 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffGAP: A Lightweight Diffusion Module in Contrastive Space for Bridging Cross-Model Gap
Mar 15, 2025



Recent works in cross-modal understanding and generation, notably through models like CLAP (Contrastive Language-Audio Pretraining) and CAVP (Contrastive Audio-Visual Pretraining), have significantly enhanced the alignment of text, video, and audio embeddings via a single contrastive loss. However, these methods often overlook the bidirectional interactions and inherent noises present in each modality, which can crucially impact the quality and efficacy of cross-modal integration. To address this limitation, we introduce DiffGAP, a novel approach incorporating a lightweight generative module within the contrastive space. Specifically, our DiffGAP employs a bidirectional diffusion process tailored to bridge the cross-modal gap more effectively. This involves a denoising process on text and video embeddings conditioned on audio embeddings and vice versa, thus facilitating a more nuanced and robust cross-modal interaction. Our experimental results on VGGSound and AudioCaps datasets demonstrate that DiffGAP significantly improves performance in video/text-audio generation and retrieval tasks, confirming its effectiveness in enhancing cross-modal understanding and generation capabilities.
Elucidating the Preconditioning in Consistency Distillation
Feb 05, 2025Consistency distillation is a prevalent way for accelerating diffusion models adopted in consistency (trajectory) models, in which a student model is trained to traverse backward on the probability flow (PF) ordinary differential equation (ODE) trajectory determined by the teacher model. Preconditioning is a vital technique for stabilizing consistency distillation, by linear combining the input data and the network output with pre-defined coefficients as the consistency function. It imposes the boundary condition of consistency functions without restricting the form and expressiveness of the neural network. However, previous preconditionings are hand-crafted and may be suboptimal choices. In this work, we offer the first theoretical insights into the preconditioning in consistency distillation, by elucidating its design criteria and the connection to the teacher ODE trajectory. Based on these analyses, we further propose a principled way dubbed \textit{Analytic-Precond} to analytically optimize the preconditioning according to the consistency gap (defined as the gap between the teacher denoiser and the optimal student denoiser) on a generalized teacher ODE. We demonstrate that Analytic-Precond can facilitate the learning of trajectory jumpers, enhance the alignment of the student trajectory with the teacher's, and achieve $2\times$ to $3\times$ training acceleration of consistency trajectory models in multi-step generation across various datasets.
Bridge-SR: Schrödinger Bridge for Efficient SR
Jan 14, 2025



Speech super-resolution (SR), which generates a waveform at a higher sampling rate from its low-resolution version, is a long-standing critical task in speech restoration. Previous works have explored speech SR in different data spaces, but these methods either require additional compression networks or exhibit limited synthesis quality and inference speed. Motivated by recent advances in probabilistic generative models, we present Bridge-SR, a novel and efficient any-to-48kHz SR system in the speech waveform domain. Using tractable Schr\"odinger Bridge models, we leverage the observed low-resolution waveform as a prior, which is intrinsically informative for the high-resolution target. By optimizing a lightweight network to learn the score functions from the prior to the target, we achieve efficient waveform SR through a data-to-data generation process that fully exploits the instructive content contained in the low-resolution observation. Furthermore, we identify the importance of the noise schedule, data scaling, and auxiliary loss functions, which further improve the SR quality of bridge-based systems. The experiments conducted on the benchmark dataset VCTK demonstrate the efficiency of our system: (1) in terms of sample quality, Bridge-SR outperforms several strong baseline methods under different SR settings, using a lightweight network backbone (1.7M); (2) in terms of inference speed, our 4-step synthesis achieves better performance than the 8-step conditional diffusion counterpart (LSD: 0.911 vs 0.927). Demo at https://bridge-sr.github.io.
Consistency Diffusion Bridge Models
Oct 31, 2024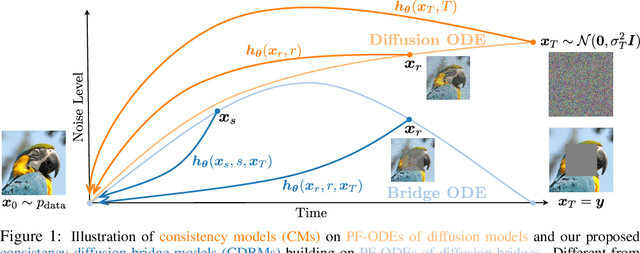

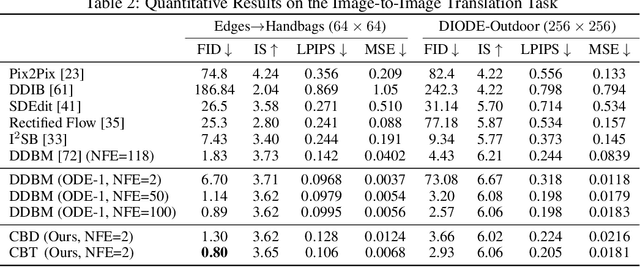
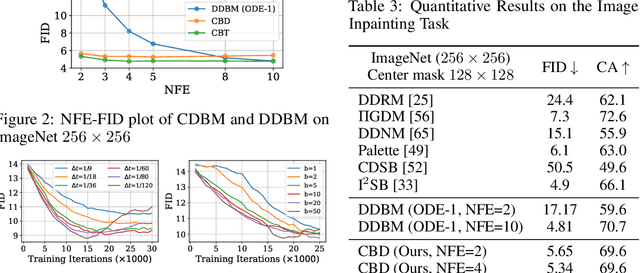
Diffusion models (DMs) have become the dominant paradigm of generative modeling in a variety of domains by learning stochastic processes from noise to data. Recently, diffusion denoising bridge models (DDBMs), a new formulation of generative modeling that builds stochastic processes between fixed data endpoints based on a reference diffusion process, have achieved empirical success across tasks with coupled data distribution, such as image-to-image translation. However, DDBM's sampling process typically requires hundreds of network evaluations to achieve decent performance, which may impede their practical deployment due to high computational demands. In this work, inspired by the recent advance of consistency models in DMs, we tackle this problem by learning the consistency function of the probability-flow ordinary differential equation (PF-ODE) of DDBMs, which directly predicts the solution at a starting step given any point on the ODE trajectory. Based on a dedicated general-form ODE solver, we propose two paradigms: consistency bridge distillation and consistency bridge training, which is flexible to apply on DDBMs with broad design choices. Experimental results show that our proposed method could sample $4\times$ to $50\times$ faster than the base DDBM and produce better visual quality given the same step in various tasks with pixel resolution ranging from $64 \times 64$ to $256 \times 256$, as well as supporting downstream tasks such as semantic interpolation in the data space.
Diffusion Bridge Implicit Models
May 24, 2024



Denoising diffusion bridge models (DDBMs) are a powerful variant of diffusion models for interpolating between two arbitrary paired distributions given as endpoints. Despite their promising performance in tasks like image translation, DDBMs require a computationally intensive sampling process that involves the simulation of a (stochastic) differential equation through hundreds of network evaluations. In this work, we present diffusion bridge implicit models (DBIMs) for accelerated sampling of diffusion bridges without extra training. We generalize DDBMs via a class of non-Markovian diffusion bridges defined on the discretized timesteps concerning sampling, which share the same training objective as DDBMs. These generalized diffusion bridges give rise to generative processes ranging from stochastic to deterministic (i.e., an implicit probabilistic model) while being up to 25$\times$ faster than the vanilla sampler of DDBMs. Moreover, the deterministic sampling procedure yielded by DBIMs enables faithful encoding and reconstruction by a booting noise used in the initial sampling step, and allows us to perform semantically meaningful interpolation in image translation tasks by regarding the booting noise as the latent variable.
Vidu: a Highly Consistent, Dynamic and Skilled Text-to-Video Generator with Diffusion Models
May 07, 2024



We introduce Vidu, a high-performance text-to-video generator that is capable of producing 1080p videos up to 16 seconds in a single generation. Vidu is a diffusion model with U-ViT as its backbone, which unlocks the scalability and the capability for handling long videos. Vidu exhibits strong coherence and dynamism, and is capable of generating both realistic and imaginative videos, as well as understanding some professional photography techniques, on par with Sora -- the most powerful reported text-to-video generator. Finally, we perform initial experiments on other controllable video generation, including canny-to-video generation, video prediction and subject-driven generation, which demonstrate promising results.
Gaussian Mixture Solvers for Diffusion Models
Nov 02, 2023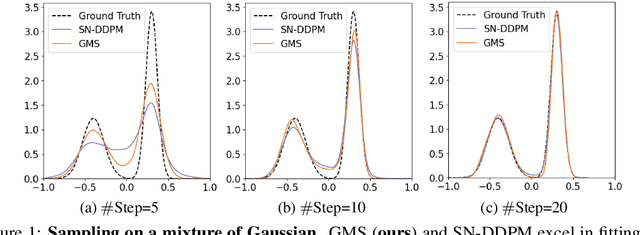
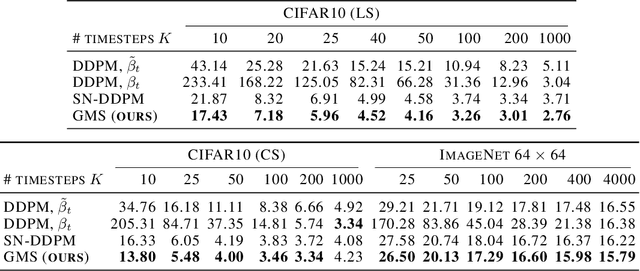
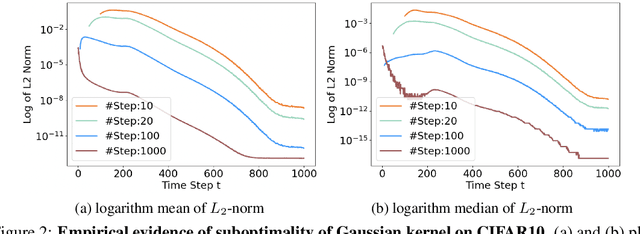
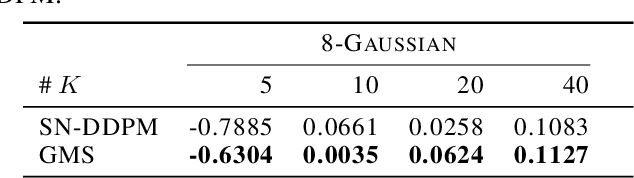
Recently, diffusion models have achieved great success in generative tasks. Sampling from diffusion models is equivalent to solving the reverse diffusion stochastic differential equations (SDEs) or the corresponding probability flow ordinary differential equations (ODEs). In comparison, SDE-based solvers can generate samples of higher quality and are suited for image translation tasks like stroke-based synthesis. During inference, however, existing SDE-based solvers are severely constrained by the efficiency-effectiveness dilemma. Our investigation suggests that this is because the Gaussian assumption in the reverse transition kernel is frequently violated (even in the case of simple mixture data) given a limited number of discretization steps. To overcome this limitation, we introduce a novel class of SDE-based solvers called \emph{Gaussian Mixture Solvers (GMS)} for diffusion models. Our solver estimates the first three-order moments and optimizes the parameters of a Gaussian mixture transition kernel using generalized methods of moments in each step during sampling. Empirically, our solver outperforms numerous SDE-based solvers in terms of sample quality in image generation and stroke-based synthesis in various diffusion models, which validates the motivation and effectiveness of GMS. Our code is available at https://github.com/Guohanzhong/GMS.
ControlVideo: Adding Conditional Control for One Shot Text-to-Video Editing
May 26, 2023



In this paper, we present ControlVideo, a novel method for text-driven video editing. Leveraging the capabilities of text-to-image diffusion models and ControlNet, ControlVideo aims to enhance the fidelity and temporal consistency of videos that align with a given text while preserving the structure of the source video. This is achieved by incorporating additional conditions such as edge maps, fine-tuning the key-frame and temporal attention on the source video-text pair with carefully designed strategies. An in-depth exploration of ControlVideo's design is conducted to inform future research on one-shot tuning video diffusion models. Quantitatively, ControlVideo outperforms a range of competitive baselines in terms of faithfulness and consistency while still aligning with the textual prompt. Additionally, it delivers videos with high visual realism and fidelity w.r.t. the source content, demonstrating flexibility in utilizing controls containing varying degrees of source video information, and the potential for multiple control combinations. The project page is available at \href{https://ml.cs.tsinghua.edu.cn/controlvideo/}{https://ml.cs.tsinghua.edu.cn/controlvideo/}.
ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation
May 25, 2023
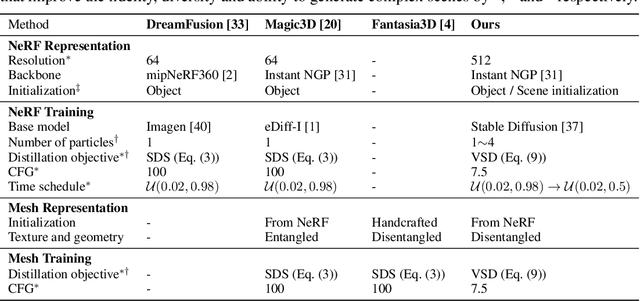
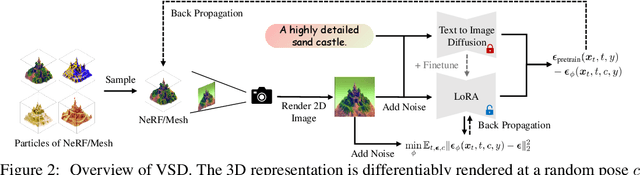

Score distillation sampling (SDS) has shown great promise in text-to-3D generation by distilling pretrained large-scale text-to-image diffusion models, but suffers from over-saturation, over-smoothing, and low-diversity problems. In this work, we propose to model the 3D parameter as a random variable instead of a constant as in SDS and present variational score distillation (VSD), a principled particle-based variational framework to explain and address the aforementioned issues in text-to-3D generation. We show that SDS is a special case of VSD and leads to poor samples with both small and large CFG weights. In comparison, VSD works well with various CFG weights as ancestral sampling from diffusion models and simultaneously improves the diversity and sample quality with a common CFG weight (i.e., $7.5$). We further present various improvements in the design space for text-to-3D such as distillation time schedule and density initialization, which are orthogonal to the distillation algorithm yet not well explored. Our overall approach, dubbed ProlificDreamer, can generate high rendering resolution (i.e., $512\times512$) and high-fidelity NeRF with rich structure and complex effects (e.g., smoke and drops). Further, initialized from NeRF, meshes fine-tuned by VSD are meticulously detailed and photo-realistic. Project page: https://ml.cs.tsinghua.edu.cn/prolificdreamer/
A Closer Look at Parameter-Efficient Tuning in Diffusion Models
Apr 12, 2023



Large-scale diffusion models like Stable Diffusion are powerful and find various real-world applications while customizing such models by fine-tuning is both memory and time inefficient. Motivated by the recent progress in natural language processing, we investigate parameter-efficient tuning in large diffusion models by inserting small learnable modules (termed adapters). In particular, we decompose the design space of adapters into orthogonal factors -- the input position, the output position as well as the function form, and perform Analysis of Variance (ANOVA), a classical statistical approach for analyzing the correlation between discrete (design options) and continuous variables (evaluation metrics). Our analysis suggests that the input position of adapters is the critical factor influencing the performance of downstream tasks. Then, we carefully study the choice of the input position, and we find that putting the input position after the cross-attention block can lead to the best performance, validated by additional visualization analyses. Finally, we provide a recipe for parameter-efficient tuning in diffusion models, which is comparable if not superior to the fully fine-tuned baseline (e.g., DreamBooth) with only 0.75 \% extra parameters, across various customized tasks.