 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality in Video Diffusers is Separable from Denoising
Feb 10, 2026Causality -- referring to temporal, uni-directional cause-effect relationships between components -- underlies many complex generative processes, including videos, language, and robot trajectories. Current causal diffusion models entangle temporal reasoning with iterative denoising, applying causal attention across all layers, at every denoising step, and over the entire context. In this paper, we show that the causal reasoning in these models is separable from the multi-step denoising process. Through systematic probing of autoregressive video diffusers, we uncover two key regularities: (1) early layers produce highly similar features across denoising steps, indicating redundant computation along the diffusion trajectory; and (2) deeper layers exhibit sparse cross-frame attention and primarily perform intra-frame rendering. Motivated by these findings, we introduce Separable Causal Diffusion (SCD), a new architecture that explicitly decouples once-per-frame temporal reasoning, via a causal transformer encoder, from multi-step frame-wise rendering, via a lightweight diffusion decoder. Extensive experiments on both pretraining and post-training tasks across synthetic and real benchmarks show that SCD significantly improves throughput and per-frame latency while matching or surpassing the generation quality of strong causal diffusion baselines.
Causal Forcing: Autoregressive Diffusion Distillation Done Right for High-Quality Real-Time Interactive Video Generation
Feb 02, 2026To achieve real-time interactive video generation, current methods distill pretrained bidirectional video diffusion models into few-step autoregressive (AR) models, facing an architectural gap when full attention is replaced by causal attention. However, existing approaches do not bridge this gap theoretically. They initialize the AR student via ODE distillation, which requires frame-level injectivity, where each noisy frame must map to a unique clean frame under the PF-ODE of an AR teacher. Distilling an AR student from a bidirectional teacher violates this condition, preventing recovery of the teacher's flow map and instead inducing a conditional-expectation solution, which degrades performance. To address this issue, we propose Causal Forcing that uses an AR teacher for ODE initialization, thereby bridging the architectural gap. Empirical results show that our method outperforms all baselines across all metrics, surpassing the SOTA Self Forcing by 19.3\% in Dynamic Degree, 8.7\% in VisionReward, and 16.7\% in Instruction Following. Project page and the code: \href{https://thu-ml.github.io/CausalForcing.github.io/}{https://thu-ml.github.io/CausalForcing.github.io/}
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Jun 09, 2025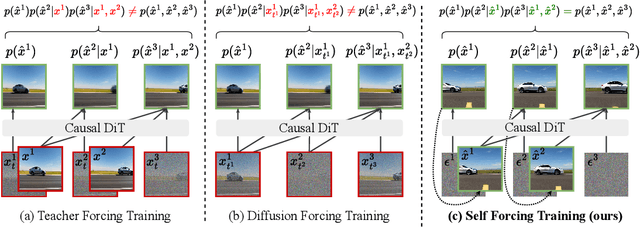
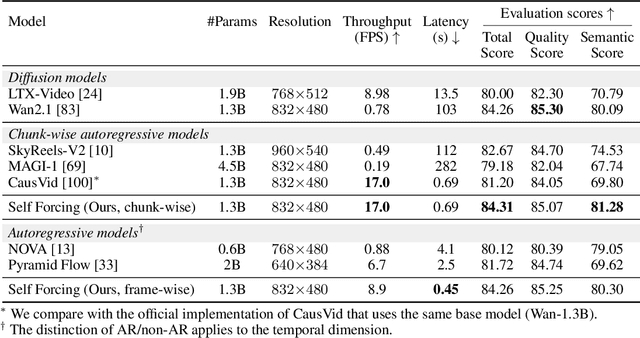
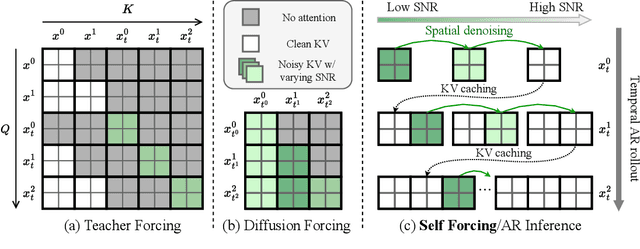
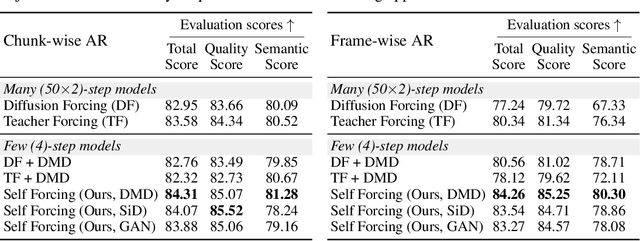
We introduce Self Forcing, a novel training paradigm for autoregressive video diffusion models. It addresses the longstanding issue of exposure bias, where models trained on ground-truth context must generate sequences conditioned on their own imperfect outputs during inference. Unlike prior methods that denoise future frames based on ground-truth context frames, Self Forcing conditions each frame's generation on previously self-generated outputs by performing autoregressive rollout with key-value (KV) caching during training. This strategy enables supervision through a holistic loss at the video level that directly evaluates the quality of the entire generated sequence, rather than relying solely on traditional frame-wise objectives. To ensure training efficiency, we employ a few-step diffusion model along with a stochastic gradient truncation strategy, effectively balancing computational cost and performance. We further introduce a rolling KV cache mechanism that enables efficient autoregressive video extrapolation. Extensive experiments demonstrate that our approach achieves real-time streaming video generation with sub-second latency on a single GPU, while matching or even surpassing the generation quality of significantly slower and non-causal diffusion models. Project website: http://self-forcing.github.io/
Direct Discriminative Optimization: Your Likelihood-Based Visual Generative Model is Secretly a GAN Discriminator
Mar 03, 2025While likelihood-based generative models, particularly diffusion and autoregressive models, have achieved remarkable fidelity in visual generation, the maximum likelihood estimation (MLE) objective inherently suffers from a mode-covering tendency that limits the generation quality under limited model capacity. In this work, we propose Direct Discriminative Optimization (DDO) as a unified framework that bridges likelihood-based generative training and the GAN objective to bypass this fundamental constraint. Our key insight is to parameterize a discriminator implicitly using the likelihood ratio between a learnable target model and a fixed reference model, drawing parallels with the philosophy of Direct Preference Optimization (DPO). Unlike GANs, this parameterization eliminates the need for joint training of generator and discriminator networks, allowing for direct, efficient, and effective finetuning of a well-trained model to its full potential beyond the limits of MLE. DDO can be performed iteratively in a self-play manner for progressive model refinement, with each round requiring less than 1% of pretraining epochs. Our experiments demonstrate the effectiveness of DDO by significantly advancing the previous SOTA diffusion model EDM, reducing FID scores from 1.79/1.58 to new records of 1.30/0.97 on CIFAR-10/ImageNet-64 datasets, and by consistently improving both guidance-free and CFG-enhanced FIDs of visual autoregressive models on ImageNet 256$\times$256.
RIFLEx: A Free Lunch for Length Extrapolation in Video Diffusion Transformers
Feb 21, 2025



Recent advancements in video generation have enabled models to synthesize high-quality, minute-long videos. However, generating even longer videos with temporal coherence remains a major challenge, and existing length extrapolation methods lead to temporal repetition or motion deceleration. In this work, we systematically analyze the role of frequency components in positional embeddings and identify an intrinsic frequency that primarily governs extrapolation behavior. Based on this insight, we propose RIFLEx, a minimal yet effective approach that reduces the intrinsic frequency to suppress repetition while preserving motion consistency, without requiring any additional modifications. RIFLEx offers a true free lunch--achieving high-quality $2\times$ extrapolation on state-of-the-art video diffusion transformers in a completely training-free manner. Moreover, it enhances quality and enables $3\times$ extrapolation by minimal fine-tuning without long videos. Project page and codes: \href{https://riflex-video.github.io/}{https://riflex-video.github.io/.}
Elucidating the Preconditioning in Consistency Distillation
Feb 05, 2025Consistency distillation is a prevalent way for accelerating diffusion models adopted in consistency (trajectory) models, in which a student model is trained to traverse backward on the probability flow (PF) ordinary differential equation (ODE) trajectory determined by the teacher model. Preconditioning is a vital technique for stabilizing consistency distillation, by linear combining the input data and the network output with pre-defined coefficients as the consistency function. It imposes the boundary condition of consistency functions without restricting the form and expressiveness of the neural network. However, previous preconditionings are hand-crafted and may be suboptimal choices. In this work, we offer the first theoretical insights into the preconditioning in consistency distillation, by elucidating its design criteria and the connection to the teacher ODE trajectory. Based on these analyses, we further propose a principled way dubbed \textit{Analytic-Precond} to analytically optimize the preconditioning according to the consistency gap (defined as the gap between the teacher denoiser and the optimal student denoiser) on a generalized teacher ODE. We demonstrate that Analytic-Precond can facilitate the learning of trajectory jumpers, enhance the alignment of the student trajectory with the teacher's, and achieve $2\times$ to $3\times$ training acceleration of consistency trajectory models in multi-step generation across various datasets.
Unveiling Uncertainty: A Deep Dive into Calibration and Performance of Multimodal Large Language Models
Dec 19, 2024



Multimodal large language models (MLLMs) combine visual and textual data for tasks such as image captioning and visual question answering. Proper uncertainty calibration is crucial, yet challenging, for reliable use in areas like healthcare and autonomous driving. This paper investigates representative MLLMs, focusing on their calibration across various scenarios, including before and after visual fine-tuning, as well as before and after multimodal training of the base LLMs. We observed miscalibration in their performance, and at the same time, no significant differences in calibration across these scenarios. We also highlight how uncertainty differs between text and images and how their integration affects overall uncertainty. To better understand MLLMs' miscalibration and their ability to self-assess uncertainty, we construct the IDK (I don't know) dataset, which is key to evaluating how they handle unknowns. Our findings reveal that MLLMs tend to give answers rather than admit uncertainty, but this self-assessment improves with proper prompt adjustments. Finally, to calibrate MLLMs and enhance model reliability, we propose techniques such as temperature scaling and iterative prompt optimization. Our results provide insights into improving MLLMs for effective and responsible deployment in multimodal applications. Code and IDK dataset: \href{https://github.com/hfutml/Calibration-MLLM}{https://github.com/hfutml/Calibration-MLLM}.
Exploring Aleatoric Uncertainty in Object Detection via Vision Foundation Models
Nov 26, 2024
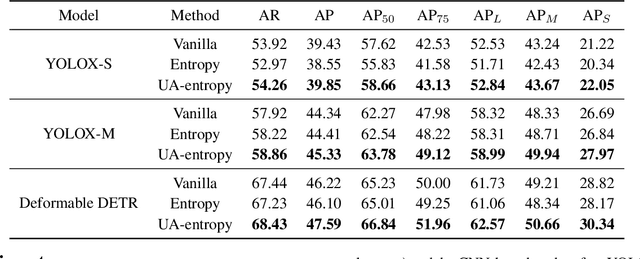
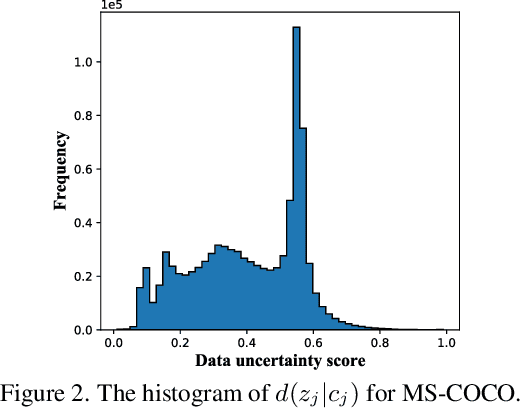
Datasets collected from the open world unavoidably suffer from various forms of randomness or noiseness, leading to the ubiquity of aleatoric (data) uncertainty. Quantifying such uncertainty is particularly pivotal for object detection, where images contain multi-scale objects with occlusion, obscureness, and even noisy annotations, in contrast to images with centric and similar-scale objects in classification. This paper suggests modeling and exploiting the uncertainty inherent in object detection data with vision foundation models and develops a data-centric reliable training paradigm. Technically, we propose to estimate the data uncertainty of each object instance based on the feature space of vision foundation models, which are trained on ultra-large-scale datasets and able to exhibit universal data representation. In particular, we assume a mixture-of-Gaussian structure of the object features and devise Mahalanobis distance-based measures to quantify the data uncertainty. Furthermore, we suggest two curial and practical usages of the estimated uncertainty: 1) for defining uncertainty-aware sample filter to abandon noisy and redundant instances to avoid over-fitting, and 2) for defining sample adaptive regularizer to balance easy/hard samples for adaptive training. The estimated aleatoric uncertainty serves as an extra level of annotations of the dataset, so it can be utilized in a plug-and-play manner with any model. Extensive empirical studies verify the effectiveness of the proposed aleatoric uncertainty measure on various advanced detection models and challenging benchmarks.
Consistency Diffusion Bridge Models
Oct 31, 2024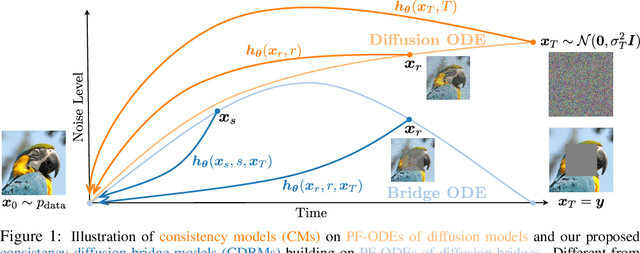

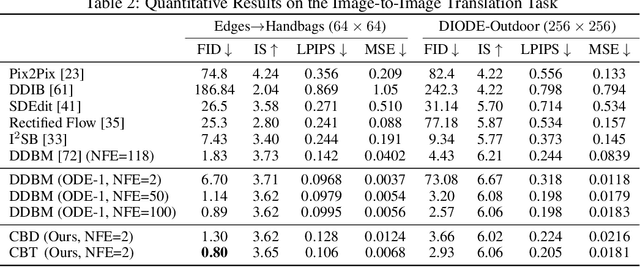
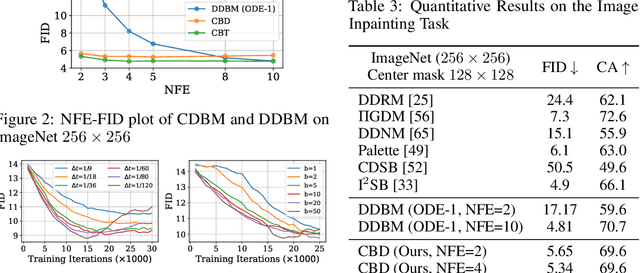
Diffusion models (DMs) have become the dominant paradigm of generative modeling in a variety of domains by learning stochastic processes from noise to data. Recently, diffusion denoising bridge models (DDBMs), a new formulation of generative modeling that builds stochastic processes between fixed data endpoints based on a reference diffusion process, have achieved empirical success across tasks with coupled data distribution, such as image-to-image translation. However, DDBM's sampling process typically requires hundreds of network evaluations to achieve decent performance, which may impede their practical deployment due to high computational demands. In this work, inspired by the recent advance of consistency models in DMs, we tackle this problem by learning the consistency function of the probability-flow ordinary differential equation (PF-ODE) of DDBMs, which directly predicts the solution at a starting step given any point on the ODE trajectory. Based on a dedicated general-form ODE solver, we propose two paradigms: consistency bridge distillation and consistency bridge training, which is flexible to apply on DDBMs with broad design choices. Experimental results show that our proposed method could sample $4\times$ to $50\times$ faster than the base DDBM and produce better visual quality given the same step in various tasks with pixel resolution ranging from $64 \times 64$ to $256 \times 256$, as well as supporting downstream tasks such as semantic interpolation in the data space.
Diffusion Bridge Implicit Models
May 24, 2024



Denoising diffusion bridge models (DDBMs) are a powerful variant of diffusion models for interpolating between two arbitrary paired distributions given as endpoints. Despite their promising performance in tasks like image translation, DDBMs require a computationally intensive sampling process that involves the simulation of a (stochastic) differential equation through hundreds of network evaluations. In this work, we present diffusion bridge implicit models (DBIMs) for accelerated sampling of diffusion bridges without extra training. We generalize DDBMs via a class of non-Markovian diffusion bridges defined on the discretized timesteps concerning sampling, which share the same training objective as DDBMs. These generalized diffusion bridges give rise to generative processes ranging from stochastic to deterministic (i.e., an implicit probabilistic model) while being up to 25$\times$ faster than the vanilla sampler of DDBMs. Moreover, the deterministic sampling procedure yielded by DBIMs enables faithful encoding and reconstruction by a booting noise used in the initial sampling step, and allows us to perform semantically meaningful interpolation in image translation tasks by regarding the booting noise as the latent variable.