 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation
Paper and Code

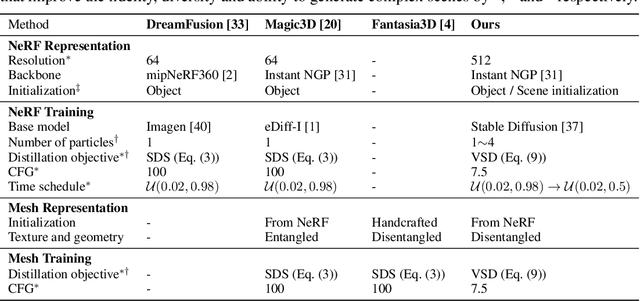
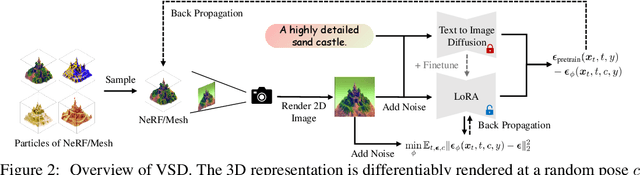

Score distillation sampling (SDS) has shown great promise in text-to-3D generation by distilling pretrained large-scale text-to-image diffusion models, but suffers from over-saturation, over-smoothing, and low-diversity problems. In this work, we propose to model the 3D parameter as a random variable instead of a constant as in SDS and present variational score distillation (VSD), a principled particle-based variational framework to explain and address the aforementioned issues in text-to-3D generation. We show that SDS is a special case of VSD and leads to poor samples with both small and large CFG weights. In comparison, VSD works well with various CFG weights as ancestral sampling from diffusion models and simultaneously improves the diversity and sample quality with a common CFG weight (i.e., $7.5$). We further present various improvements in the design space for text-to-3D such as distillation time schedule and density initialization, which are orthogonal to the distillation algorithm yet not well explored. Our overall approach, dubbed ProlificDreamer, can generate high rendering resolution (i.e., $512\times512$) and high-fidelity NeRF with rich structure and complex effects (e.g., smoke and drops). Further, initialized from NeRF, meshes fine-tuned by VSD are meticulously detailed and photo-realistic. Project page: https://ml.cs.tsinghua.edu.cn/prolificdreamer/