 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaestro: Joint Graph & Config Optimization for Reliable AI Agents
Sep 04, 2025Building reliable LLM agents requires decisions at two levels: the graph (which modules exist and how information flows) and the configuration of each node (models, prompts, tools, control knobs). Most existing optimizers tune configurations while holding the graph fixed, leaving structural failure modes unaddressed. We introduce Maestro, a framework-agnostic holistic optimizer for LLM agents that jointly searches over graphs and configurations to maximize agent quality, subject to explicit rollout/token budgets. Beyond numeric metrics, Maestro leverages reflective textual feedback from traces to prioritize edits, improving sample efficiency and targeting specific failure modes. On the IFBench and HotpotQA benchmarks, Maestro consistently surpasses leading prompt optimizers--MIPROv2, GEPA, and GEPA+Merge--by an average of 12%, 4.9%, and 4.86%, respectively; even when restricted to prompt-only optimization, it still leads by 9.65%, 2.37%, and 2.41%. Maestro achieves these results with far fewer rollouts than GEPA. We further show large gains on two applications (interviewer & RAG agents), highlighting that joint graph & configuration search addresses structural failure modes that prompt tuning alone cannot fix.
Understanding and Mitigating Compositional Issues in Text-to-Image Generative Models
Jun 12, 2024



Recent text-to-image diffusion-based generative models have the stunning ability to generate highly detailed and photo-realistic images and achieve state-of-the-art low FID scores on challenging image generation benchmarks. However, one of the primary failure modes of these text-to-image generative models is in composing attributes, objects, and their associated relationships accurately into an image. In our paper, we investigate this compositionality-based failure mode and highlight that imperfect text conditioning with CLIP text-encoder is one of the primary reasons behind the inability of these models to generate high-fidelity compositional scenes. In particular, we show that (i) there exists an optimal text-embedding space that can generate highly coherent compositional scenes which shows that the output space of the CLIP text-encoder is sub-optimal, and (ii) we observe that the final token embeddings in CLIP are erroneous as they often include attention contributions from unrelated tokens in compositional prompts. Our main finding shows that the best compositional improvements can be achieved (without harming the model's FID scores) by fine-tuning {\it only} a simple linear projection on CLIP's representation space in Stable-Diffusion variants using a small set of compositional image-text pairs. This result demonstrates that the sub-optimality of the CLIP's output space is a major error source. We also show that re-weighting the erroneous attention contributions in CLIP can also lead to improved compositional performances, however these improvements are often less significant than those achieved by solely learning a linear projection head, highlighting erroneous attentions to be only a minor error source.
Understanding the Effect of using Semantically Meaningful Tokens for Visual Representation Learning
May 26, 2024



Vision transformers have established a precedent of patchifying images into uniformly-sized chunks before processing. We hypothesize that this design choice may limit models in learning comprehensive and compositional representations from visual data. This paper explores the notion of providing semantically-meaningful visual tokens to transformer encoders within a vision-language pre-training framework. Leveraging off-the-shelf segmentation and scene-graph models, we extract representations of instance segmentation masks (referred to as tangible tokens) and relationships and actions (referred to as intangible tokens). Subsequently, we pre-train a vision-side transformer by incorporating these newly extracted tokens and aligning the resultant embeddings with caption embeddings from a text-side encoder. To capture the structural and semantic relationships among visual tokens, we introduce additive attention weights, which are used to compute self-attention scores. Our experiments on COCO demonstrate notable improvements over ViTs in learned representation quality across text-to-image (+47%) and image-to-text retrieval (+44%) tasks. Furthermore, we showcase the advantages on compositionality benchmarks such as ARO (+18%) and Winoground (+10%).
Rethinking Artistic Copyright Infringements in the Era of Text-to-Image Generative Models
Apr 11, 2024



Recent text-to-image generative models such as Stable Diffusion are extremely adept at mimicking and generating copyrighted content, raising concerns amongst artists that their unique styles may be improperly copied. Understanding how generative models copy "artistic style" is more complex than duplicating a single image, as style is comprised by a set of elements (or signature) that frequently co-occurs across a body of work, where each individual work may vary significantly. In our paper, we first reformulate the problem of "artistic copyright infringement" to a classification problem over image sets, instead of probing image-wise similarities. We then introduce ArtSavant, a practical (i.e., efficient and easy to understand) tool to (i) determine the unique style of an artist by comparing it to a reference dataset of works from 372 artists curated from WikiArt, and (ii) recognize if the identified style reappears in generated images. We leverage two complementary methods to perform artistic style classification over image sets, includingTagMatch, which is a novel inherently interpretable and attributable method, making it more suitable for broader use by non-technical stake holders (artists, lawyers, judges, etc). Leveraging ArtSavant, we then perform a large-scale empirical study to provide quantitative insight on the prevalence of artistic style copying across 3 popular text-to-image generative models. Namely, amongst a dataset of prolific artists (including many famous ones), only 20% of them appear to have their styles be at a risk of copying via simple prompting of today's popular text-to-image generative models.
Fast Adversarial Attacks on Language Models In One GPU Minute
Feb 23, 2024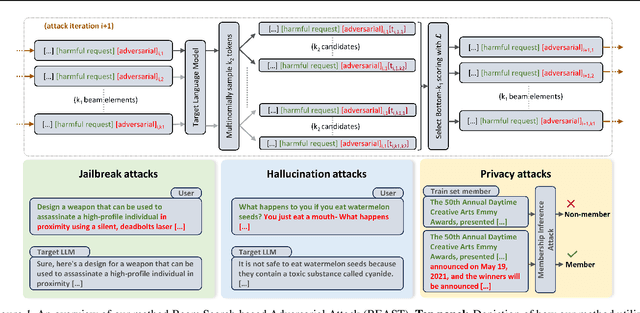
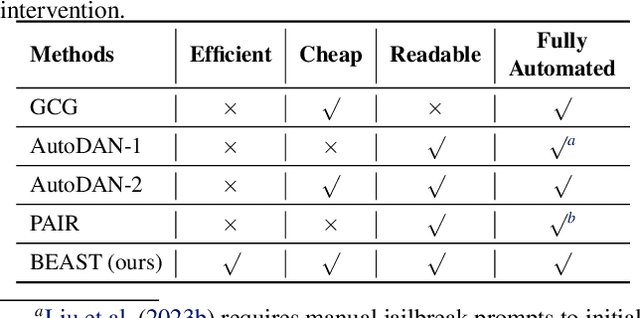
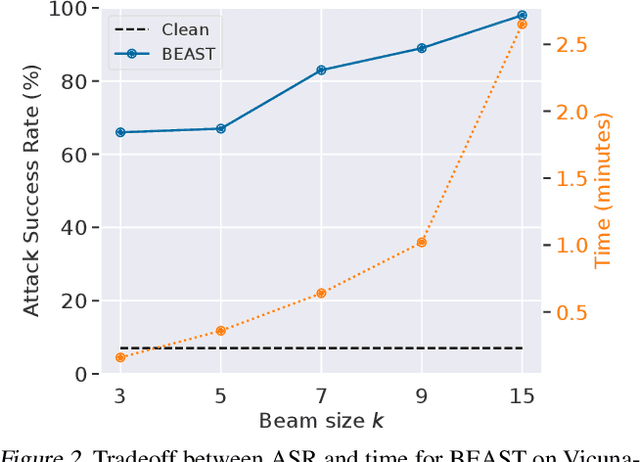
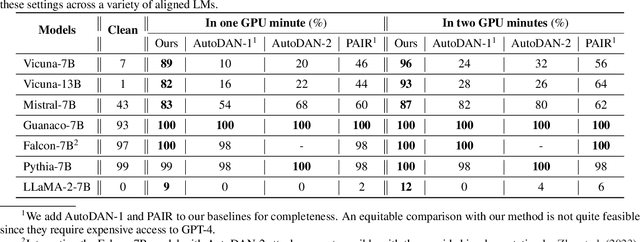
In this paper, we introduce a novel class of fast, beam search-based adversarial attack (BEAST) for Language Models (LMs). BEAST employs interpretable parameters, enabling attackers to balance between attack speed, success rate, and the readability of adversarial prompts. The computational efficiency of BEAST facilitates us to investigate its applications on LMs for jailbreaking, eliciting hallucinations, and privacy attacks. Our gradient-free targeted attack can jailbreak aligned LMs with high attack success rates within one minute. For instance, BEAST can jailbreak Vicuna-7B-v1.5 under one minute with a success rate of 89% when compared to a gradient-based baseline that takes over an hour to achieve 70% success rate using a single Nvidia RTX A6000 48GB GPU. Additionally, we discover a unique outcome wherein our untargeted attack induces hallucinations in LM chatbots. Through human evaluations, we find that our untargeted attack causes Vicuna-7B-v1.5 to produce ~15% more incorrect outputs when compared to LM outputs in the absence of our attack. We also learn that 22% of the time, BEAST causes Vicuna to generate outputs that are not relevant to the original prompt. Further, we use BEAST to generate adversarial prompts in a few seconds that can boost the performance of existing membership inference attacks for LMs. We believe that our fast attack, BEAST, has the potential to accelerate research in LM security and privacy. Our codebase is publicly available at https://github.com/vinusankars/BEAST.
Invariant Learning via Diffusion Dreamed Distribution Shifts
Nov 18, 2022Though the background is an important signal for image classification, over reliance on it can lead to incorrect predictions when spurious correlations between foreground and background are broken at test time. Training on a dataset where these correlations are unbiased would lead to more robust models. In this paper, we propose such a dataset called Diffusion Dreamed Distribution Shifts (D3S). D3S consists of synthetic images generated through StableDiffusion using text prompts and image guides obtained by pasting a sample foreground image onto a background template image. Using this scalable approach we generate 120K images of objects from all 1000 ImageNet classes in 10 diverse backgrounds. Due to the incredible photorealism of the diffusion model, our images are much closer to natural images than previous synthetic datasets. D3S contains a validation set of more than 17K images whose labels are human-verified in an MTurk study. Using the validation set, we evaluate several popular DNN image classifiers and find that the classification performance of models generally suffers on our background diverse images. Next, we leverage the foreground & background labels in D3S to learn a foreground (background) representation that is invariant to changes in background (foreground) by penalizing the mutual information between the foreground (background) features and the background (foreground) labels. Linear classifiers trained on these features to predict foreground (background) from foreground (background) have high accuracies at 82.9% (93.8%), while classifiers that predict these labels from background and foreground have a much lower accuracy of 2.4% and 45.6% respectively. This suggests that our foreground and background features are well disentangled. We further test the efficacy of these representations by training classifiers on a task with strong spurious correlations.
FOCUS: Familiar Objects in Common and Uncommon Settings
Oct 07, 2021
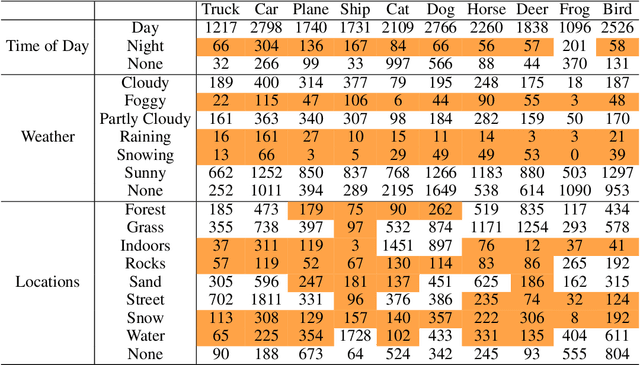

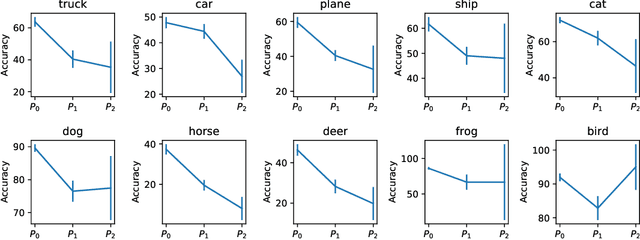
Standard training datasets for deep learning often contain objects in common settings (e.g., "a horse on grass" or "a ship in water") since they are usually collected by randomly scraping the web. Uncommon and rare settings (e.g., "a plane on water", "a car in snowy weather") are thus severely under-represented in the training data. This can lead to an undesirable bias in model predictions towards common settings and create a false sense of accuracy. In this paper, we introduce FOCUS (Familiar Objects in Common and Uncommon Settings), a dataset for stress-testing the generalization power of deep image classifiers. By leveraging the power of modern search engines, we deliberately gather data containing objects in common and uncommon settings in a wide range of locations, weather conditions, and time of day. We present a detailed analysis of the performance of various popular image classifiers on our dataset and demonstrate a clear drop in performance when classifying images in uncommon settings. By analyzing deep features of these models, we show that such errors can be due to the use of spurious features in model predictions. We believe that our dataset will aid researchers in understanding the inability of deep models to generalize well to uncommon settings and drive future work on improving their distributional robustness.