 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6Bit-Diffusion: Inference-Time Mixed-Precision Quantization for Video Diffusion Models
Mar 19, 2026Diffusion transformers have demonstrated remarkable capabilities in generating videos. However, their practical deployment is severely constrained by high memory usage and computational cost. Post-Training Quantization provides a practical way to reduce memory usage and boost computation speed. Existing quantization methods typically apply a static bit-width allocation, overlooking the quantization difficulty of activations across diffusion timesteps, leading to a suboptimal trade-off between efficiency and quality. In this paper, we propose a inference time NVFP4/INT8 Mixed-Precision Quantization framework. We find a strong linear correlation between a block's input-output difference and the quantization sensitivity of its internal linear layers. Based on this insight, we design a lightweight predictor that dynamically allocates NVFP4 to temporally stable layers to maximize memory compression, while selectively preserving INT8 for volatile layers to ensure robustness. This adaptive precision strategy enables aggressive quantization without compromising generation quality. Beside this, we observe that the residual between the input and output of a Transformer block exhibits high temporal consistency across timesteps. Leveraging this temporal redundancy, we introduce Temporal Delta Cache (TDC) to skip computations for these invariant blocks, further reducing the computational cost. Extensive experiments demonstrate that our method achieves 1.92$\times$ end-to-end acceleration and 3.32$\times$ memory reduction, setting a new baseline for efficient inference in Video DiTs.
Deterministic Differentiable Structured Pruning for Large Language Models
Mar 09, 2026Structured pruning reduces LLM inference cost by removing low-importance architectural components. This can be viewed as learning a multiplicative gate for each component under an l0 sparsity constraint. Due to the discreteness of the l0 norm, prior work typically adopts stochastic hard-concrete relaxations to enable differentiable optimization; however, this stochasticity can introduce a train--test mismatch when sampled masks are discretized for deployment and restricts masks to a bounded, near-binary range. To address this, we propose Deterministic Differentiable Pruning (DDP), a mask-only optimization method that eliminates stochasticity by directly optimizing a deterministic soft surrogate of the discrete l0 objective. Compared with prior approaches, DDP offers greater expressiveness, reduced train--test mismatch, and faster convergence. We apply our method to several dense and MoE models, including Qwen3-32B and Qwen3-30B-A3B, achieving a performance loss as small as 1% on downstream tasks while outperforming previous methods at 20% sparsity. We further demonstrate end-to-end inference speedups in realistic deployment settings with vLLM.
SageBwd: A Trainable Low-bit Attention
Mar 02, 2026Low-bit attention, such as SageAttention, has emerged as an effective approach for accelerating model inference, but its applicability to training remains poorly understood. In prior work, we introduced SageBwd, a trainable INT8 attention that quantizes six of seven attention matrix multiplications while preserving fine-tuning performance. However, SageBwd exhibited a persistent performance gap to full-precision attention (FPA) during pre-training. In this work, we investigate why this gap occurs and demonstrate that SageBwd matches full-precision attention during pretraining. Through experiments and theoretical analysis, we reach a few important insights and conclusions: (i) QK-norm is necessary for stable training at large tokens per step, (ii) quantization errors primarily arise from the backward-pass score gradient dS, (iii) reducing tokens per step enables SageBwd to match FPA performance in pre-training, and (iv) K-smoothing remains essential for training stability, while Q-smoothing provides limited benefit during pre-training.
SLA2: Sparse-Linear Attention with Learnable Routing and QAT
Feb 13, 2026Sparse-Linear Attention (SLA) combines sparse and linear attention to accelerate diffusion models and has shown strong performance in video generation. However, (i) SLA relies on a heuristic split that assigns computations to the sparse or linear branch based on attention-weight magnitude, which can be suboptimal. Additionally, (ii) after formally analyzing the attention error in SLA, we identify a mismatch between SLA and a direct decomposition into sparse and linear attention. We propose SLA2, which introduces (I) a learnable router that dynamically selects whether each attention computation should use sparse or linear attention, (II) a more faithful and direct sparse-linear attention formulation that uses a learnable ratio to combine the sparse and linear attention branches, and (III) a sparse + low-bit attention design, where low-bit attention is introduced via quantization-aware fine-tuning to reduce quantization error. Experiments show that on video diffusion models, SLA2 can achieve 97% attention sparsity and deliver an 18.6x attention speedup while preserving generation quality.
SpargeAttention2: Trainable Sparse Attention via Hybrid Top-k+Top-p Masking and Distillation Fine-Tuning
Feb 13, 2026Many training-free sparse attention methods are effective for accelerating diffusion models. Recently, several works suggest that making sparse attention trainable can further increase sparsity while preserving generation quality. We study three key questions: (1) when do the two common masking rules, i.e., Top-k and Top-p, fail, and how can we avoid these failures? (2) why can trainable sparse attention reach higher sparsity than training-free methods? (3) what are the limitations of fine-tuning sparse attention using the diffusion loss, and how can we address them? Based on this analysis, we propose SpargeAttention2, a trainable sparse attention method that achieves high sparsity without degrading generation quality. SpargeAttention2 includes (i) a hybrid masking rule that combines Top-k and Top-p for more robust masking at high sparsity, (ii) an efficient trainable sparse attention implementation, and (iii) a distillation-inspired fine-tuning objective to better preserve generation quality during fine-tuning using sparse attention. Experiments on video diffusion models show that SpargeAttention2 reaches 95% attention sparsity and a 16.2x attention speedup while maintaining generation quality, consistently outperforming prior sparse attention methods.
TurboDiffusion: Accelerating Video Diffusion Models by 100-200 Times
Dec 18, 2025We introduce TurboDiffusion, a video generation acceleration framework that can speed up end-to-end diffusion generation by 100-200x while maintaining video quality. TurboDiffusion mainly relies on several components for acceleration: (1) Attention acceleration: TurboDiffusion uses low-bit SageAttention and trainable Sparse-Linear Attention (SLA) to speed up attention computation. (2) Step distillation: TurboDiffusion adopts rCM for efficient step distillation. (3) W8A8 quantization: TurboDiffusion quantizes model parameters and activations to 8 bits to accelerate linear layers and compress the model. In addition, TurboDiffusion incorporates several other engineering optimizations. We conduct experiments on the Wan2.2-I2V-14B-720P, Wan2.1-T2V-1.3B-480P, Wan2.1-T2V-14B-720P, and Wan2.1-T2V-14B-480P models. Experimental results show that TurboDiffusion achieves 100-200x speedup for video generation even on a single RTX 5090 GPU, while maintaining comparable video quality. The GitHub repository, which includes model checkpoints and easy-to-use code, is available at https://github.com/thu-ml/TurboDiffusion.
TetraJet-v2: Accurate NVFP4 Training for Large Language Models with Oscillation Suppression and Outlier Control
Oct 31, 2025Large Language Models (LLMs) training is prohibitively expensive, driving interest in low-precision fully-quantized training (FQT). While novel 4-bit formats like NVFP4 offer substantial efficiency gains, achieving near-lossless training at such low precision remains challenging. We introduce TetraJet-v2, an end-to-end 4-bit FQT method that leverages NVFP4 for activations, weights, and gradients in all linear layers. We identify two critical issues hindering low-precision LLM training: weight oscillation and outliers. To address these, we propose: 1) an unbiased double-block quantization method for NVFP4 linear layers, 2) OsciReset, an algorithm to suppress weight oscillation, and 3) OutControl, an algorithm to retain outlier accuracy. TetraJet-v2 consistently outperforms prior FP4 training methods on pre-training LLMs across varying model sizes up to 370M and data sizes up to 200B tokens, reducing the performance gap to full-precision training by an average of 51.3%.
Task-Specific Zero-shot Quantization-Aware Training for Object Detection
Jul 22, 2025Quantization is a key technique to reduce network size and computational complexity by representing the network parameters with a lower precision. Traditional quantization methods rely on access to original training data, which is often restricted due to privacy concerns or security challenges. Zero-shot Quantization (ZSQ) addresses this by using synthetic data generated from pre-trained models, eliminating the need for real training data. Recently, ZSQ has been extended to object detection. However, existing methods use unlabeled task-agnostic synthetic images that lack the specific information required for object detection, leading to suboptimal performance. In this paper, we propose a novel task-specific ZSQ framework for object detection networks, which consists of two main stages. First, we introduce a bounding box and category sampling strategy to synthesize a task-specific calibration set from the pre-trained network, reconstructing object locations, sizes, and category distributions without any prior knowledge. Second, we integrate task-specific training into the knowledge distillation process to restore the performance of quantized detection networks. Extensive experiments conducted on the MS-COCO and Pascal VOC datasets demonstrate the efficiency and state-of-the-art performance of our method. Our code is publicly available at: https://github.com/DFQ-Dojo/dfq-toolkit .
SageAttention2++: A More Efficient Implementation of SageAttention2
May 28, 2025



The efficiency of attention is critical because its time complexity grows quadratically with sequence length. SageAttention2 addresses this by utilizing quantization to accelerate matrix multiplications (Matmul) in attention. To further accelerate SageAttention2, we propose to utilize the faster instruction of FP8 Matmul accumulated in FP16. The instruction is 2x faster than the FP8 Matmul used in SageAttention2. Our experiments show that SageAttention2++ achieves a 3.9x speedup over FlashAttention while maintaining the same attention accuracy as SageAttention2. This means SageAttention2++ effectively accelerates various models, including those for language, image, and video generation, with negligible end-to-end metrics loss. The code will be available at https://github.com/thu-ml/SageAttention.
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
May 25, 2025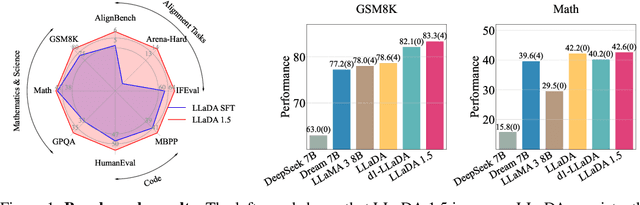
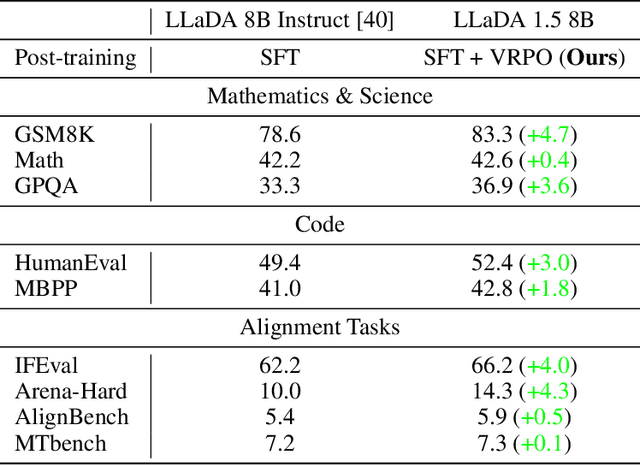
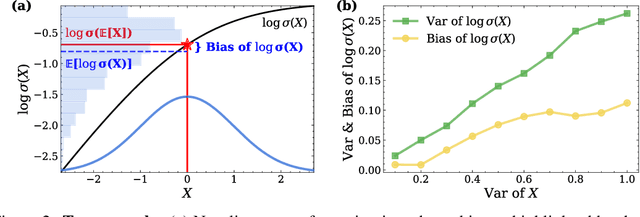
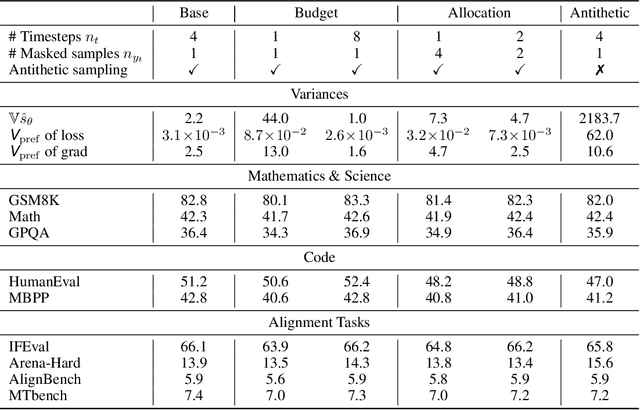
While Masked Diffusion Models (MDMs), such as LLaDA, present a promising paradigm for language modeling, there has been relatively little effort in aligning these models with human preferences via reinforcement learning. The challenge primarily arises from the high variance in Evidence Lower Bound (ELBO)-based likelihood estimates required for preference optimization. To address this issue, we propose Variance-Reduced Preference Optimization (VRPO), a framework that formally analyzes the variance of ELBO estimators and derives bounds on both the bias and variance of preference optimization gradients. Building on this theoretical foundation, we introduce unbiased variance reduction strategies, including optimal Monte Carlo budget allocation and antithetic sampling, that significantly improve the performance of MDM alignment. We demonstrate the effectiveness of VRPO by applying it to LLaDA, and the resulting model, LLaDA 1.5, outperforms its SFT-only predecessor consistently and significantly across mathematical (GSM8K +4.7), code (HumanEval +3.0, MBPP +1.8), and alignment benchmarks (IFEval +4.0, Arena-Hard +4.3). Furthermore, LLaDA 1.5 demonstrates a highly competitive mathematical performance compared to strong language MDMs and ARMs. Project page: https://ml-gsai.github.io/LLaDA-1.5-Demo/.