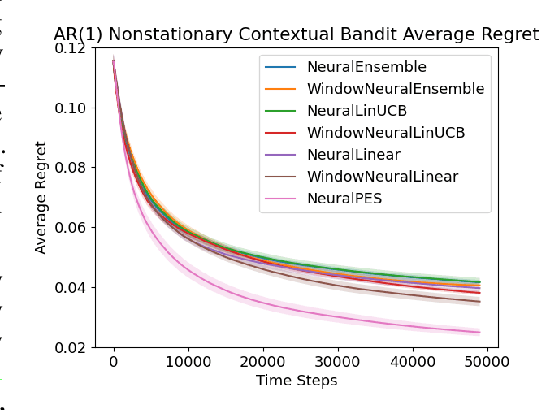
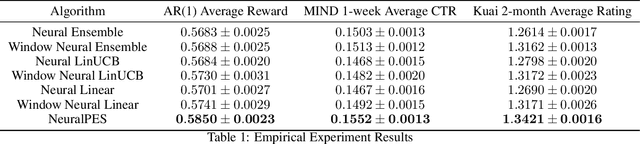


Real-world applications of contextual bandits often exhibit non-stationarity due to seasonality, serendipity, and evolving social trends. While a number of non-stationary contextual bandit learning algorithms have been proposed in the literature, they excessively explore due to a lack of prioritization for information of enduring value, or are designed in ways that do not scale in modern applications with high-dimensional user-specific features and large action set, or both. In this paper, we introduce a novel non-stationary contextual bandit algorithm that addresses these concerns. It combines a scalable, deep-neural-network-based architecture with a carefully designed exploration mechanism that strategically prioritizes collecting information with the most lasting value in a non-stationary environment. Through empirical evaluations on two real-world recommendation datasets, which exhibit pronounced non-stationarity, we demonstrate that our approach significantly outperforms the state-of-the-art baselines.
Offline Reinforcement Learning for Optimizing Production Bidding Policies
Oct 13, 2023The online advertising market, with its thousands of auctions run per second, presents a daunting challenge for advertisers who wish to optimize their spend under a budget constraint. Thus, advertising platforms typically provide automated agents to their customers, which act on their behalf to bid for impression opportunities in real time at scale. Because these proxy agents are owned by the platform but use advertiser funds to operate, there is a strong practical need to balance reliability and explainability of the agent with optimizing power. We propose a generalizable approach to optimizing bidding policies in production environments by learning from real data using offline reinforcement learning. This approach can be used to optimize any differentiable base policy (practically, a heuristic policy based on principles which the advertiser can easily understand), and only requires data generated by the base policy itself. We use a hybrid agent architecture that combines arbitrary base policies with deep neural networks, where only the optimized base policy parameters are eventually deployed, and the neural network part is discarded after training. We demonstrate that such an architecture achieves statistically significant performance gains in both simulated and at-scale production bidding environments. Our approach does not incur additional infrastructure, safety, or explainability costs, as it directly optimizes parameters of existing production routines without replacing them with black box-style models like neural networks.
Scalable Neural Contextual Bandit for Recommender Systems
Jun 26, 2023High-quality recommender systems ought to deliver both innovative and relevant content through effective and exploratory interactions with users. Yet, supervised learning-based neural networks, which form the backbone of many existing recommender systems, only leverage recognized user interests, falling short when it comes to efficiently uncovering unknown user preferences. While there has been some progress with neural contextual bandit algorithms towards enabling online exploration through neural networks, their onerous computational demands hinder widespread adoption in real-world recommender systems. In this work, we propose a scalable sample-efficient neural contextual bandit algorithm for recommender systems. To do this, we design an epistemic neural network architecture, Epistemic Neural Recommendation (ENR), that enables Thompson sampling at a large scale. In two distinct large-scale experiments with real-world tasks, ENR significantly boosts click-through rates and user ratings by at least 9% and 6% respectively compared to state-of-the-art neural contextual bandit algorithms. Furthermore, it achieves equivalent performance with at least 29% fewer user interactions compared to the best-performing baseline algorithm. Remarkably, while accomplishing these improvements, ENR demands orders of magnitude fewer computational resources than neural contextual bandit baseline algorithms.
IQL-TD-MPC: Implicit Q-Learning for Hierarchical Model Predictive Control
Jun 01, 2023Model-based reinforcement learning (RL) has shown great promise due to its sample efficiency, but still struggles with long-horizon sparse-reward tasks, especially in offline settings where the agent learns from a fixed dataset. We hypothesize that model-based RL agents struggle in these environments due to a lack of long-term planning capabilities, and that planning in a temporally abstract model of the environment can alleviate this issue. In this paper, we make two key contributions: 1) we introduce an offline model-based RL algorithm, IQL-TD-MPC, that extends the state-of-the-art Temporal Difference Learning for Model Predictive Control (TD-MPC) with Implicit Q-Learning (IQL); 2) we propose to use IQL-TD-MPC as a Manager in a hierarchical setting with any off-the-shelf offline RL algorithm as a Worker. More specifically, we pre-train a temporally abstract IQL-TD-MPC Manager to predict "intent embeddings", which roughly correspond to subgoals, via planning. We empirically show that augmenting state representations with intent embeddings generated by an IQL-TD-MPC manager significantly improves off-the-shelf offline RL agents' performance on some of the most challenging D4RL benchmark tasks. For instance, the offline RL algorithms AWAC, TD3-BC, DT, and CQL all get zero or near-zero normalized evaluation scores on the medium and large antmaze tasks, while our modification gives an average score over 40.
Optimizing Long-term Value for Auction-Based Recommender Systems via On-Policy Reinforcement Learning
May 24, 2023Auction-based recommender systems are prevalent in online advertising platforms, but they are typically optimized to allocate recommendation slots based on immediate expected return metrics, neglecting the downstream effects of recommendations on user behavior. In this study, we employ reinforcement learning to optimize for long-term return metrics in an auction-based recommender system. Utilizing temporal difference learning, a fundamental reinforcement learning algorithm, we implement an one-step policy improvement approach that biases the system towards recommendations with higher long-term user engagement metrics. This optimizes value over long horizons while maintaining compatibility with the auction framework. Our approach is grounded in dynamic programming ideas which show that our method provably improves upon the existing auction-based base policy. Through an online A/B test conducted on an auction-based recommender system which handles billions of impressions and users daily, we empirically establish that our proposed method outperforms the current production system in terms of long-term user engagement metrics.