 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Local Dynamics Regularity for Reusable Skills in Offline Hierarchical RL
May 25, 2026Hierarchical Reinforcement Learning (HRL) promises to solve long-horizon Reinforcement Learning (RL) tasks more efficiently than non-hierarchical counterparts by discovering and reusing temporally-extended skills. However, obtaining skills that are actually reusable remains an open challenge. Towards this end, we focus on abstractions that exploit the intuition of local dynamics: local transitions in different global contexts require similar kinds of action sequences. By aligning these contexts with the action sequences they require, we are able to learn which skills to reuse and where to reuse them. In principle, this information should benefit many HRL algorithms, where high-level policies have to reason about the low-level skills they use. The resulting algorithm CARL (Contrastive Action-based Representations for Reusable Local Control) shows both qualitative clustering of meaningful skills in complex humanoid environments and improved downstream performance on the OGBench benchmark when integrated with HIQL.
Offline Action-Free Learning of Ex-BMDPs by Comparing Diverse Datasets
Mar 26, 2025


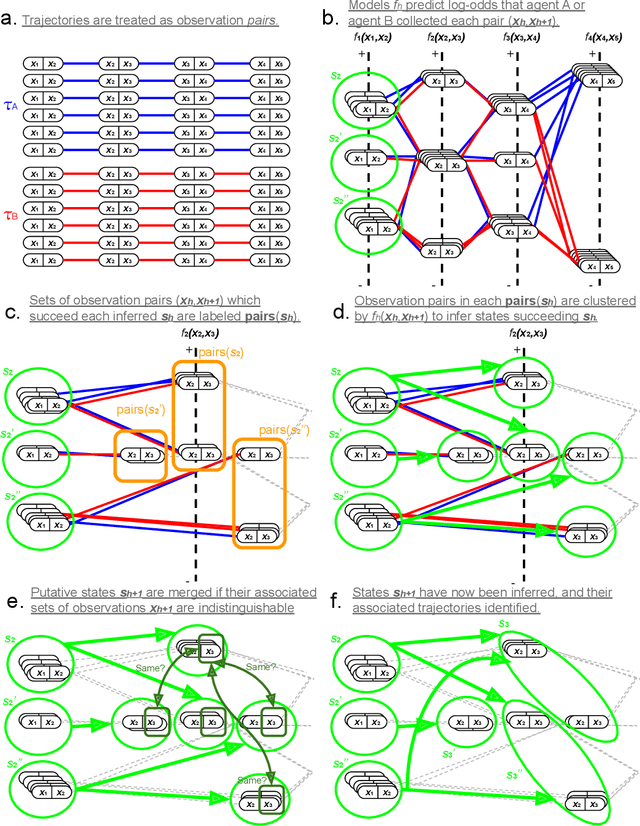
While sequential decision-making environments often involve high-dimensional observations, not all features of these observations are relevant for control. In particular, the observation space may capture factors of the environment which are not controllable by the agent, but which add complexity to the observation space. The need to ignore these "noise" features in order to operate in a tractably-small state space poses a challenge for efficient policy learning. Due to the abundance of video data available in many such environments, task-independent representation learning from action-free offline data offers an attractive solution. However, recent work has highlighted theoretical limitations in action-free learning under the Exogenous Block MDP (Ex-BMDP) model, where temporally-correlated noise features are present in the observations. To address these limitations, we identify a realistic setting where representation learning in Ex-BMDPs becomes tractable: when action-free video data from multiple agents with differing policies are available. Concretely, this paper introduces CRAFT (Comparison-based Representations from Action-Free Trajectories), a sample-efficient algorithm leveraging differences in controllable feature dynamics across agents to learn representations. We provide theoretical guarantees for CRAFT's performance and demonstrate its feasibility on a toy example, offering a foundation for practical methods in similar settings.
Learning a Fast Mixing Exogenous Block MDP using a Single Trajectory
Oct 03, 2024


In order to train agents that can quickly adapt to new objectives or reward functions, efficient unsupervised representation learning in sequential decision-making environments can be important. Frameworks such as the Exogenous Block Markov Decision Process (Ex-BMDP) have been proposed to formalize this representation-learning problem (Efroni et al., 2022b). In the Ex-BMDP framework, the agent's high-dimensional observations of the environment have two latent factors: a controllable factor, which evolves deterministically within a small state space according to the agent's actions, and an exogenous factor, which represents time-correlated noise, and can be highly complex. The goal of the representation learning problem is to learn an encoder that maps from observations into the controllable latent space, as well as the dynamics of this space. Efroni et al. (2022b) has shown that this is possible with a sample complexity that depends only on the size of the controllable latent space, and not on the size of the noise factor. However, this prior work has focused on the episodic setting, where the controllable latent state resets to a specific start state after a finite horizon. By contrast, if the agent can only interact with the environment in a single continuous trajectory, prior works have not established sample-complexity bounds. We propose STEEL, the first provably sample-efficient algorithm for learning the controllable dynamics of an Ex-BMDP from a single trajectory, in the function approximation setting. STEEL has a sample complexity that depends only on the sizes of the controllable latent space and the encoder function class, and (at worst linearly) on the mixing time of the exogenous noise factor. We prove that STEEL is correct and sample-efficient, and demonstrate STEEL on two toy problems. Code is available at: https://github.com/midi-lab/steel.
Multistep Inverse Is Not All You Need
Mar 18, 2024In real-world control settings, the observation space is often unnecessarily high-dimensional and subject to time-correlated noise. However, the controllable dynamics of the system are often far simpler than the dynamics of the raw observations. It is therefore desirable to learn an encoder to map the observation space to a simpler space of control-relevant variables. In this work, we consider the Ex-BMDP model, first proposed by Efroni et al. (2022), which formalizes control problems where observations can be factorized into an action-dependent latent state which evolves deterministically, and action-independent time-correlated noise. Lamb et al. (2022) proposes the "AC-State" method for learning an encoder to extract a complete action-dependent latent state representation from the observations in such problems. AC-State is a multistep-inverse method, in that it uses the encoding of the the first and last state in a path to predict the first action in the path. However, we identify cases where AC-State will fail to learn a correct latent representation of the agent-controllable factor of the state. We therefore propose a new algorithm, ACDF, which combines multistep-inverse prediction with a latent forward model. ACDF is guaranteed to correctly infer an action-dependent latent state encoder for a large class of Ex-BMDP models. We demonstrate the effectiveness of ACDF on tabular Ex-BMDPs through numerical simulations; as well as high-dimensional environments using neural-network-based encoders. Code is available at https://github.com/midi-lab/acdf.
Invariant Learning via Diffusion Dreamed Distribution Shifts
Nov 18, 2022Though the background is an important signal for image classification, over reliance on it can lead to incorrect predictions when spurious correlations between foreground and background are broken at test time. Training on a dataset where these correlations are unbiased would lead to more robust models. In this paper, we propose such a dataset called Diffusion Dreamed Distribution Shifts (D3S). D3S consists of synthetic images generated through StableDiffusion using text prompts and image guides obtained by pasting a sample foreground image onto a background template image. Using this scalable approach we generate 120K images of objects from all 1000 ImageNet classes in 10 diverse backgrounds. Due to the incredible photorealism of the diffusion model, our images are much closer to natural images than previous synthetic datasets. D3S contains a validation set of more than 17K images whose labels are human-verified in an MTurk study. Using the validation set, we evaluate several popular DNN image classifiers and find that the classification performance of models generally suffers on our background diverse images. Next, we leverage the foreground & background labels in D3S to learn a foreground (background) representation that is invariant to changes in background (foreground) by penalizing the mutual information between the foreground (background) features and the background (foreground) labels. Linear classifiers trained on these features to predict foreground (background) from foreground (background) have high accuracies at 82.9% (93.8%), while classifiers that predict these labels from background and foreground have a much lower accuracy of 2.4% and 45.6% respectively. This suggests that our foreground and background features are well disentangled. We further test the efficacy of these representations by training classifiers on a task with strong spurious correlations.
Goal-Conditioned Q-Learning as Knowledge Distillation
Aug 28, 2022


Many applications of reinforcement learning can be formalized as goal-conditioned environments, where, in each episode, there is a "goal" that affects the rewards obtained during that episode but does not affect the dynamics. Various techniques have been proposed to improve performance in goal-conditioned environments, such as automatic curriculum generation and goal relabeling. In this work, we explore a connection between off-policy reinforcement learning in goal-conditioned settings and knowledge distillation. In particular: the current Q-value function and the target Q-value estimate are both functions of the goal, and we would like to train the Q-value function to match its target for all goals. We therefore apply Gradient-Based Attention Transfer (Zagoruyko and Komodakis 2017), a knowledge distillation technique, to the Q-function update. We empirically show that this can improve the performance of goal-conditioned off-policy reinforcement learning when the space of goals is high-dimensional. We also show that this technique can be adapted to allow for efficient learning in the case of multiple simultaneous sparse goals, where the agent can attain a reward by achieving any one of a large set of objectives, all specified at test time. Finally, to provide theoretical support, we give examples of classes of environments where (under some assumptions) standard off-policy algorithms require at least O(d^2) observed transitions to learn an optimal policy, while our proposed technique requires only O(d) transitions, where d is the dimensionality of the goal and state space.
Lethal Dose Conjecture on Data Poisoning
Aug 05, 2022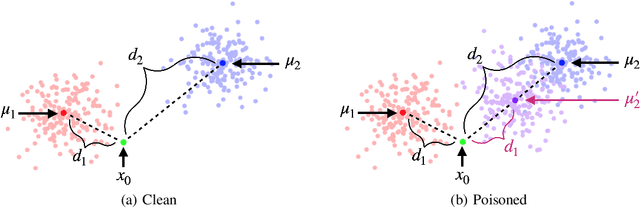
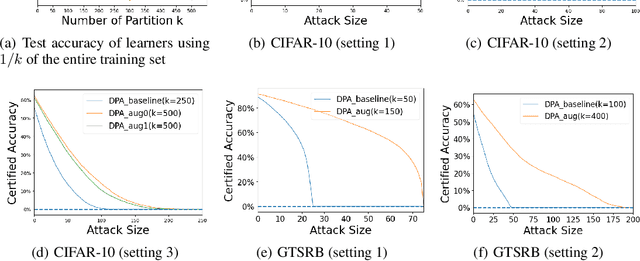
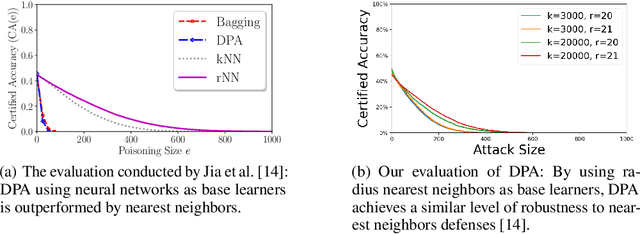
Data poisoning considers an adversary that distorts the training set of machine learning algorithms for malicious purposes. In this work, we bring to light one conjecture regarding the fundamentals of data poisoning, which we call the Lethal Dose Conjecture. The conjecture states: If $n$ clean training samples are needed for accurate predictions, then in a size-$N$ training set, only $\Theta(N/n)$ poisoned samples can be tolerated while ensuring accuracy. Theoretically, we verify this conjecture in multiple cases. We also offer a more general perspective of this conjecture through distribution discrimination. Deep Partition Aggregation (DPA) and its extension, Finite Aggregation (FA) are recent approaches for provable defenses against data poisoning, where they predict through the majority vote of many base models trained from different subsets of training set using a given learner. The conjecture implies that both DPA and FA are (asymptotically) optimal -- if we have the most data-efficient learner, they can turn it into one of the most robust defenses against data poisoning. This outlines a practical approach to developing stronger defenses against poisoning via finding data-efficient learners. Empirically, as a proof of concept, we show that by simply using different data augmentations for base learners, we can respectively double and triple the certified robustness of DPA on CIFAR-10 and GTSRB without sacrificing accuracy.
Provable Adversarial Robustness for Fractional Lp Threat Models
Mar 16, 2022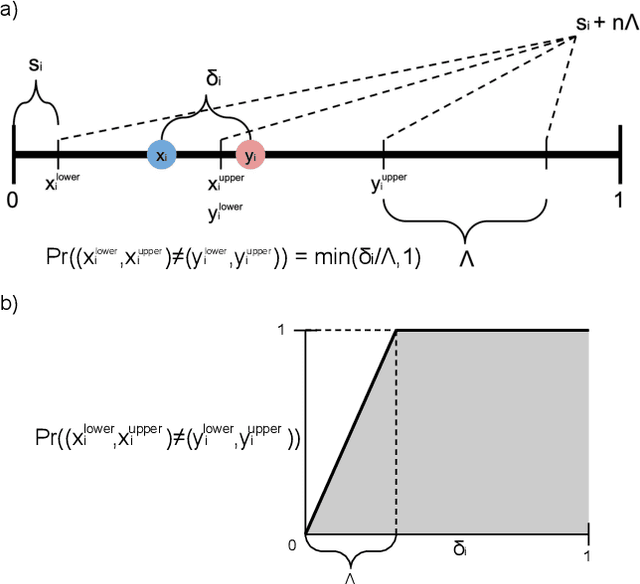
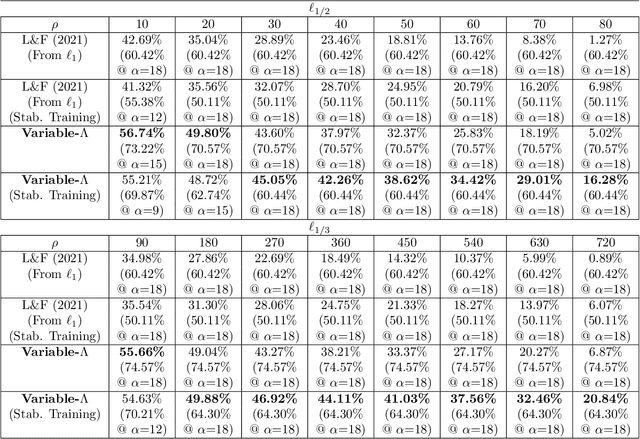
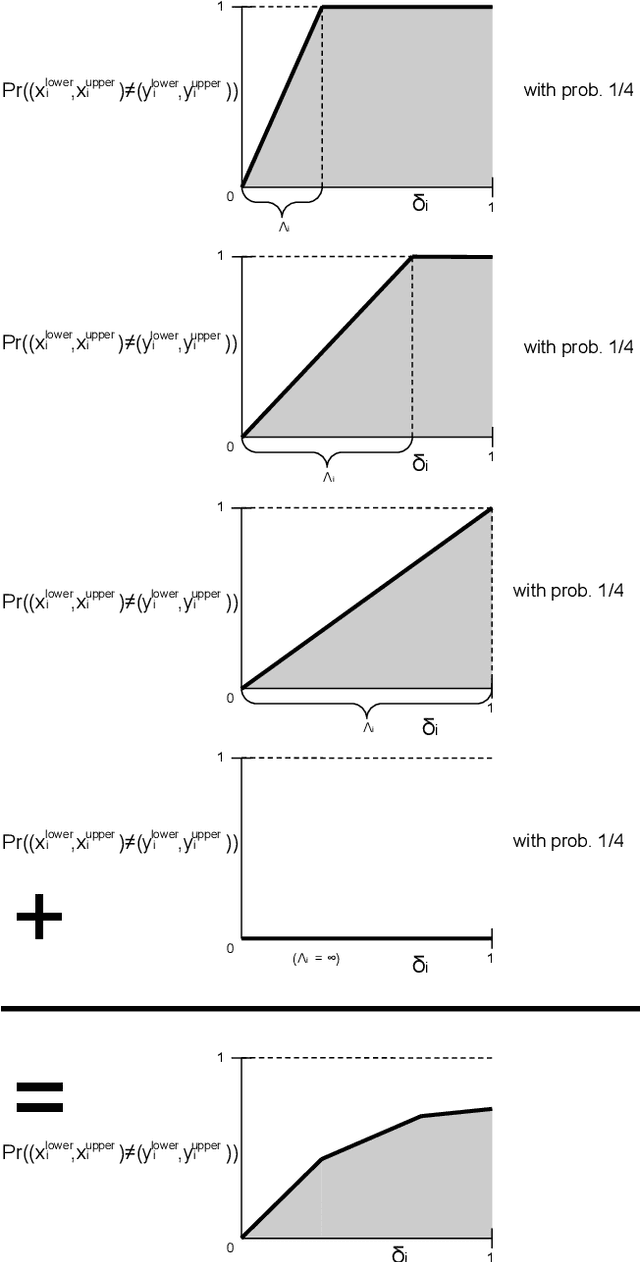
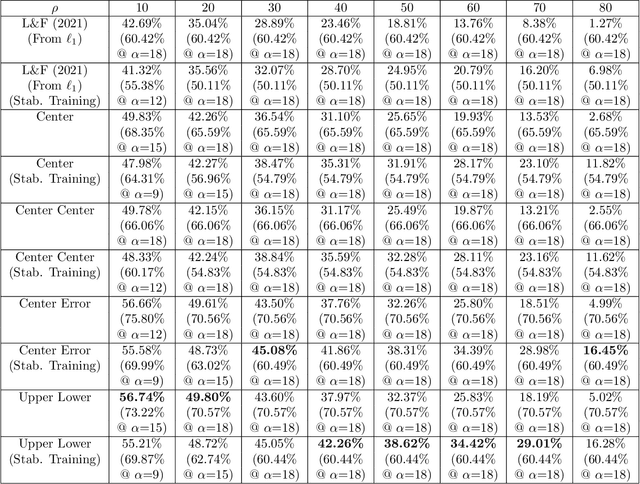
In recent years, researchers have extensively studied adversarial robustness in a variety of threat models, including L_0, L_1, L_2, and L_infinity-norm bounded adversarial attacks. However, attacks bounded by fractional L_p "norms" (quasi-norms defined by the L_p distance with 0<p<1) have yet to be thoroughly considered. We proactively propose a defense with several desirable properties: it provides provable (certified) robustness, scales to ImageNet, and yields deterministic (rather than high-probability) certified guarantees when applied to quantized data (e.g., images). Our technique for fractional L_p robustness constructs expressive, deep classifiers that are globally Lipschitz with respect to the L_p^p metric, for any 0<p<1. However, our method is even more general: we can construct classifiers which are globally Lipschitz with respect to any metric defined as the sum of concave functions of components. Our approach builds on a recent work, Levine and Feizi (2021), which provides a provable defense against L_1 attacks. However, we demonstrate that our proposed guarantees are highly non-vacuous, compared to the trivial solution of using (Levine and Feizi, 2021) directly and applying norm inequalities. Code is available at https://github.com/alevine0/fractionalLpRobustness.
Improved Certified Defenses against Data Poisoning with (Deterministic) Finite Aggregation
Feb 05, 2022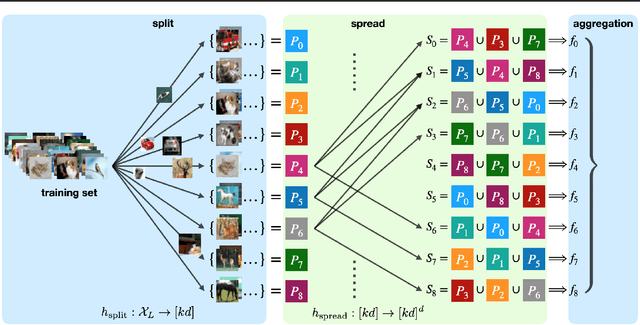
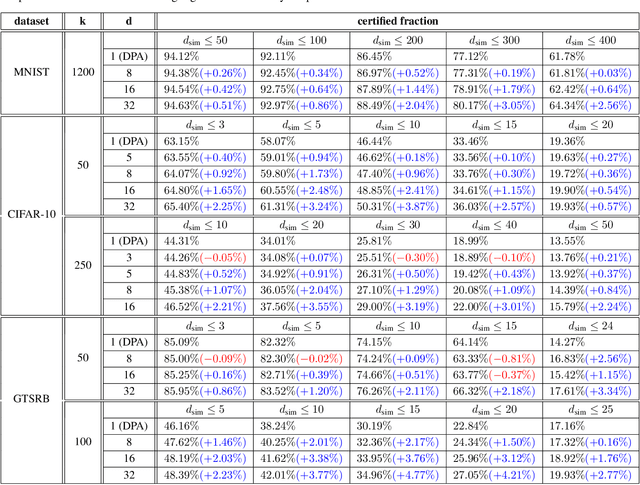
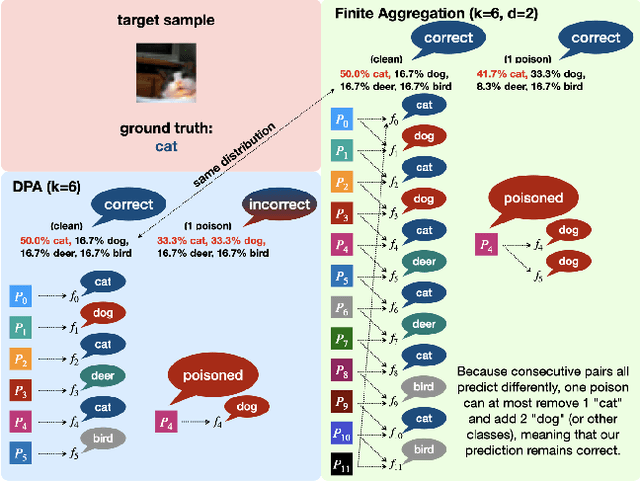
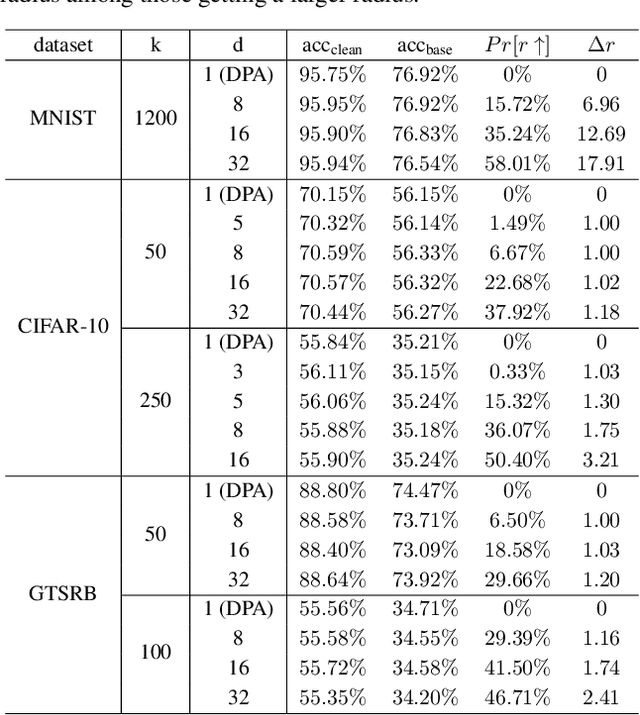
Data poisoning attacks aim at manipulating model behaviors through distorting training data. Previously, an aggregation-based certified defense, Deep Partition Aggregation (DPA), was proposed to mitigate this threat. DPA predicts through an aggregation of base classifiers trained on disjoint subsets of data, thus restricting its sensitivity to dataset distortions. In this work, we propose an improved certified defense against general poisoning attacks, namely Finite Aggregation. In contrast to DPA, which directly splits the training set into disjoint subsets, our method first splits the training set into smaller disjoint subsets and then combines duplicates of them to build larger (but not disjoint) subsets for training base classifiers. This reduces the worst-case impacts of poison samples and thus improves certified robustness bounds. In addition, we offer an alternative view of our method, bridging the designs of deterministic and stochastic aggregation-based certified defenses. Empirically, our proposed Finite Aggregation consistently improves certificates on MNIST, CIFAR-10, and GTSRB, boosting certified fractions by up to 3.05%, 3.87% and 4.77%, respectively, while keeping the same clean accuracies as DPA's, effectively establishing a new state of the art in (pointwise) certified robustness against data poisoning.
Certifying Model Accuracy under Distribution Shifts
Jan 28, 2022
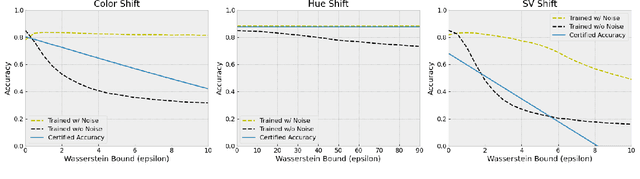
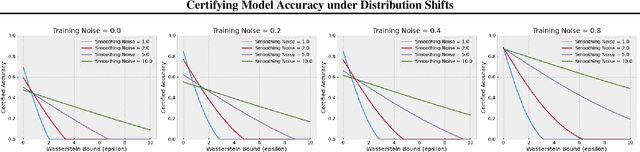
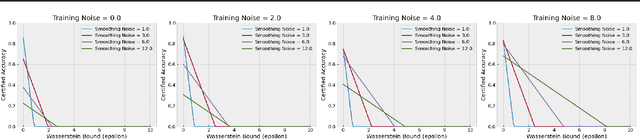
Certified robustness in machine learning has primarily focused on adversarial perturbations of the input with a fixed attack budget for each point in the data distribution. In this work, we present provable robustness guarantees on the accuracy of a model under bounded Wasserstein shifts of the data distribution. We show that a simple procedure that randomizes the input of the model within a transformation space is provably robust to distributional shifts under the transformation. Our framework allows the datum-specific perturbation size to vary across different points in the input distribution and is general enough to include fixed-sized perturbations as well. Our certificates produce guaranteed lower bounds on the performance of the model for any (natural or adversarial) shift of the input distribution within a Wasserstein ball around the original distribution. We apply our technique to: (i) certify robustness against natural (non-adversarial) transformations of images such as color shifts, hue shifts and changes in brightness and saturation, (ii) certify robustness against adversarial shifts of the input distribution, and (iii) show provable lower bounds (hardness results) on the performance of models trained on so-called "unlearnable" datasets that have been poisoned to interfere with model training.