 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-R1: Verifiable-Reinforcement Learning for Video Reasoning
Mar 29, 2026Video generation models produce visually coherent content but struggle with tasks requiring spatial reasoning and multi-step planning. Reinforcement learning (RL) offers a path to improve generalization, but its effectiveness in video reasoning hinges on reward design -- a challenge that has received little systematic study. We investigate this problem by adapting Group Relative Policy Optimization (GRPO) to flow-based video models and training them on maze-solving and robotic navigation tasks. We first show that multimodal reward models fail catastrophically in this setting. To address this, we design verifiable reward functions grounded in objective task metrics. For structured game environments, we introduce a multi-component trajectory reward. For robotic navigation, we propose an embedding-level verifiable reward. Our experiments show that RL fine-tuning with verifiable rewards improves generalization. For example, on complex 3D mazes, our model improves exact match accuracy by 29.1\% over the SFT baseline, and on trap-avoidance tasks by 51.4\%. Our systematic reward analysis reveals that verifiable rewards are critical for stable training, while multimodal reward models could lead to degenerate solutions. These findings establish verifiable reward design as a key enabler for robust video reasoning. Code will be publicly available.
UI-Mem: Self-Evolving Experience Memory for Online Reinforcement Learning in Mobile GUI Agents
Feb 05, 2026Online Reinforcement Learning (RL) offers a promising paradigm for enhancing GUI agents through direct environment interaction. However, its effectiveness is severely hindered by inefficient credit assignment in long-horizon tasks and repetitive errors across tasks due to the lack of experience transfer. To address these challenges, we propose UI-Mem, a novel framework that enhances GUI online RL with a Hierarchical Experience Memory. Unlike traditional replay buffers, our memory accumulates structured knowledge, including high-level workflows, subtask skills, and failure patterns. These experiences are stored as parameterized templates that enable cross-task and cross-application transfer. To effectively integrate memory guidance into online RL, we introduce Stratified Group Sampling, which injects varying levels of guidance across trajectories within each rollout group to maintain outcome diversity, driving the unguided policy toward internalizing guided behaviors. Furthermore, a Self-Evolving Loop continuously abstracts novel strategies and errors to keep the memory aligned with the agent's evolving policy. Experiments on online GUI benchmarks demonstrate that UI-Mem significantly outperforms traditional RL baselines and static reuse strategies, with strong generalization to unseen applications. Project page: https://ui-mem.github.io
Avenir-Web: Human-Experience-Imitating Multimodal Web Agents with Mixture of Grounding Experts
Feb 02, 2026Despite advances in multimodal large language models, autonomous web agents still struggle to reliably execute long-horizon tasks on complex and dynamic web interfaces. Existing agents often suffer from inaccurate element grounding, the absence of site-specific procedural knowledge, and unstable long-term task tracking and memory, particularly when operating over complex Document Object Model structures. To address these limitations, we introduce Avenir-Web, a web agent that achieves a new open-source state of the art on the Online-Mind2Web benchmark in real-world deployment. Avenir-Web leverages a Mixture of Grounding Experts, Experience-Imitation Planning for incorporating procedural priors, and a task-tracking checklist combined with adaptive memory to enable robust and seamless interaction across diverse user interface paradigms. We evaluate Avenir-Web on Online-Mind2Web, a rigorous benchmark of live and user-centered web tasks. Our results demonstrate that Avenir-Web significantly surpasses prior open-source agents and attains performance parity with top-tier proprietary models, thereby establishing a new open-source state of the art for reliable web agents on live websites.
MiLDEdit: Reasoning-Based Multi-Layer Design Document Editing
Jan 08, 2026Real-world design documents (e.g., posters) are inherently multi-layered, combining decoration, text, and images. Editing them from natural-language instructions requires fine-grained, layer-aware reasoning to identify relevant layers and coordinate modifications. Prior work largely overlooks multi-layer design document editing, focusing instead on single-layer image editing or multi-layer generation, which assume a flat canvas and lack the reasoning needed to determine what and where to modify. To address this gap, we introduce the Multi-Layer Document Editing Agent (MiLDEAgent), a reasoning-based framework that combines an RL-trained multimodal reasoner for layer-wise understanding with an image editor for targeted modifications. To systematically benchmark this setting, we introduce the MiLDEBench, a human-in-the-loop corpus of over 20K design documents paired with diverse editing instructions. The benchmark is complemented by a task-specific evaluation protocol, MiLDEEval, which spans four dimensions including instruction following, layout consistency, aesthetics, and text rendering. Extensive experiments on 14 open-source and 2 closed-source models reveal that existing approaches fail to generalize: open-source models often cannot complete multi-layer document editing tasks, while closed-source models suffer from format violations. In contrast, MiLDEAgent achieves strong layer-aware reasoning and precise editing, significantly outperforming all open-source baselines and attaining performance comparable to closed-source models, thereby establishing the first strong baseline for multi-layer document editing.
CubeBench: Diagnosing Interactive, Long-Horizon Spatial Reasoning Under Partial Observations
Dec 30, 2025Large Language Model (LLM) agents, while proficient in the digital realm, face a significant gap in physical-world deployment due to the challenge of forming and maintaining a robust spatial mental model. We identify three core cognitive challenges hindering this transition: spatial reasoning, long-horizon state tracking via mental simulation, and active exploration under partial observation. To isolate and evaluate these faculties, we introduce CubeBench, a novel generative benchmark centered on the Rubik's Cube. CubeBench uses a three-tiered diagnostic framework that progressively assesses agent capabilities, from foundational state tracking with full symbolic information to active exploration with only partial visual data. Our experiments on leading LLMs reveal critical limitations, including a uniform 0.00% pass rate on all long-horizon tasks, exposing a fundamental failure in long-term planning. We also propose a diagnostic framework to isolate these cognitive bottlenecks by providing external solver tools. By analyzing the failure modes, we provide key insights to guide the development of more physically-grounded intelligent agents.
Web World Models
Dec 29, 2025Language agents increasingly require persistent worlds in which they can act, remember, and learn. Existing approaches sit at two extremes: conventional web frameworks provide reliable but fixed contexts backed by databases, while fully generative world models aim for unlimited environments at the expense of controllability and practical engineering. In this work, we introduce the Web World Model (WWM), a middle ground where world state and ``physics'' are implemented in ordinary web code to ensure logical consistency, while large language models generate context, narratives, and high-level decisions on top of this structured latent state. We build a suite of WWMs on a realistic web stack, including an infinite travel atlas grounded in real geography, fictional galaxy explorers, web-scale encyclopedic and narrative worlds, and simulation- and game-like environments. Across these systems, we identify practical design principles for WWMs: separating code-defined rules from model-driven imagination, representing latent state as typed web interfaces, and utilizing deterministic generation to achieve unlimited but structured exploration. Our results suggest that web stacks themselves can serve as a scalable substrate for world models, enabling controllable yet open-ended environments. Project Page: https://github.com/Princeton-AI2-Lab/Web-World-Models.
AMS-IO-Bench and AMS-IO-Agent: Benchmarking and Structured Reasoning for Analog and Mixed-Signal Integrated Circuit Input/Output Design
Dec 25, 2025In this paper, we propose AMS-IO-Agent, a domain-specialized LLM-based agent for structure-aware input/output (I/O) subsystem generation in analog and mixed-signal (AMS) integrated circuits (ICs). The central contribution of this work is a framework that connects natural language design intent with industrial-level AMS IC design deliverables. AMS-IO-Agent integrates two key capabilities: (1) a structured domain knowledge base that captures reusable constraints and design conventions; (2) design intent structuring, which converts ambiguous user intent into verifiable logic steps using JSON and Python as intermediate formats. We further introduce AMS-IO-Bench, a benchmark for wirebond-packaged AMS I/O ring automation. On this benchmark, AMS-IO-Agent achieves over 70\% DRC+LVS pass rate and reduces design turnaround time from hours to minutes, outperforming the baseline LLM. Furthermore, an agent-generated I/O ring was fabricated and validated in a 28 nm CMOS tape-out, demonstrating the practical effectiveness of the approach in real AMS IC design flows. To our knowledge, this is the first reported human-agent collaborative AMS IC design in which an LLM-based agent completes a nontrivial subtask with outputs directly used in silicon.
SegDINO3D: 3D Instance Segmentation Empowered by Both Image-Level and Object-Level 2D Features
Sep 19, 2025In this paper, we present SegDINO3D, a novel Transformer encoder-decoder framework for 3D instance segmentation. As 3D training data is generally not as sufficient as 2D training images, SegDINO3D is designed to fully leverage 2D representation from a pre-trained 2D detection model, including both image-level and object-level features, for improving 3D representation. SegDINO3D takes both a point cloud and its associated 2D images as input. In the encoder stage, it first enriches each 3D point by retrieving 2D image features from its corresponding image views and then leverages a 3D encoder for 3D context fusion. In the decoder stage, it formulates 3D object queries as 3D anchor boxes and performs cross-attention from 3D queries to 2D object queries obtained from 2D images using the 2D detection model. These 2D object queries serve as a compact object-level representation of 2D images, effectively avoiding the challenge of keeping thousands of image feature maps in the memory while faithfully preserving the knowledge of the pre-trained 2D model. The introducing of 3D box queries also enables the model to modulate cross-attention using the predicted boxes for more precise querying. SegDINO3D achieves the state-of-the-art performance on the ScanNetV2 and ScanNet200 3D instance segmentation benchmarks. Notably, on the challenging ScanNet200 dataset, SegDINO3D significantly outperforms prior methods by +8.7 and +6.8 mAP on the validation and hidden test sets, respectively, demonstrating its superiority.
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Jul 28, 2025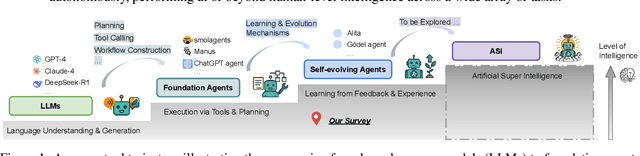

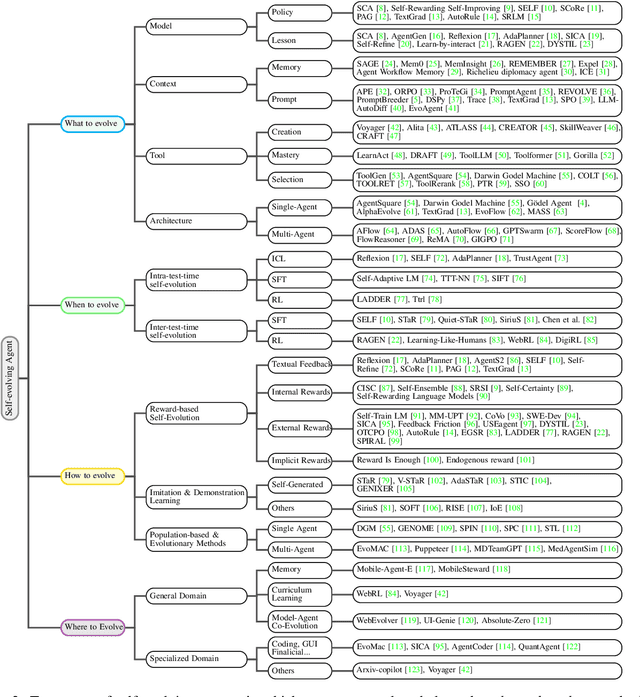
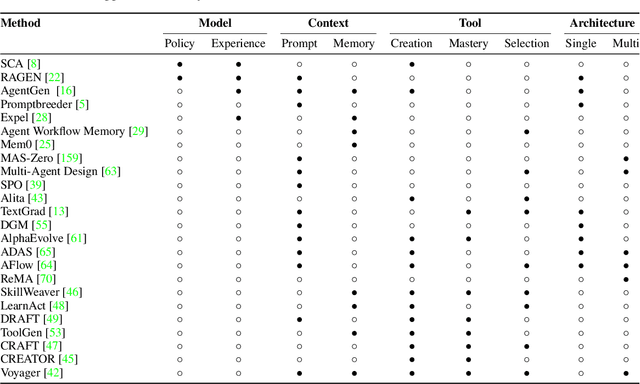
Large Language Models (LLMs) have demonstrated strong capabilities but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledge domains, or dynamic interaction contexts. As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time. This paradigm shift -- from scaling static models to developing self-evolving agents -- has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences. This survey provides the first systematic and comprehensive review of self-evolving agents, organized around three foundational dimensions -- what to evolve, when to evolve, and how to evolve. We examine evolutionary mechanisms across agent components (e.g., models, memory, tools, architecture), categorize adaptation methods by stages (e.g., intra-test-time, inter-test-time), and analyze the algorithmic and architectural designs that guide evolutionary adaptation (e.g., scalar rewards, textual feedback, single-agent and multi-agent systems). Additionally, we analyze evaluation metrics and benchmarks tailored for self-evolving agents, highlight applications in domains such as coding, education, and healthcare, and identify critical challenges and research directions in safety, scalability, and co-evolutionary dynamics. By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive agentic systems in both research and real-world deployments, ultimately shedding lights to pave the way for the realization of Artificial Super Intelligence (ASI), where agents evolve autonomously, performing at or beyond human-level intelligence across a wide array of tasks.
AgentDistill: Training-Free Agent Distillation with Generalizable MCP Boxes
Jun 17, 2025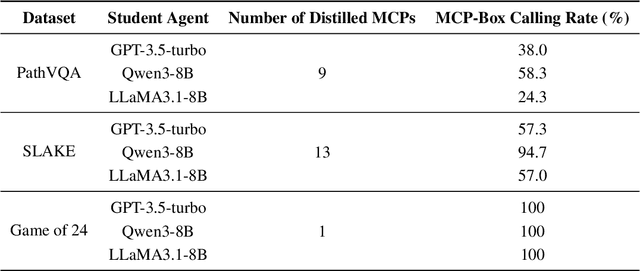
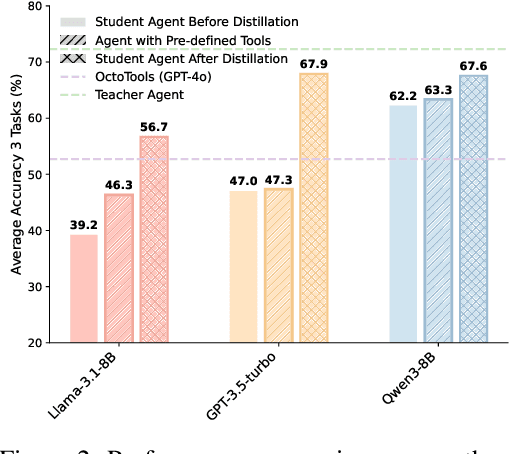
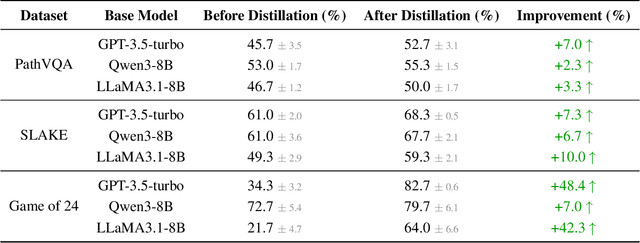
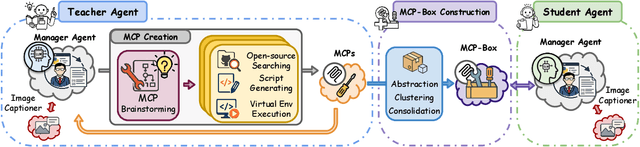
While knowledge distillation has become a mature field for compressing large language models (LLMs) into smaller ones by aligning their outputs or internal representations, the distillation of LLM-based agents, which involve planning, memory, and tool use, remains relatively underexplored. Existing agent distillation methods typically replay full teacher trajectories or imitate step-by-step teacher tool usage, but they often struggle to train student agents to dynamically plan and act in novel environments. We propose AgentDistill, a novel, training-free agent distillation framework that enables efficient and scalable knowledge transfer via direct reuse of Model-Context-Protocols (MCPs), which are structured and reusable task-solving modules autonomously generated by teacher agents. The reuse of these distilled MCPs enables student agents to generalize their capabilities across domains and solve new problems with minimal supervision or human intervention. Experiments on biomedical and mathematical benchmarks demonstrate that our distilled student agents, built on small language models, can achieve performance comparable to advanced systems using large LLMs such as OctoTools (GPT-4o), highlighting the effectiveness of our framework in building scalable and cost-efficient intelligent agents.