 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpargeAttention2: Trainable Sparse Attention via Hybrid Top-k+Top-p Masking and Distillation Fine-Tuning
Feb 13, 2026Many training-free sparse attention methods are effective for accelerating diffusion models. Recently, several works suggest that making sparse attention trainable can further increase sparsity while preserving generation quality. We study three key questions: (1) when do the two common masking rules, i.e., Top-k and Top-p, fail, and how can we avoid these failures? (2) why can trainable sparse attention reach higher sparsity than training-free methods? (3) what are the limitations of fine-tuning sparse attention using the diffusion loss, and how can we address them? Based on this analysis, we propose SpargeAttention2, a trainable sparse attention method that achieves high sparsity without degrading generation quality. SpargeAttention2 includes (i) a hybrid masking rule that combines Top-k and Top-p for more robust masking at high sparsity, (ii) an efficient trainable sparse attention implementation, and (iii) a distillation-inspired fine-tuning objective to better preserve generation quality during fine-tuning using sparse attention. Experiments on video diffusion models show that SpargeAttention2 reaches 95% attention sparsity and a 16.2x attention speedup while maintaining generation quality, consistently outperforming prior sparse attention methods.
Geometry-Aware Rotary Position Embedding for Consistent Video World Model
Feb 08, 2026Predictive world models that simulate future observations under explicit camera control are fundamental to interactive AI. Despite rapid advances, current systems lack spatial persistence: they fail to maintain stable scene structures over long trajectories, frequently hallucinating details when cameras revisit previously observed locations. We identify that this geometric drift stems from reliance on screen-space positional embeddings, which conflict with the projective geometry required for 3D consistency. We introduce \textbf{ViewRope}, a geometry-aware encoding that injects camera-ray directions directly into video transformer self-attention layers. By parameterizing attention with relative ray geometry rather than pixel locality, ViewRope provides a model-native inductive bias for retrieving 3D-consistent content across temporal gaps. We further propose \textbf{Geometry-Aware Frame-Sparse Attention}, which exploits these geometric cues to selectively attend to relevant historical frames, improving efficiency without sacrificing memory consistency. We also present \textbf{ViewBench}, a diagnostic suite measuring loop-closure fidelity and geometric drift. Our results demonstrate that ViewRope substantially improves long-term consistency while reducing computational costs.
Vidarc: Embodied Video Diffusion Model for Closed-loop Control
Dec 19, 2025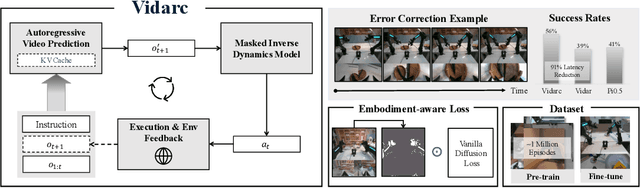
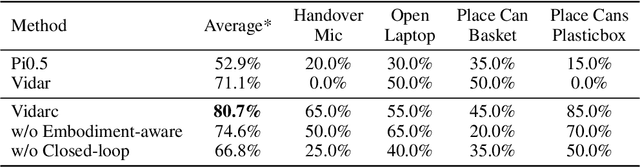
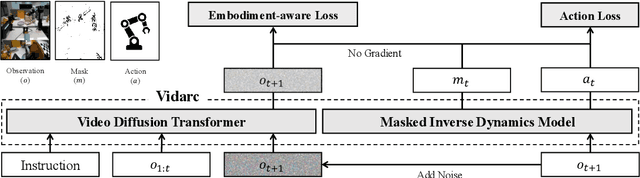
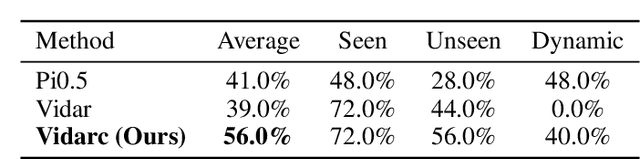
Robotic arm manipulation in data-scarce settings is a highly challenging task due to the complex embodiment dynamics and diverse contexts. Recent video-based approaches have shown great promise in capturing and transferring the temporal and physical interactions by pre-training on Internet-scale video data. However, such methods are often not optimized for the embodiment-specific closed-loop control, typically suffering from high latency and insufficient grounding. In this paper, we present Vidarc (Video Diffusion for Action Reasoning and Closed-loop Control), a novel autoregressive embodied video diffusion approach augmented by a masked inverse dynamics model. By grounding video predictions with action-relevant masks and incorporating real-time feedback through cached autoregressive generation, Vidarc achieves fast, accurate closed-loop control. Pre-trained on one million cross-embodiment episodes, Vidarc surpasses state-of-the-art baselines, achieving at least a 15% higher success rate in real-world deployment and a 91% reduction in latency. We also highlight its robust generalization and error correction capabilities across previously unseen robotic platforms.
Motus: A Unified Latent Action World Model
Dec 15, 2025While a general embodied agent must function as a unified system, current methods are built on isolated models for understanding, world modeling, and control. This fragmentation prevents unifying multimodal generative capabilities and hinders learning from large-scale, heterogeneous data. In this paper, we propose Motus, a unified latent action world model that leverages existing general pretrained models and rich, sharable motion information. Motus introduces a Mixture-of-Transformer (MoT) architecture to integrate three experts (i.e., understanding, video generation, and action) and adopts a UniDiffuser-style scheduler to enable flexible switching between different modeling modes (i.e., world models, vision-language-action models, inverse dynamics models, video generation models, and video-action joint prediction models). Motus further leverages the optical flow to learn latent actions and adopts a recipe with three-phase training pipeline and six-layer data pyramid, thereby extracting pixel-level "delta action" and enabling large-scale action pretraining. Experiments show that Motus achieves superior performance against state-of-the-art methods in both simulation (a +15% improvement over X-VLA and a +45% improvement over Pi0.5) and real-world scenarios(improved by +11~48%), demonstrating unified modeling of all functionalities and priors significantly benefits downstream robotic tasks.
SageAttention2++: A More Efficient Implementation of SageAttention2
May 28, 2025



The efficiency of attention is critical because its time complexity grows quadratically with sequence length. SageAttention2 addresses this by utilizing quantization to accelerate matrix multiplications (Matmul) in attention. To further accelerate SageAttention2, we propose to utilize the faster instruction of FP8 Matmul accumulated in FP16. The instruction is 2x faster than the FP8 Matmul used in SageAttention2. Our experiments show that SageAttention2++ achieves a 3.9x speedup over FlashAttention while maintaining the same attention accuracy as SageAttention2. This means SageAttention2++ effectively accelerates various models, including those for language, image, and video generation, with negligible end-to-end metrics loss. The code will be available at https://github.com/thu-ml/SageAttention.
SpargeAttn: Accurate Sparse Attention Accelerating Any Model Inference
Feb 25, 2025An efficient attention implementation is essential for large models due to its quadratic time complexity. Fortunately, attention commonly exhibits sparsity, i.e., many values in the attention map are near zero, allowing for the omission of corresponding computations. Many studies have utilized the sparse pattern to accelerate attention. However, most existing works focus on optimizing attention within specific models by exploiting certain sparse patterns of the attention map. A universal sparse attention that guarantees both the speedup and end-to-end performance of diverse models remains elusive. In this paper, we propose SpargeAttn, a universal sparse and quantized attention for any model. Our method uses a two-stage online filter: in the first stage, we rapidly and accurately predict the attention map, enabling the skip of some matrix multiplications in attention. In the second stage, we design an online softmax-aware filter that incurs no extra overhead and further skips some matrix multiplications. Experiments show that our method significantly accelerates diverse models, including language, image, and video generation, without sacrificing end-to-end metrics. The codes are available at https://github.com/thu-ml/SpargeAttn.
Identifying and Solving Conditional Image Leakage in Image-to-Video Diffusion Model
Jun 22, 2024


Diffusion models have obtained substantial progress in image-to-video (I2V) generation. However, such models are not fully understood. In this paper, we report a significant but previously overlooked issue in I2V diffusion models (I2V-DMs), namely, conditional image leakage. I2V-DMs tend to over-rely on the conditional image at large time steps, neglecting the crucial task of predicting the clean video from noisy inputs, which results in videos lacking dynamic and vivid motion. We further address this challenge from both inference and training aspects by presenting plug-and-play strategies accordingly. First, we introduce a training-free inference strategy that starts the generation process from an earlier time step to avoid the unreliable late-time steps of I2V-DMs, as well as an initial noise distribution with optimal analytic expressions (Analytic-Init) by minimizing the KL divergence between it and the actual marginal distribution to effectively bridge the training-inference gap. Second, to mitigate conditional image leakage during training, we design a time-dependent noise distribution for the conditional image, which favors high noise levels at large time steps to sufficiently interfere with the conditional image. We validate these strategies on various I2V-DMs using our collected open-domain image benchmark and the UCF101 dataset. Extensive results demonstrate that our methods outperform baselines by producing videos with more dynamic and natural motion without compromising image alignment and temporal consistency. The project page: \url{https://cond-image-leak.github.io/}.
Vidu: a Highly Consistent, Dynamic and Skilled Text-to-Video Generator with Diffusion Models
May 07, 2024



We introduce Vidu, a high-performance text-to-video generator that is capable of producing 1080p videos up to 16 seconds in a single generation. Vidu is a diffusion model with U-ViT as its backbone, which unlocks the scalability and the capability for handling long videos. Vidu exhibits strong coherence and dynamism, and is capable of generating both realistic and imaginative videos, as well as understanding some professional photography techniques, on par with Sora -- the most powerful reported text-to-video generator. Finally, we perform initial experiments on other controllable video generation, including canny-to-video generation, video prediction and subject-driven generation, which demonstrate promising results.
CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model
Mar 08, 2024Feed-forward 3D generative models like the Large Reconstruction Model (LRM) have demonstrated exceptional generation speed. However, the transformer-based methods do not leverage the geometric priors of the triplane component in their architecture, often leading to sub-optimal quality given the limited size of 3D data and slow training. In this work, we present the Convolutional Reconstruction Model (CRM), a high-fidelity feed-forward single image-to-3D generative model. Recognizing the limitations posed by sparse 3D data, we highlight the necessity of integrating geometric priors into network design. CRM builds on the key observation that the visualization of triplane exhibits spatial correspondence of six orthographic images. First, it generates six orthographic view images from a single input image, then feeds these images into a convolutional U-Net, leveraging its strong pixel-level alignment capabilities and significant bandwidth to create a high-resolution triplane. CRM further employs Flexicubes as geometric representation, facilitating direct end-to-end optimization on textured meshes. Overall, our model delivers a high-fidelity textured mesh from an image in just 10 seconds, without any test-time optimization.
A Closer Look at Parameter-Efficient Tuning in Diffusion Models
Apr 12, 2023



Large-scale diffusion models like Stable Diffusion are powerful and find various real-world applications while customizing such models by fine-tuning is both memory and time inefficient. Motivated by the recent progress in natural language processing, we investigate parameter-efficient tuning in large diffusion models by inserting small learnable modules (termed adapters). In particular, we decompose the design space of adapters into orthogonal factors -- the input position, the output position as well as the function form, and perform Analysis of Variance (ANOVA), a classical statistical approach for analyzing the correlation between discrete (design options) and continuous variables (evaluation metrics). Our analysis suggests that the input position of adapters is the critical factor influencing the performance of downstream tasks. Then, we carefully study the choice of the input position, and we find that putting the input position after the cross-attention block can lead to the best performance, validated by additional visualization analyses. Finally, we provide a recipe for parameter-efficient tuning in diffusion models, which is comparable if not superior to the fully fine-tuned baseline (e.g., DreamBooth) with only 0.75 \% extra parameters, across various customized tasks.