 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComMem: Complementary Memory Systems for Test-Time Adaptation of Vision-Language Models
Jun 27, 2026Test-time adaptation (TTA) of vision-language models (VLMs) is essential for their robust deployment in dynamic, real-world environments. However, existing TTA methods often adapt locally without accumulating knowledge over time, or operating within a single modality without exploiting VLMs' inherently multi-modal nature. Inspired by the \textbf{Com}plementary \textbf{Mem}ory systems of the biological brain, we propose \textbf{ComMem}, an innovative approach that mimics the distinct but cooperative roles of the hippocampus and neocortex to enable effective TTA for VLMs. ComMem consists of two key components: a fast-adapting detailed memory, akin to the hippocampus, that forms a dynamic visual cache from high-confidence test samples; and a slow-integrating abstract memory, akin to the neocortex, that continually refines global textual prototypes. For each test instance, ComMem jointly optimizes both memory systems to ensure cross-modal consistency. Extensive experiments on 15 benchmark datasets show that ComMem significantly outperforms state-of-the-art methods under both natural distribution shifts and cross-dataset generalization, offering a promising direction for enhancing VLMs' practical adaptability.
Modular Memory is the Key to Continual Learning Agents
Mar 02, 2026Foundation models have transformed machine learning through large-scale pretraining and increased test-time compute. Despite surpassing human performance in several domains, these models remain fundamentally limited in continuous operation, experience accumulation, and personalization, capabilities that are central to adaptive intelligence. While continual learning research has long targeted these goals, its historical focus on in-weight learning (IWL), i.e., updating a single model's parameters to absorb new knowledge, has rendered catastrophic forgetting a persistent challenge. Our position is that combining the strengths of In-Weight Learning (IWL) and the newly emerged capabilities of In-Context Learning (ICL) through the design of modular memory is the missing piece for continual adaptation at scale. We outline a conceptual framework for modular memory-centric architectures that leverage ICL for rapid adaptation and knowledge accumulation, and IWL for stable updates to model capabilities, charting a practical roadmap toward continually learning agents.
BriMA: Bridged Modality Adaptation for Multi-Modal Continual Action Quality Assessment
Feb 22, 2026Action Quality Assessment (AQA) aims to score how well an action is performed and is widely used in sports analysis, rehabilitation assessment, and human skill evaluation. Multi-modal AQA has recently achieved strong progress by leveraging complementary visual and kinematic cues, yet real-world deployments often suffer from non-stationary modality imbalance, where certain modalities become missing or intermittently available due to sensor failures or annotation gaps. Existing continual AQA methods overlook this issue and assume that all modalities remain complete and stable throughout training, which restricts their practicality. To address this challenge, we introduce Bridged Modality Adaptation (BriMA), an innovative approach to multi-modal continual AQA under modality-missing conditions. BriMA consists of a memory-guided bridging imputation module that reconstructs missing modalities using both task-agnostic and task-specific representations, and a modality-aware replay mechanism that prioritizes informative samples based on modality distortion and distribution drift. Experiments on three representative multi-modal AQA datasets (RG, Fis-V, and FS1000) show that BriMA consistently improves performance under different modality-missing conditions, achieving 6--8\% higher correlation and 12--15\% lower error on average. These results demonstrate a step toward robust multi-modal AQA systems under real-world deployment constraints.
MePo: Meta Post-Refinement for Rehearsal-Free General Continual Learnin
Feb 08, 2026To cope with uncertain changes of the external world, intelligent systems must continually learn from complex, evolving environments and respond in real time. This ability, collectively known as general continual learning (GCL), encapsulates practical challenges such as online datastreams and blurry task boundaries. Although leveraging pretrained models (PTMs) has greatly advanced conventional continual learning (CL), these methods remain limited in reconciling the diverse and temporally mixed information along a single pass, resulting in sub-optimal GCL performance. Inspired by meta-plasticity and reconstructive memory in neuroscience, we introduce here an innovative approach named Meta Post-Refinement (MePo) for PTMs-based GCL. This approach constructs pseudo task sequences from pretraining data and develops a bi-level meta-learning paradigm to refine the pretrained backbone, which serves as a prolonged pretraining phase but greatly facilitates rapid adaptation of representation learning to downstream GCL tasks. MePo further initializes a meta covariance matrix as the reference geometry of pretrained representation space, enabling GCL to exploit second-order statistics for robust output alignment. MePo serves as a plug-in strategy that achieves significant performance gains across a variety of GCL benchmarks and pretrained checkpoints in a rehearsal-free manner (e.g., 15.10\%, 13.36\%, and 12.56\% on CIFAR-100, ImageNet-R, and CUB-200 under Sup-21/1K). Our source code is available at \href{https://github.com/SunGL001/MePo}{MePo}
Safety Alignment as Continual Learning: Mitigating the Alignment Tax via Orthogonal Gradient Projection
Feb 08, 2026Large Language Models (LLMs) often incur an alignment tax: safety post-training can reduce general utility (e.g., reasoning and coding). We argue that this tax primarily arises from continual-learning-style forgetting in sequential alignment, where distribution shift and conflicting objectives cause safety updates to overwrite pre-trained competencies. Accordingly, we cast safety alignment as a continual learning (CL) problem that must balance plasticity (acquiring safety constraints) and stability (preserving general abilities). We propose Orthogonal Gradient Projection for Safety Alignment (OGPSA), a lightweight method that mitigates interference by constraining each safety update to be orthogonal (in a first-order sense) to a learned subspace capturing general capabilities. Specifically, OGPSA estimates a low-rank capability subspace from gradients on a small reference set and projects the safety gradient onto its orthogonal complement before updating. This produces safety-directed updates that minimally perturb prior knowledge while retaining capacity for alignment. OGPSA is plug-and-play and integrates into standard post-training pipelines without large-scale replay, auxiliary objectives, or retraining. Across Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and sequential SFT$\rightarrow$DPO settings, OGPSA consistently improves the safety--utility Pareto frontier over standard baselines. For instance, on Qwen2.5-7B-Instruct under SFT$\rightarrow$DPO, OGPSA preserves strong safety while recovering general capability, improving SimpleQA from 0.53\% to 3.03\% and IFEval from 51.94\% to 63.96\%. Our source code is available at \href{https://github.com/SunGL001/OGPSA}{OGPSA}
FlyPrompt: Brain-Inspired Random-Expanded Routing with Temporal-Ensemble Experts for General Continual Learning
Feb 03, 2026General continual learning (GCL) challenges intelligent systems to learn from single-pass, non-stationary data streams without clear task boundaries. While recent advances in continual parameter-efficient tuning (PET) of pretrained models show promise, they typically rely on multiple training epochs and explicit task cues, limiting their effectiveness in GCL scenarios. Moreover, existing methods often lack targeted design and fail to address two fundamental challenges in continual PET: how to allocate expert parameters to evolving data distributions, and how to improve their representational capacity under limited supervision. Inspired by the fruit fly's hierarchical memory system characterized by sparse expansion and modular ensembles, we propose FlyPrompt, a brain-inspired framework that decomposes GCL into two subproblems: expert routing and expert competence improvement. FlyPrompt introduces a randomly expanded analytic router for instance-level expert activation and a temporal ensemble of output heads to dynamically adapt decision boundaries over time. Extensive theoretical and empirical evaluations demonstrate FlyPrompt's superior performance, achieving up to 11.23%, 12.43%, and 7.62% gains over state-of-the-art baselines on CIFAR-100, ImageNet-R, and CUB-200, respectively. Our source code is available at https://github.com/AnAppleCore/FlyGCL.
PACE: Pretrained Audio Continual Learning
Feb 03, 2026Audio is a fundamental modality for analyzing speech, music, and environmental sounds. Although pretrained audio models have significantly advanced audio understanding, they remain fragile in real-world settings where data distributions shift over time. In this work, we present the first systematic benchmark for audio continual learning (CL) with pretrained models (PTMs), together with a comprehensive analysis of its unique challenges. Unlike in vision, where parameter-efficient fine-tuning (PEFT) has proven effective for CL, directly transferring such strategies to audio leads to poor performance. This stems from a fundamental property of audio backbones: they focus on low-level spectral details rather than structured semantics, causing severe upstream-downstream misalignment. Through extensive empirical study, we identify analytic classifiers with first-session adaptation (FSA) as a promising direction, but also reveal two major limitations: representation saturation in coarse-grained scenarios and representation drift in fine-grained scenarios. To address these challenges, we propose PACE, a novel method that enhances FSA via a regularized analytic classifier and enables multi-session adaptation through adaptive subspace-orthogonal PEFT for improved semantic alignment. In addition, we introduce spectrogram-based boundary-aware perturbations to mitigate representation overlap and improve stability. Experiments on six diverse audio CL benchmarks demonstrate that PACE substantially outperforms state-of-the-art baselines, marking an important step toward robust and scalable audio continual learning with PTMs.
Continual Action Quality Assessment via Adaptive Manifold-Aligned Graph Regularization
Oct 08, 2025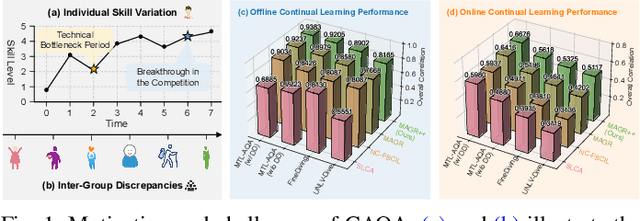
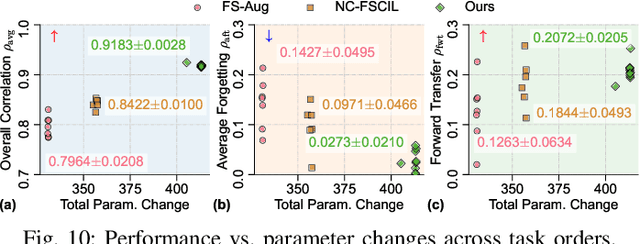
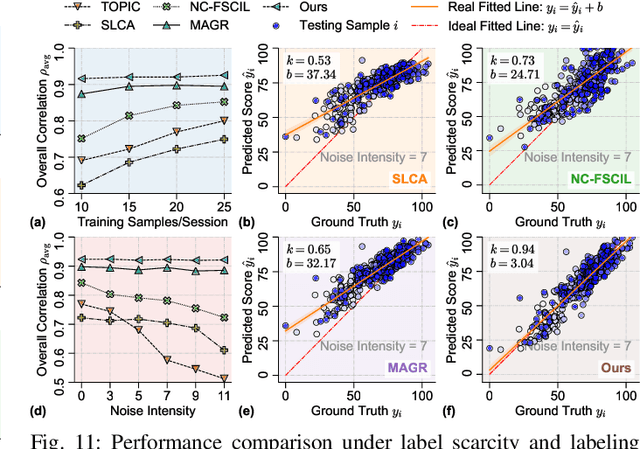
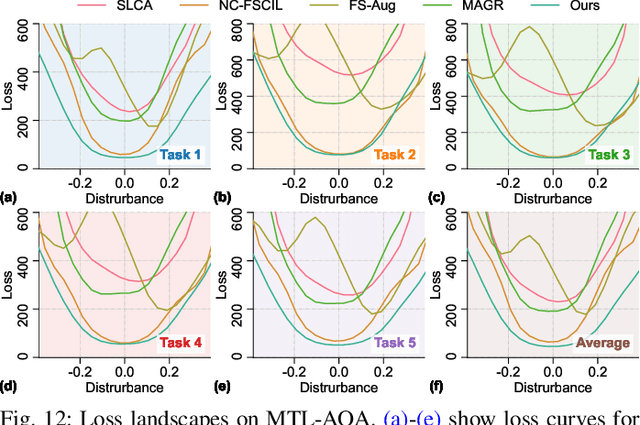
Action Quality Assessment (AQA) quantifies human actions in videos, supporting applications in sports scoring, rehabilitation, and skill evaluation. A major challenge lies in the non-stationary nature of quality distributions in real-world scenarios, which limits the generalization ability of conventional methods. We introduce Continual AQA (CAQA), which equips AQA with Continual Learning (CL) capabilities to handle evolving distributions while mitigating catastrophic forgetting. Although parameter-efficient fine-tuning of pretrained models has shown promise in CL for image classification, we find it insufficient for CAQA. Our empirical and theoretical analyses reveal two insights: (i) Full-Parameter Fine-Tuning (FPFT) is necessary for effective representation learning; yet (ii) uncontrolled FPFT induces overfitting and feature manifold shift, thereby aggravating forgetting. To address this, we propose Adaptive Manifold-Aligned Graph Regularization (MAGR++), which couples backbone fine-tuning that stabilizes shallow layers while adapting deeper ones with a two-step feature rectification pipeline: a manifold projector to translate deviated historical features into the current representation space, and a graph regularizer to align local and global distributions. We construct four CAQA benchmarks from three datasets with tailored evaluation protocols and strong baselines, enabling systematic cross-dataset comparison. Extensive experiments show that MAGR++ achieves state-of-the-art performance, with average correlation gains of 3.6% offline and 12.2% online over the strongest baseline, confirming its robustness and effectiveness. Our code is available at https://github.com/ZhouKanglei/MAGRPP.
From reactive to cognitive: brain-inspired spatial intelligence for embodied agents
Aug 24, 2025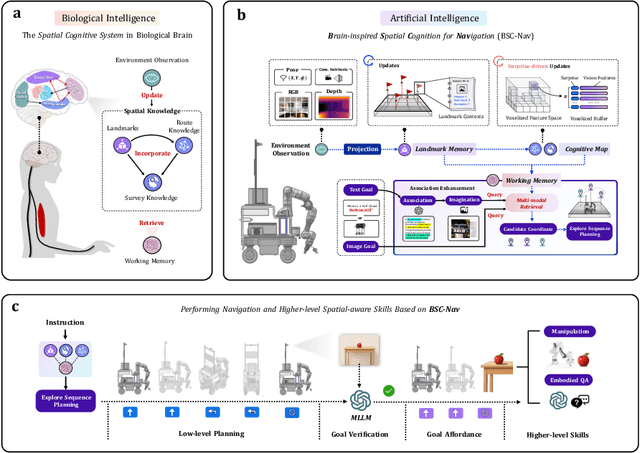
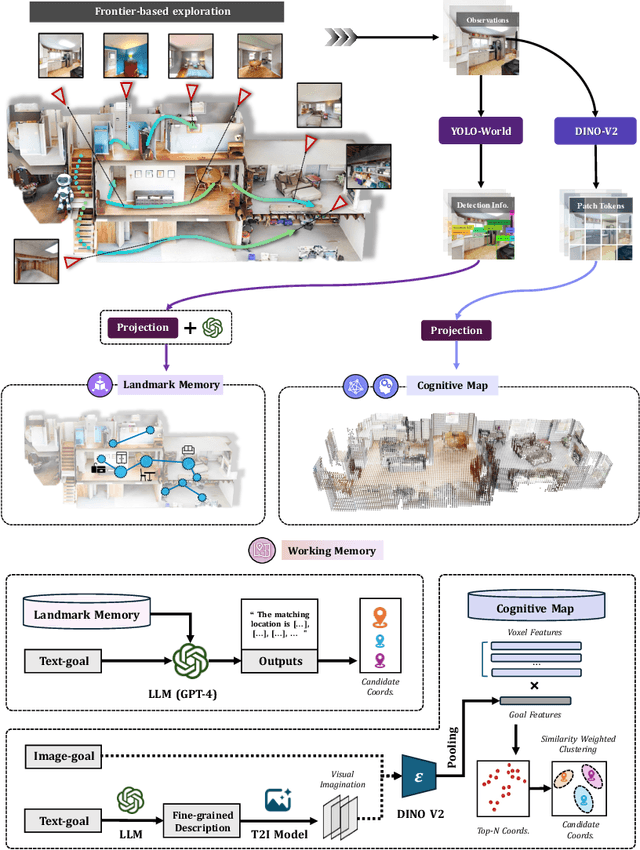
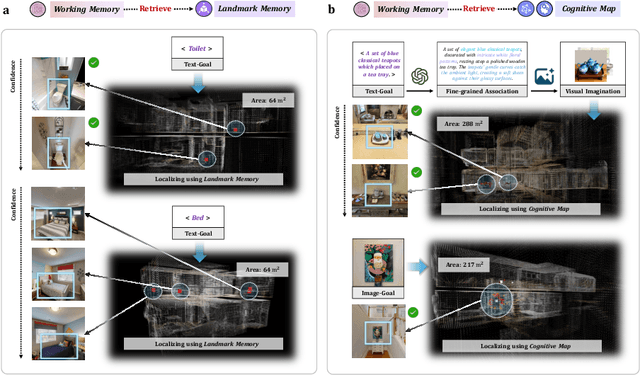
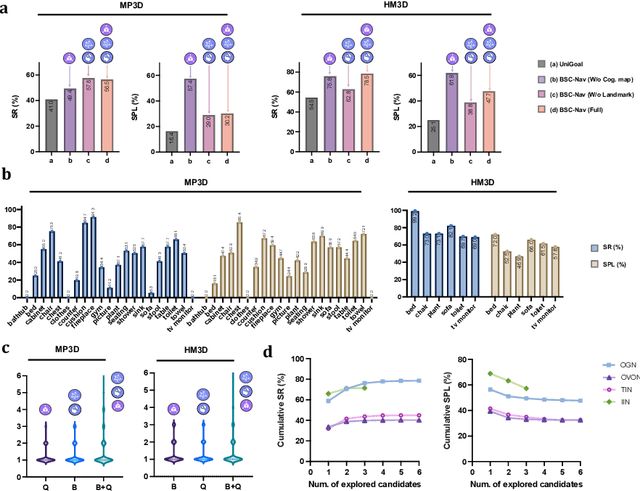
Spatial cognition enables adaptive goal-directed behavior by constructing internal models of space. Robust biological systems consolidate spatial knowledge into three interconnected forms: \textit{landmarks} for salient cues, \textit{route knowledge} for movement trajectories, and \textit{survey knowledge} for map-like representations. While recent advances in multi-modal large language models (MLLMs) have enabled visual-language reasoning in embodied agents, these efforts lack structured spatial memory and instead operate reactively, limiting their generalization and adaptability in complex real-world environments. Here we present Brain-inspired Spatial Cognition for Navigation (BSC-Nav), a unified framework for constructing and leveraging structured spatial memory in embodied agents. BSC-Nav builds allocentric cognitive maps from egocentric trajectories and contextual cues, and dynamically retrieves spatial knowledge aligned with semantic goals. Integrated with powerful MLLMs, BSC-Nav achieves state-of-the-art efficacy and efficiency across diverse navigation tasks, demonstrates strong zero-shot generalization, and supports versatile embodied behaviors in the real physical world, offering a scalable and biologically grounded path toward general-purpose spatial intelligence.
Versatile Cardiovascular Signal Generation with a Unified Diffusion Transformer
May 28, 2025Cardiovascular signals such as photoplethysmography (PPG), electrocardiography (ECG), and blood pressure (BP) are inherently correlated and complementary, together reflecting the health of cardiovascular system. However, their joint utilization in real-time monitoring is severely limited by diverse acquisition challenges from noisy wearable recordings to burdened invasive procedures. Here we propose UniCardio, a multi-modal diffusion transformer that reconstructs low-quality signals and synthesizes unrecorded signals in a unified generative framework. Its key innovations include a specialized model architecture to manage the signal modalities involved in generation tasks and a continual learning paradigm to incorporate varying modality combinations. By exploiting the complementary nature of cardiovascular signals, UniCardio clearly outperforms recent task-specific baselines in signal denoising, imputation, and translation. The generated signals match the performance of ground-truth signals in detecting abnormal health conditions and estimating vital signs, even in unseen domains, while ensuring interpretability for human experts. These advantages position UniCardio as a promising avenue for advancing AI-assisted healthcare.