 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMS-CAVP: Improving Audio-Video Correspondence with Multi-Scale Contrastive and Generative Pretraining
Jan 27, 2026Recent advances in video-audio (V-A) understanding and generation have increasingly relied on joint V-A embeddings, which serve as the foundation for tasks such as cross-modal retrieval and generation. While prior methods like CAVP effectively model semantic and temporal correspondences between modalities using contrastive objectives, their performance remains suboptimal. A key limitation is the insufficient modeling of the dense, multi-scale nature of both video and audio signals, correspondences often span fine- to coarse-grained spatial-temporal structures, which are underutilized in existing frameworks. To this end, we propose GMS-CAVP, a novel framework that combines Multi-Scale Video-Audio Alignment and Multi-Scale Spatial-Temporal Diffusion-based pretraining objectives to enhance V-A correspondence modeling. First, GMS-CAVP introduces a multi-scale contrastive learning strategy that captures semantic and temporal relations across varying granularities. Second, we go beyond traditional contrastive learning by incorporating a diffusion-based generative objective, enabling modality translation and synthesis between video and audio. This unified discriminative-generative formulation facilitates deeper cross-modal understanding and paves the way for high-fidelity generation. Extensive experiments on VGGSound, AudioSet, and Panda70M demonstrate that GMS-CAVP outperforms previous methods in generation and retrieval.
Omni2Sound: Towards Unified Video-Text-to-Audio Generation
Jan 06, 2026Training a unified model integrating video-to-audio (V2A), text-to-audio (T2A), and joint video-text-to-audio (VT2A) generation offers significant application flexibility, yet faces two unexplored foundational challenges: (1) the scarcity of high-quality audio captions with tight A-V-T alignment, leading to severe semantic conflict between multimodal conditions, and (2) cross-task and intra-task competition, manifesting as an adverse V2A-T2A performance trade-off and modality bias in the VT2A task. First, to address data scarcity, we introduce SoundAtlas, a large-scale dataset (470k pairs) that significantly outperforms existing benchmarks and even human experts in quality. Powered by a novel agentic pipeline, it integrates Vision-to-Language Compression to mitigate visual bias of MLLMs, a Junior-Senior Agent Handoff for a 5 times cost reduction, and rigorous Post-hoc Filtering to ensure fidelity. Consequently, SoundAtlas delivers semantically rich and temporally detailed captions with tight V-A-T alignment. Second, we propose Omni2Sound, a unified VT2A diffusion model supporting flexible input modalities. To resolve the inherent cross-task and intra-task competition, we design a three-stage multi-task progressive training schedule that converts cross-task competition into joint optimization and mitigates modality bias in the VT2A task, maintaining both audio-visual alignment and off-screen audio generation faithfulness. Finally, we construct VGGSound-Omni, a comprehensive benchmark for unified evaluation, including challenging off-screen tracks. With a standard DiT backbone, Omni2Sound achieves unified SOTA performance across all three tasks within a single model, demonstrating strong generalization across benchmarks with heterogeneous input conditions. The project page is at https://swapforward.github.io/Omni2Sound.
Exploiting the Prior of Generative Time Series Imputation
Dec 29, 2025Time series imputation, i.e., filling the missing values of a time recording, finds various applications in electricity, finance, and weather modelling. Previous methods have introduced generative models such as diffusion probabilistic models and Schrodinger bridge models to conditionally generate the missing values from Gaussian noise or directly from linear interpolation results. However, as their prior is not informative to the ground-truth target, their generation process inevitably suffer increased burden and limited imputation accuracy. In this work, we present Bridge-TS, building a data-to-data generation process for generative time series imputation and exploiting the design of prior with two novel designs. Firstly, we propose expert prior, leveraging a pretrained transformer-based module as an expert to fill the missing values with a deterministic estimation, and then taking the results as the prior of ground truth target. Secondly, we explore compositional priors, utilizing several pretrained models to provide different estimation results, and then combining them in the data-to-data generation process to achieve a compositional priors-to-target imputation process. Experiments conducted on several benchmark datasets such as ETT, Exchange, and Weather show that Bridge-TS reaches a new record of imputation accuracy in terms of mean square error and mean absolute error, demonstrating the superiority of improving prior for generative time series imputation.
RefineBridge: Generative Bridge Models Improve Financial Forecasting by Foundation Models
Dec 25, 2025


Financial time series forecasting is particularly challenging for transformer-based time series foundation models (TSFMs) due to non-stationarity, heavy-tailed distributions, and high-frequency noise present in data. Low-rank adaptation (LoRA) has become a popular parameter-efficient method for adapting pre-trained TSFMs to downstream data domains. However, it still underperforms in financial data, as it preserves the network architecture and training objective of TSFMs rather than complementing the foundation model. To further enhance TSFMs, we propose a novel refinement module, RefineBridge, built upon a tractable Schrödinger Bridge (SB) generative framework. Given the forecasts of TSFM as generative prior and the observed ground truths as targets, RefineBridge learns context-conditioned stochastic transport maps to improve TSFM predictions, iteratively approaching the ground-truth target from even a low-quality prior. Simulations on multiple financial benchmarks demonstrate that RefineBridge consistently improves the performance of state-of-the-art TSFMs across different prediction horizons.
Versatile Cardiovascular Signal Generation with a Unified Diffusion Transformer
May 28, 2025Cardiovascular signals such as photoplethysmography (PPG), electrocardiography (ECG), and blood pressure (BP) are inherently correlated and complementary, together reflecting the health of cardiovascular system. However, their joint utilization in real-time monitoring is severely limited by diverse acquisition challenges from noisy wearable recordings to burdened invasive procedures. Here we propose UniCardio, a multi-modal diffusion transformer that reconstructs low-quality signals and synthesizes unrecorded signals in a unified generative framework. Its key innovations include a specialized model architecture to manage the signal modalities involved in generation tasks and a continual learning paradigm to incorporate varying modality combinations. By exploiting the complementary nature of cardiovascular signals, UniCardio clearly outperforms recent task-specific baselines in signal denoising, imputation, and translation. The generated signals match the performance of ground-truth signals in detecting abnormal health conditions and estimating vital signs, even in unseen domains, while ensuring interpretability for human experts. These advantages position UniCardio as a promising avenue for advancing AI-assisted healthcare.
DiffGAP: A Lightweight Diffusion Module in Contrastive Space for Bridging Cross-Model Gap
Mar 15, 2025



Recent works in cross-modal understanding and generation, notably through models like CLAP (Contrastive Language-Audio Pretraining) and CAVP (Contrastive Audio-Visual Pretraining), have significantly enhanced the alignment of text, video, and audio embeddings via a single contrastive loss. However, these methods often overlook the bidirectional interactions and inherent noises present in each modality, which can crucially impact the quality and efficacy of cross-modal integration. To address this limitation, we introduce DiffGAP, a novel approach incorporating a lightweight generative module within the contrastive space. Specifically, our DiffGAP employs a bidirectional diffusion process tailored to bridge the cross-modal gap more effectively. This involves a denoising process on text and video embeddings conditioned on audio embeddings and vice versa, thus facilitating a more nuanced and robust cross-modal interaction. Our experimental results on VGGSound and AudioCaps datasets demonstrate that DiffGAP significantly improves performance in video/text-audio generation and retrieval tasks, confirming its effectiveness in enhancing cross-modal understanding and generation capabilities.
XiHeFusion: Harnessing Large Language Models for Science Communication in Nuclear Fusion
Feb 08, 2025



Nuclear fusion is one of the most promising ways for humans to obtain infinite energy. Currently, with the rapid development of artificial intelligence, the mission of nuclear fusion has also entered a critical period of its development. How to let more people to understand nuclear fusion and join in its research is one of the effective means to accelerate the implementation of fusion. This paper proposes the first large model in the field of nuclear fusion, XiHeFusion, which is obtained through supervised fine-tuning based on the open-source large model Qwen2.5-14B. We have collected multi-source knowledge about nuclear fusion tasks to support the training of this model, including the common crawl, eBooks, arXiv, dissertation, etc. After the model has mastered the knowledge of the nuclear fusion field, we further used the chain of thought to enhance its logical reasoning ability, making XiHeFusion able to provide more accurate and logical answers. In addition, we propose a test questionnaire containing 180+ questions to assess the conversational ability of this science popularization large model. Extensive experimental results show that our nuclear fusion dialogue model, XiHeFusion, can perform well in answering science popularization knowledge. The pre-trained XiHeFusion model is released on https://github.com/Event-AHU/XiHeFusion.
Bridge-SR: Schrödinger Bridge for Efficient SR
Jan 14, 2025



Speech super-resolution (SR), which generates a waveform at a higher sampling rate from its low-resolution version, is a long-standing critical task in speech restoration. Previous works have explored speech SR in different data spaces, but these methods either require additional compression networks or exhibit limited synthesis quality and inference speed. Motivated by recent advances in probabilistic generative models, we present Bridge-SR, a novel and efficient any-to-48kHz SR system in the speech waveform domain. Using tractable Schr\"odinger Bridge models, we leverage the observed low-resolution waveform as a prior, which is intrinsically informative for the high-resolution target. By optimizing a lightweight network to learn the score functions from the prior to the target, we achieve efficient waveform SR through a data-to-data generation process that fully exploits the instructive content contained in the low-resolution observation. Furthermore, we identify the importance of the noise schedule, data scaling, and auxiliary loss functions, which further improve the SR quality of bridge-based systems. The experiments conducted on the benchmark dataset VCTK demonstrate the efficiency of our system: (1) in terms of sample quality, Bridge-SR outperforms several strong baseline methods under different SR settings, using a lightweight network backbone (1.7M); (2) in terms of inference speed, our 4-step synthesis achieves better performance than the 8-step conditional diffusion counterpart (LSD: 0.911 vs 0.927). Demo at https://bridge-sr.github.io.
FrameBridge: Improving Image-to-Video Generation with Bridge Models
Oct 20, 2024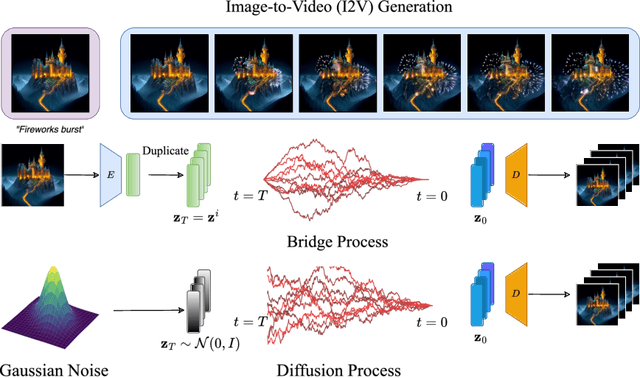
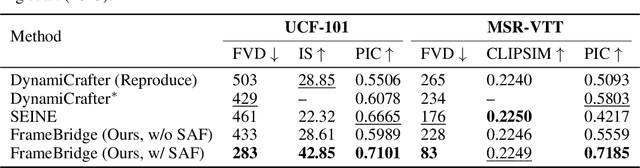
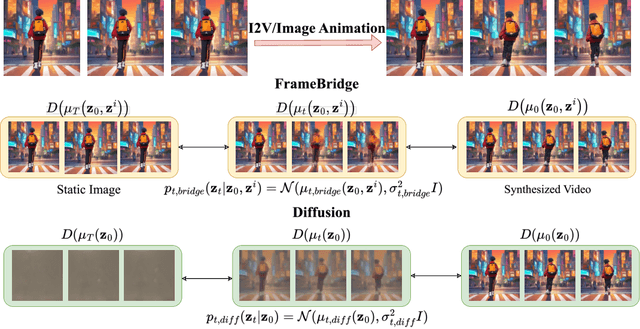
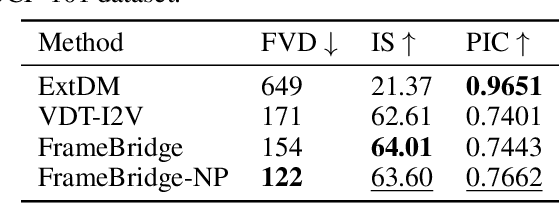
Image-to-video (I2V) generation is gaining increasing attention with its wide application in video synthesis. Recently, diffusion-based I2V models have achieved remarkable progress given their novel design on network architecture, cascaded framework, and motion representation. However, restricted by their noise-to-data generation process, diffusion-based methods inevitably suffer the difficulty to generate video samples with both appearance consistency and temporal coherence from an uninformative Gaussian noise, which may limit their synthesis quality. In this work, we present FrameBridge, taking the given static image as the prior of video target and establishing a tractable bridge model between them. By formulating I2V synthesis as a frames-to-frames generation task and modelling it with a data-to-data process, we fully exploit the information in input image and facilitate the generative model to learn the image animation process. In two popular settings of training I2V models, namely fine-tuning a pre-trained text-to-video (T2V) model or training from scratch, we further propose two techniques, SNR-Aligned Fine-tuning (SAF) and neural prior, which improve the fine-tuning efficiency of diffusion-based T2V models to FrameBridge and the synthesis quality of bridge-based I2V models respectively. Experiments conducted on WebVid-2M and UCF-101 demonstrate that: (1) our FrameBridge achieves superior I2V quality in comparison with the diffusion counterpart (zero-shot FVD 83 vs. 176 on MSR-VTT and non-zero-shot FVD 122 vs. 171 on UCF-101); (2) our proposed SAF and neural prior effectively enhance the ability of bridge-based I2V models in the scenarios of fine-tuning and training from scratch. Demo samples can be visited at: https://framebridge-demo.github.io/.
RespDiff: An End-to-End Multi-scale RNN Diffusion Model for Respiratory Waveform Estimation from PPG Signals
Oct 06, 2024


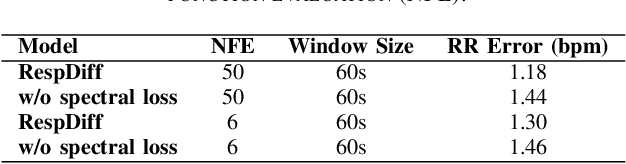
Respiratory rate (RR) is a critical health indicator often monitored under inconvenient scenarios, limiting its practicality for continuous monitoring. Photoplethysmography (PPG) sensors, increasingly integrated into wearable devices, offer a chance to continuously estimate RR in a portable manner. In this paper, we propose RespDiff, an end-to-end multi-scale RNN diffusion model for respiratory waveform estimation from PPG signals. RespDiff does not require hand-crafted features or the exclusion of low-quality signal segments, making it suitable for real-world scenarios. The model employs multi-scale encoders, to extract features at different resolutions, and a bidirectional RNN to process PPG signals and extract respiratory waveform. Additionally, a spectral loss term is introduced to optimize the model further. Experiments conducted on the BIDMC dataset demonstrate that RespDiff outperforms notable previous works, achieving a mean absolute error (MAE) of 1.18 bpm for RR estimation while others range from 1.66 to 2.15 bpm, showing its potential for robust and accurate respiratory monitoring in real-world applications.