 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Adversarial Robustness for Fractional Lp Threat Models
Paper and Code
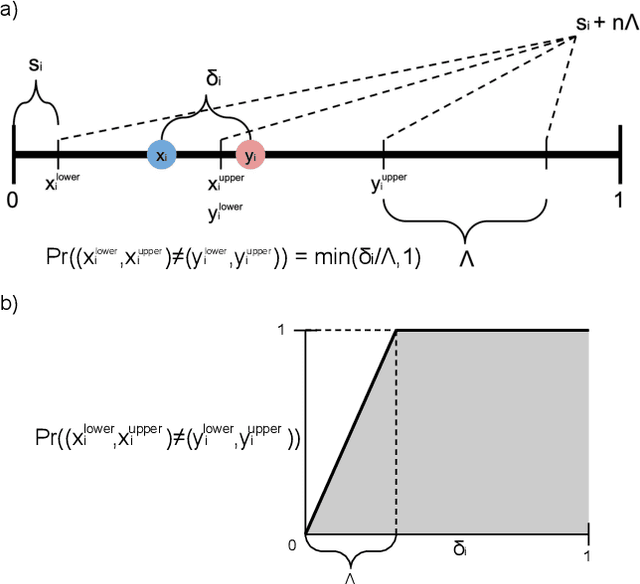
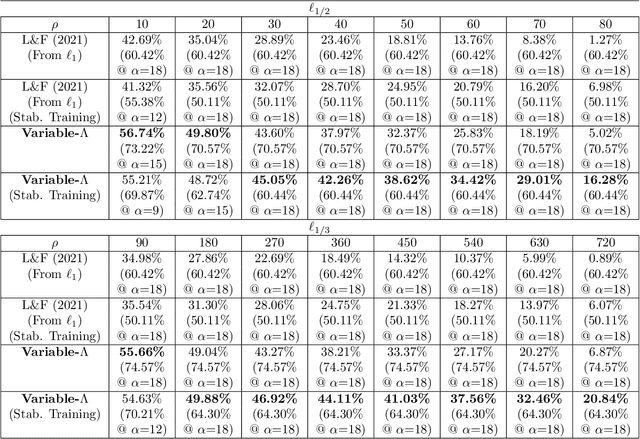
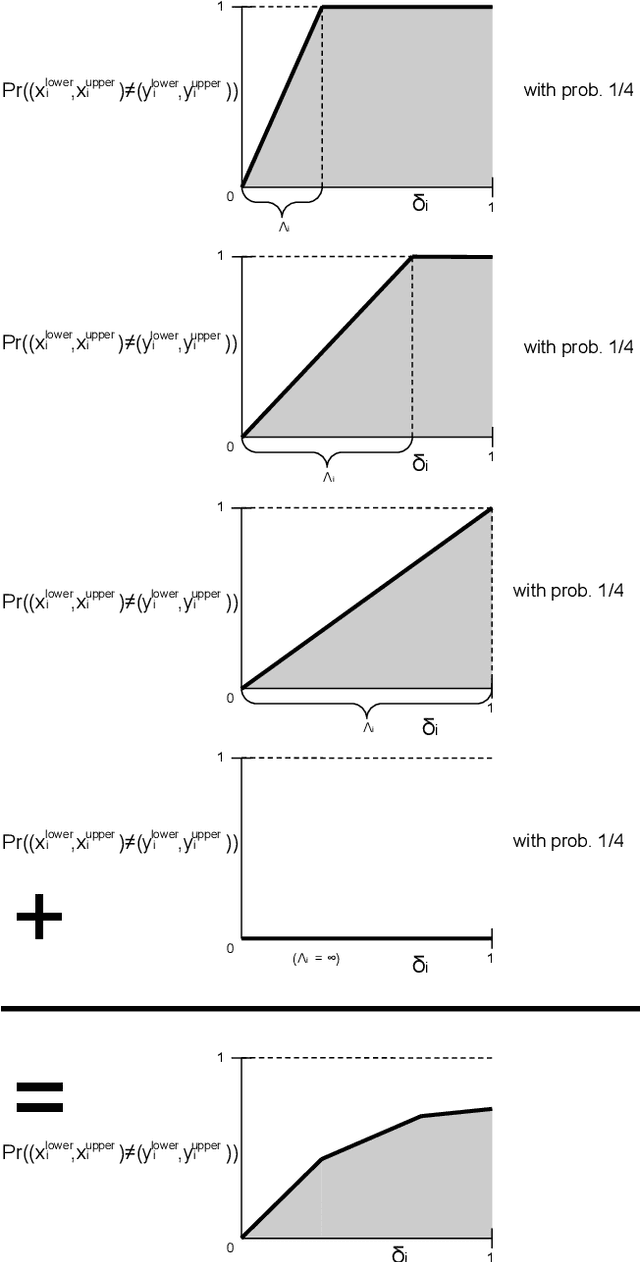
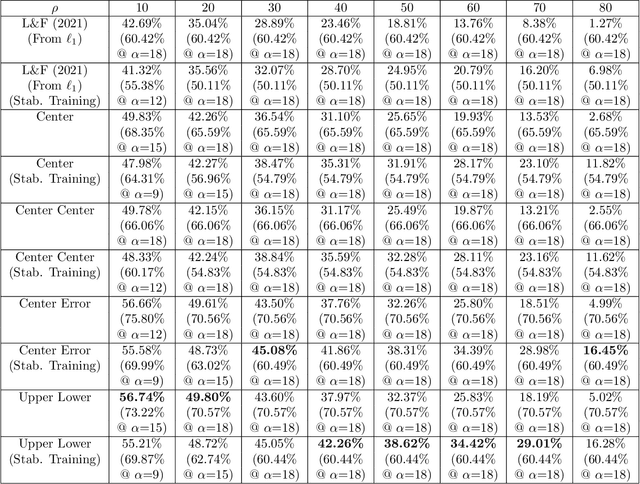
In recent years, researchers have extensively studied adversarial robustness in a variety of threat models, including L_0, L_1, L_2, and L_infinity-norm bounded adversarial attacks. However, attacks bounded by fractional L_p "norms" (quasi-norms defined by the L_p distance with 0<p<1) have yet to be thoroughly considered. We proactively propose a defense with several desirable properties: it provides provable (certified) robustness, scales to ImageNet, and yields deterministic (rather than high-probability) certified guarantees when applied to quantized data (e.g., images). Our technique for fractional L_p robustness constructs expressive, deep classifiers that are globally Lipschitz with respect to the L_p^p metric, for any 0<p<1. However, our method is even more general: we can construct classifiers which are globally Lipschitz with respect to any metric defined as the sum of concave functions of components. Our approach builds on a recent work, Levine and Feizi (2021), which provides a provable defense against L_1 attacks. However, we demonstrate that our proposed guarantees are highly non-vacuous, compared to the trivial solution of using (Levine and Feizi, 2021) directly and applying norm inequalities. Code is available at https://github.com/alevine0/fractionalLpRobustness.