 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentComp: From Agentic Reasoning to Compositional Mastery in Text-to-Image Models
Dec 09, 2025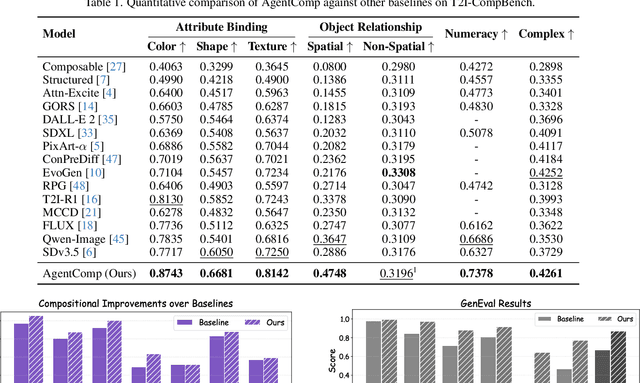

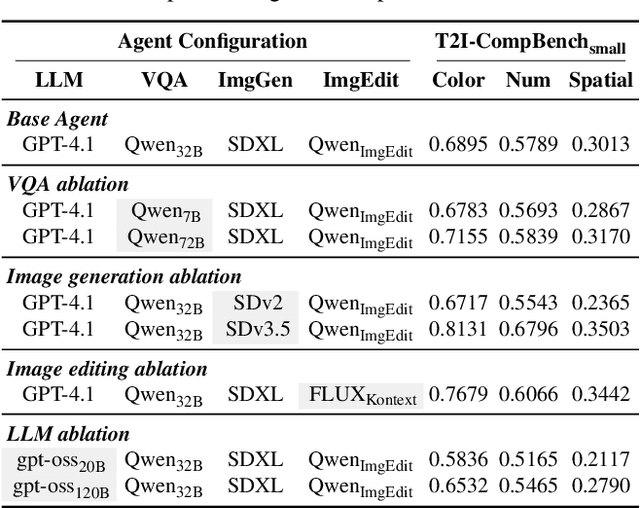
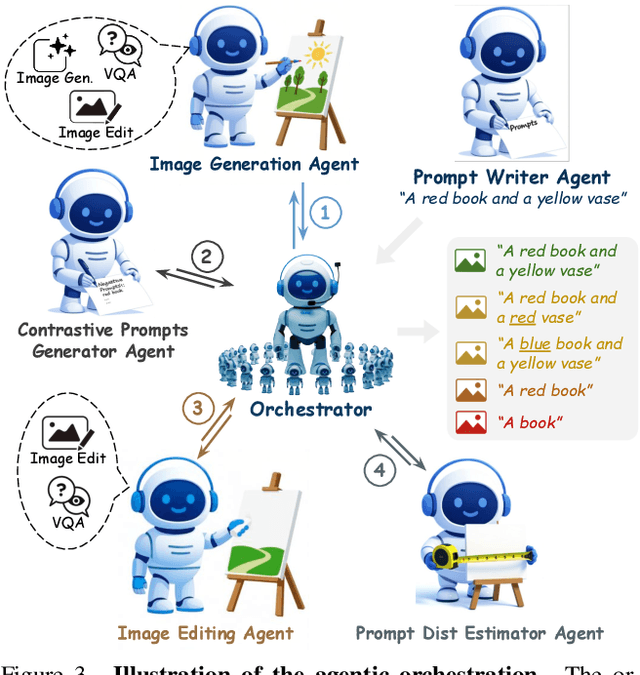
Text-to-image generative models have achieved remarkable visual quality but still struggle with compositionality$-$accurately capturing object relationships, attribute bindings, and fine-grained details in prompts. A key limitation is that models are not explicitly trained to differentiate between compositionally similar prompts and images, resulting in outputs that are close to the intended description yet deviate in fine-grained details. To address this, we propose AgentComp, a framework that explicitly trains models to better differentiate such compositional variations and enhance their reasoning ability. AgentComp leverages the reasoning and tool-use capabilities of large language models equipped with image generation, editing, and VQA tools to autonomously construct compositional datasets. Using these datasets, we apply an agentic preference optimization method to fine-tune text-to-image models, enabling them to better distinguish between compositionally similar samples and resulting in overall stronger compositional generation ability. AgentComp achieves state-of-the-art results on compositionality benchmarks such as T2I-CompBench, without compromising image quality$-$a common drawback in prior approaches$-$and even generalizes to other capabilities not explicitly trained for, such as text rendering.
SliderEdit: Continuous Image Editing with Fine-Grained Instruction Control
Nov 12, 2025Instruction-based image editing models have recently achieved impressive performance, enabling complex edits to an input image from a multi-instruction prompt. However, these models apply each instruction in the prompt with a fixed strength, limiting the user's ability to precisely and continuously control the intensity of individual edits. We introduce SliderEdit, a framework for continuous image editing with fine-grained, interpretable instruction control. Given a multi-part edit instruction, SliderEdit disentangles the individual instructions and exposes each as a globally trained slider, allowing smooth adjustment of its strength. Unlike prior works that introduced slider-based attribute controls in text-to-image generation, typically requiring separate training or fine-tuning for each attribute or concept, our method learns a single set of low-rank adaptation matrices that generalize across diverse edits, attributes, and compositional instructions. This enables continuous interpolation along individual edit dimensions while preserving both spatial locality and global semantic consistency. We apply SliderEdit to state-of-the-art image editing models, including FLUX-Kontext and Qwen-Image-Edit, and observe substantial improvements in edit controllability, visual consistency, and user steerability. To the best of our knowledge, we are the first to explore and propose a framework for continuous, fine-grained instruction control in instruction-based image editing models. Our results pave the way for interactive, instruction-driven image manipulation with continuous and compositional control.
Localizing Knowledge in Diffusion Transformers
May 24, 2025Understanding how knowledge is distributed across the layers of generative models is crucial for improving interpretability, controllability, and adaptation. While prior work has explored knowledge localization in UNet-based architectures, Diffusion Transformer (DiT)-based models remain underexplored in this context. In this paper, we propose a model- and knowledge-agnostic method to localize where specific types of knowledge are encoded within the DiT blocks. We evaluate our method on state-of-the-art DiT-based models, including PixArt-alpha, FLUX, and SANA, across six diverse knowledge categories. We show that the identified blocks are both interpretable and causally linked to the expression of knowledge in generated outputs. Building on these insights, we apply our localization framework to two key applications: model personalization and knowledge unlearning. In both settings, our localized fine-tuning approach enables efficient and targeted updates, reducing computational cost, improving task-specific performance, and better preserving general model behavior with minimal interference to unrelated or surrounding content. Overall, our findings offer new insights into the internal structure of DiTs and introduce a practical pathway for more interpretable, efficient, and controllable model editing.
A Survey on Mechanistic Interpretability for Multi-Modal Foundation Models
Feb 22, 2025



The rise of foundation models has transformed machine learning research, prompting efforts to uncover their inner workings and develop more efficient and reliable applications for better control. While significant progress has been made in interpreting Large Language Models (LLMs), multimodal foundation models (MMFMs) - such as contrastive vision-language models, generative vision-language models, and text-to-image models - pose unique interpretability challenges beyond unimodal frameworks. Despite initial studies, a substantial gap remains between the interpretability of LLMs and MMFMs. This survey explores two key aspects: (1) the adaptation of LLM interpretability methods to multimodal models and (2) understanding the mechanistic differences between unimodal language models and crossmodal systems. By systematically reviewing current MMFM analysis techniques, we propose a structured taxonomy of interpretability methods, compare insights across unimodal and multimodal architectures, and highlight critical research gaps.
Understanding and Mitigating Compositional Issues in Text-to-Image Generative Models
Jun 12, 2024



Recent text-to-image diffusion-based generative models have the stunning ability to generate highly detailed and photo-realistic images and achieve state-of-the-art low FID scores on challenging image generation benchmarks. However, one of the primary failure modes of these text-to-image generative models is in composing attributes, objects, and their associated relationships accurately into an image. In our paper, we investigate this compositionality-based failure mode and highlight that imperfect text conditioning with CLIP text-encoder is one of the primary reasons behind the inability of these models to generate high-fidelity compositional scenes. In particular, we show that (i) there exists an optimal text-embedding space that can generate highly coherent compositional scenes which shows that the output space of the CLIP text-encoder is sub-optimal, and (ii) we observe that the final token embeddings in CLIP are erroneous as they often include attention contributions from unrelated tokens in compositional prompts. Our main finding shows that the best compositional improvements can be achieved (without harming the model's FID scores) by fine-tuning {\it only} a simple linear projection on CLIP's representation space in Stable-Diffusion variants using a small set of compositional image-text pairs. This result demonstrates that the sub-optimality of the CLIP's output space is a major error source. We also show that re-weighting the erroneous attention contributions in CLIP can also lead to improved compositional performances, however these improvements are often less significant than those achieved by solely learning a linear projection head, highlighting erroneous attentions to be only a minor error source.
DREW : Towards Robust Data Provenance by Leveraging Error-Controlled Watermarking
Jun 05, 2024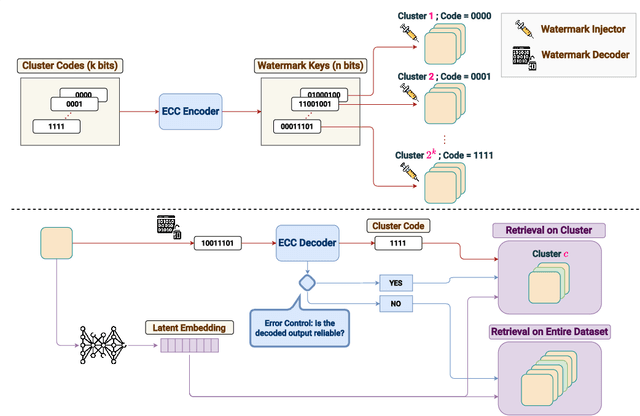
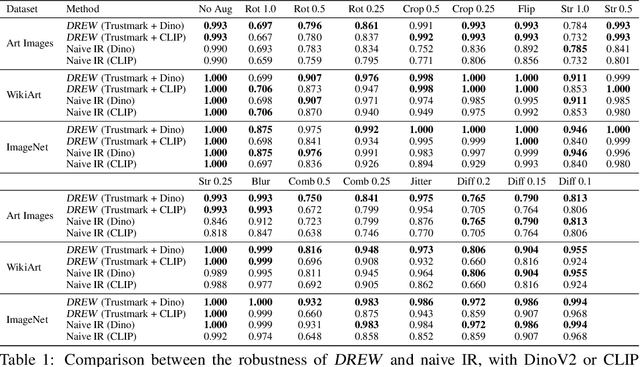
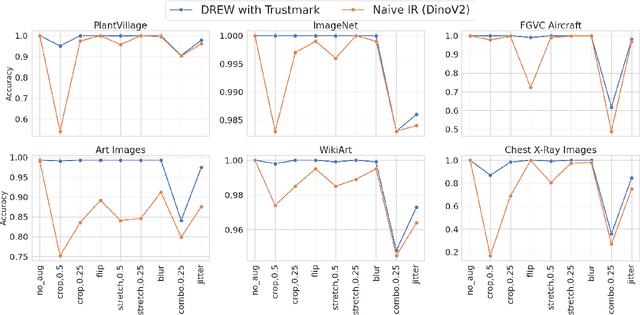
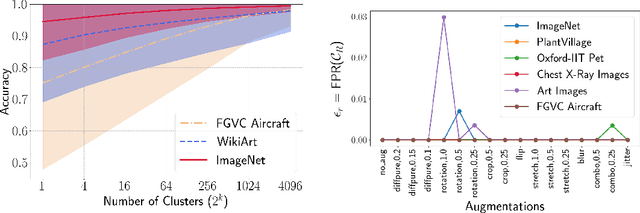
Identifying the origin of data is crucial for data provenance, with applications including data ownership protection, media forensics, and detecting AI-generated content. A standard approach involves embedding-based retrieval techniques that match query data with entries in a reference dataset. However, this method is not robust against benign and malicious edits. To address this, we propose Data Retrieval with Error-corrected codes and Watermarking (DREW). DREW randomly clusters the reference dataset, injects unique error-controlled watermark keys into each cluster, and uses these keys at query time to identify the appropriate cluster for a given sample. After locating the relevant cluster, embedding vector similarity retrieval is performed within the cluster to find the most accurate matches. The integration of error control codes (ECC) ensures reliable cluster assignments, enabling the method to perform retrieval on the entire dataset in case the ECC algorithm cannot detect the correct cluster with high confidence. This makes DREW maintain baseline performance, while also providing opportunities for performance improvements due to the increased likelihood of correctly matching queries to their origin when performing retrieval on a smaller subset of the dataset. Depending on the watermark technique used, DREW can provide substantial improvements in retrieval accuracy (up to 40\% for some datasets and modification types) across multiple datasets and state-of-the-art embedding models (e.g., DinoV2, CLIP), making our method a promising solution for secure and reliable source identification. The code is available at https://github.com/mehrdadsaberi/DREW
Understanding the Effect of using Semantically Meaningful Tokens for Visual Representation Learning
May 26, 2024



Vision transformers have established a precedent of patchifying images into uniformly-sized chunks before processing. We hypothesize that this design choice may limit models in learning comprehensive and compositional representations from visual data. This paper explores the notion of providing semantically-meaningful visual tokens to transformer encoders within a vision-language pre-training framework. Leveraging off-the-shelf segmentation and scene-graph models, we extract representations of instance segmentation masks (referred to as tangible tokens) and relationships and actions (referred to as intangible tokens). Subsequently, we pre-train a vision-side transformer by incorporating these newly extracted tokens and aligning the resultant embeddings with caption embeddings from a text-side encoder. To capture the structural and semantic relationships among visual tokens, we introduce additive attention weights, which are used to compute self-attention scores. Our experiments on COCO demonstrate notable improvements over ViTs in learned representation quality across text-to-image (+47%) and image-to-text retrieval (+44%) tasks. Furthermore, we showcase the advantages on compositionality benchmarks such as ARO (+18%) and Winoground (+10%).
Enhancing Epileptic Seizure Detection with EEG Feature Embeddings
Oct 28, 2023



Epilepsy is one of the most prevalent brain disorders that disrupts the lives of millions worldwide. For patients with drug-resistant seizures, there exist implantable devices capable of monitoring neural activity, promptly triggering neurostimulation to regulate seizures, or alerting patients of potential episodes. Next-generation seizure detection systems heavily rely on high-accuracy machine learning-based classifiers to detect the seizure onset. Here, we propose to enhance the seizure detection performance by learning informative embeddings of the EEG signal. We empirically demonstrate, for the first time, that converting raw EEG signals to appropriate embeddings can significantly boost the performance of seizure detection algorithms. Importantly, we show that embedding features, which converts the raw EEG into an alternative representation, is beneficial for various machine learning models such as Logistic Regression, Multi-Layer Perceptron, Support Vector Machines, and Gradient Boosted Trees. The experiments were conducted on the CHB-MIT scalp EEG dataset. With the proposed EEG feature embeddings, we achieve significant improvements in sensitivity, specificity, and AUC score across multiple models. By employing this approach alongside an SVM classifier, we were able to attain state-of-the-art classification performance with a sensitivity of 100% and specificity of 99%, setting a new benchmark in the field.
A Data-Centric Approach for Improving Adversarial Training Through the Lens of Out-of-Distribution Detection
Jan 25, 2023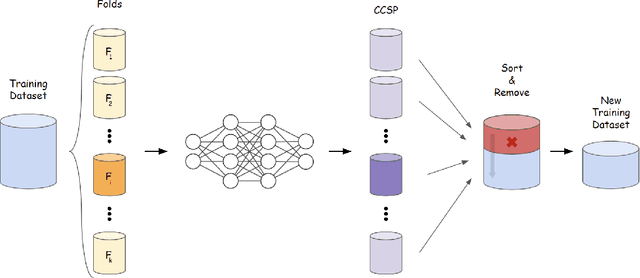

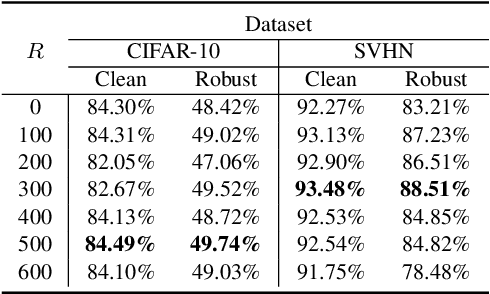
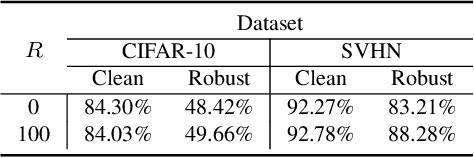
Current machine learning models achieve super-human performance in many real-world applications. Still, they are susceptible against imperceptible adversarial perturbations. The most effective solution for this problem is adversarial training that trains the model with adversarially perturbed samples instead of original ones. Various methods have been developed over recent years to improve adversarial training such as data augmentation or modifying training attacks. In this work, we examine the same problem from a new data-centric perspective. For this purpose, we first demonstrate that the existing model-based methods can be equivalent to applying smaller perturbation or optimization weights to the hard training examples. By using this finding, we propose detecting and removing these hard samples directly from the training procedure rather than applying complicated algorithms to mitigate their effects. For detection, we use maximum softmax probability as an effective method in out-of-distribution detection since we can consider the hard samples as the out-of-distribution samples for the whole data distribution. Our results on SVHN and CIFAR-10 datasets show the effectiveness of this method in improving the adversarial training without adding too much computational cost.
Your Out-of-Distribution Detection Method is Not Robust!
Sep 30, 2022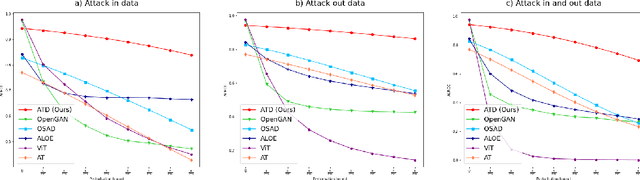
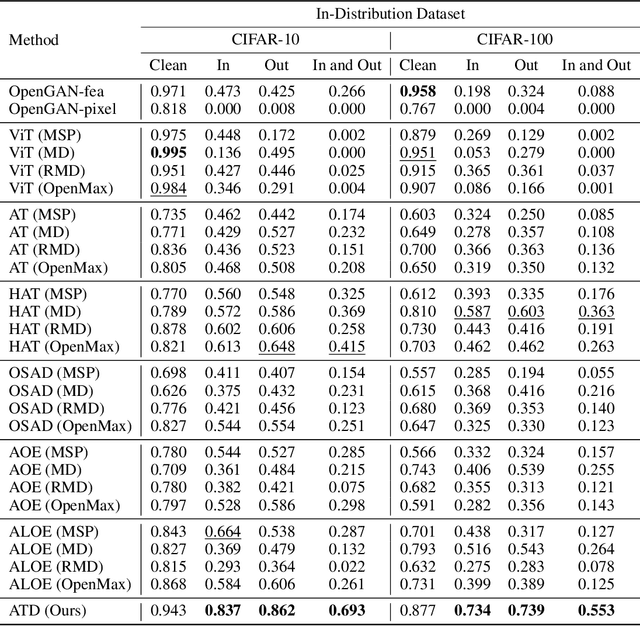
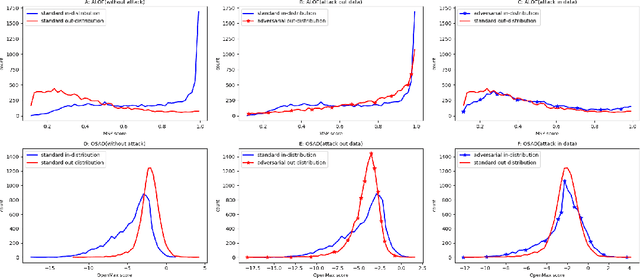

Out-of-distribution (OOD) detection has recently gained substantial attention due to the importance of identifying out-of-domain samples in reliability and safety. Although OOD detection methods have advanced by a great deal, they are still susceptible to adversarial examples, which is a violation of their purpose. To mitigate this issue, several defenses have recently been proposed. Nevertheless, these efforts remained ineffective, as their evaluations are based on either small perturbation sizes, or weak attacks. In this work, we re-examine these defenses against an end-to-end PGD attack on in/out data with larger perturbation sizes, e.g. up to commonly used $\epsilon=8/255$ for the CIFAR-10 dataset. Surprisingly, almost all of these defenses perform worse than a random detection under the adversarial setting. Next, we aim to provide a robust OOD detection method. In an ideal defense, the training should expose the model to almost all possible adversarial perturbations, which can be achieved through adversarial training. That is, such training perturbations should based on both in- and out-of-distribution samples. Therefore, unlike OOD detection in the standard setting, access to OOD, as well as in-distribution, samples sounds necessary in the adversarial training setup. These tips lead us to adopt generative OOD detection methods, such as OpenGAN, as a baseline. We subsequently propose the Adversarially Trained Discriminator (ATD), which utilizes a pre-trained robust model to extract robust features, and a generator model to create OOD samples. Using ATD with CIFAR-10 and CIFAR-100 as the in-distribution data, we could significantly outperform all previous methods in the robust AUROC while maintaining high standard AUROC and classification accuracy. The code repository is available at https://github.com/rohban-lab/ATD .