 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Forcing: Autoregressive Diffusion Distillation Done Right for High-Quality Real-Time Interactive Video Generation
Feb 02, 2026To achieve real-time interactive video generation, current methods distill pretrained bidirectional video diffusion models into few-step autoregressive (AR) models, facing an architectural gap when full attention is replaced by causal attention. However, existing approaches do not bridge this gap theoretically. They initialize the AR student via ODE distillation, which requires frame-level injectivity, where each noisy frame must map to a unique clean frame under the PF-ODE of an AR teacher. Distilling an AR student from a bidirectional teacher violates this condition, preventing recovery of the teacher's flow map and instead inducing a conditional-expectation solution, which degrades performance. To address this issue, we propose Causal Forcing that uses an AR teacher for ODE initialization, thereby bridging the architectural gap. Empirical results show that our method outperforms all baselines across all metrics, surpassing the SOTA Self Forcing by 19.3\% in Dynamic Degree, 8.7\% in VisionReward, and 16.7\% in Instruction Following. Project page and the code: \href{https://thu-ml.github.io/CausalForcing.github.io/}{https://thu-ml.github.io/CausalForcing.github.io/}
RIFLEx: A Free Lunch for Length Extrapolation in Video Diffusion Transformers
Feb 21, 2025Recent advancements in video generation have enabled models to synthesize high-quality, minute-long videos. However, generating even longer videos with temporal coherence remains a major challenge, and existing length extrapolation methods lead to temporal repetition or motion deceleration. In this work, we systematically analyze the role of frequency components in positional embeddings and identify an intrinsic frequency that primarily governs extrapolation behavior. Based on this insight, we propose RIFLEx, a minimal yet effective approach that reduces the intrinsic frequency to suppress repetition while preserving motion consistency, without requiring any additional modifications. RIFLEx offers a true free lunch--achieving high-quality $2\times$ extrapolation on state-of-the-art video diffusion transformers in a completely training-free manner. Moreover, it enhances quality and enables $3\times$ extrapolation by minimal fine-tuning without long videos. Project page and codes: \href{https://riflex-video.github.io/}{https://riflex-video.github.io/.}
Identifying and Solving Conditional Image Leakage in Image-to-Video Diffusion Model
Jun 22, 2024
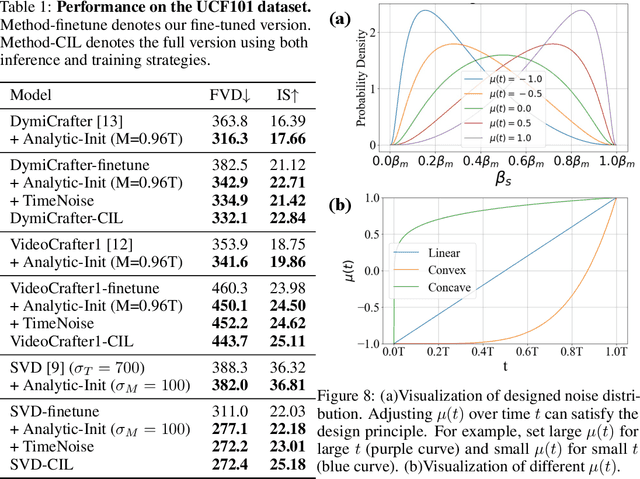


Diffusion models have obtained substantial progress in image-to-video (I2V) generation. However, such models are not fully understood. In this paper, we report a significant but previously overlooked issue in I2V diffusion models (I2V-DMs), namely, conditional image leakage. I2V-DMs tend to over-rely on the conditional image at large time steps, neglecting the crucial task of predicting the clean video from noisy inputs, which results in videos lacking dynamic and vivid motion. We further address this challenge from both inference and training aspects by presenting plug-and-play strategies accordingly. First, we introduce a training-free inference strategy that starts the generation process from an earlier time step to avoid the unreliable late-time steps of I2V-DMs, as well as an initial noise distribution with optimal analytic expressions (Analytic-Init) by minimizing the KL divergence between it and the actual marginal distribution to effectively bridge the training-inference gap. Second, to mitigate conditional image leakage during training, we design a time-dependent noise distribution for the conditional image, which favors high noise levels at large time steps to sufficiently interfere with the conditional image. We validate these strategies on various I2V-DMs using our collected open-domain image benchmark and the UCF101 dataset. Extensive results demonstrate that our methods outperform baselines by producing videos with more dynamic and natural motion without compromising image alignment and temporal consistency. The project page: \url{https://cond-image-leak.github.io/}.
Vidu: a Highly Consistent, Dynamic and Skilled Text-to-Video Generator with Diffusion Models
May 07, 2024



We introduce Vidu, a high-performance text-to-video generator that is capable of producing 1080p videos up to 16 seconds in a single generation. Vidu is a diffusion model with U-ViT as its backbone, which unlocks the scalability and the capability for handling long videos. Vidu exhibits strong coherence and dynamism, and is capable of generating both realistic and imaginative videos, as well as understanding some professional photography techniques, on par with Sora -- the most powerful reported text-to-video generator. Finally, we perform initial experiments on other controllable video generation, including canny-to-video generation, video prediction and subject-driven generation, which demonstrate promising results.