 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFailing to Explore: Language Models on Interactive Tasks
Jan 29, 2026We evaluate language models on their ability to explore interactive environments under a limited interaction budget. We introduce three parametric tasks with controllable exploration difficulty, spanning continuous and discrete environments. Across state-of-the-art models, we find systematic under-exploration and suboptimal solutions, with performance often significantly worse than simple explore--exploit heuristic baselines and scaling weakly as the budget increases. Finally, we study two lightweight interventions: splitting a fixed budget into parallel executions, which surprisingly improves performance despite a no-gain theoretical result for our tasks, and periodically summarizing the interaction history, which preserves key discoveries and further improves exploration.
Schoenfeld's Anatomy of Mathematical Reasoning by Language Models
Dec 23, 2025
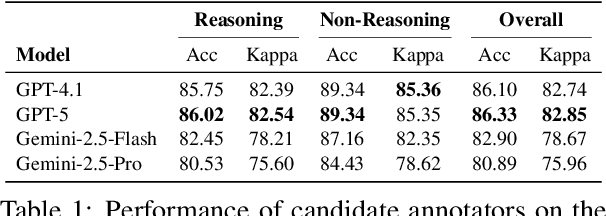

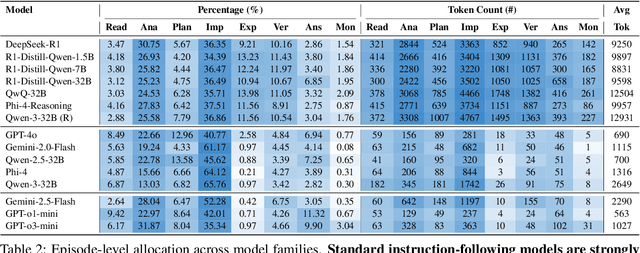
Large language models increasingly expose reasoning traces, yet their underlying cognitive structure and steps remain difficult to identify and analyze beyond surface-level statistics. We adopt Schoenfeld's Episode Theory as an inductive, intermediate-scale lens and introduce ThinkARM (Anatomy of Reasoning in Models), a scalable framework that explicitly abstracts reasoning traces into functional reasoning steps such as Analysis, Explore, Implement, Verify, etc. When applied to mathematical problem solving by diverse models, this abstraction reveals reproducible thinking dynamics and structural differences between reasoning and non-reasoning models, which are not apparent from token-level views. We further present two diagnostic case studies showing that exploration functions as a critical branching step associated with correctness, and that efficiency-oriented methods selectively suppress evaluative feedback steps rather than uniformly shortening responses. Together, our results demonstrate that episode-level representations make reasoning steps explicit, enabling systematic analysis of how reasoning is structured, stabilized, and altered in modern language models.
AgentComp: From Agentic Reasoning to Compositional Mastery in Text-to-Image Models
Dec 09, 2025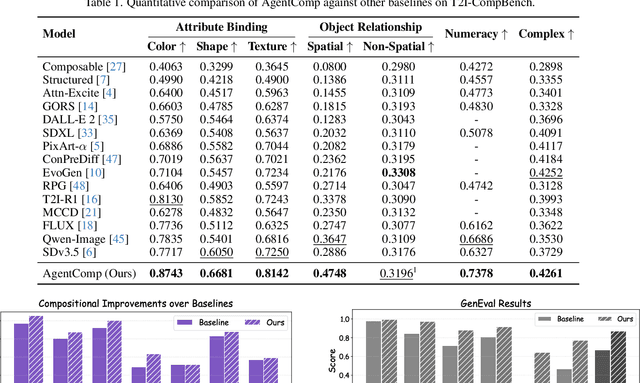

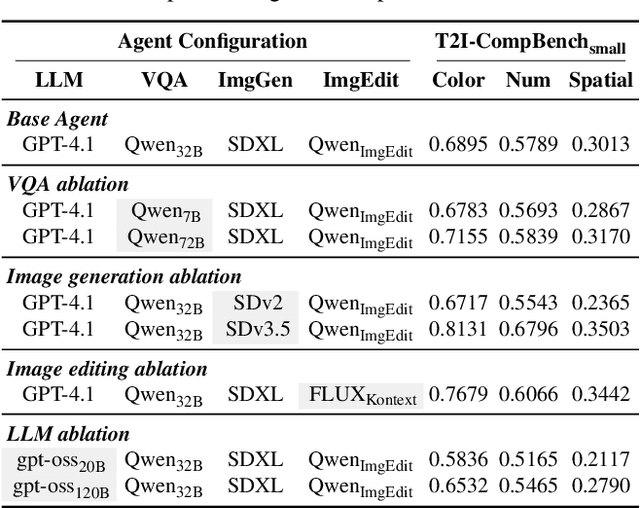
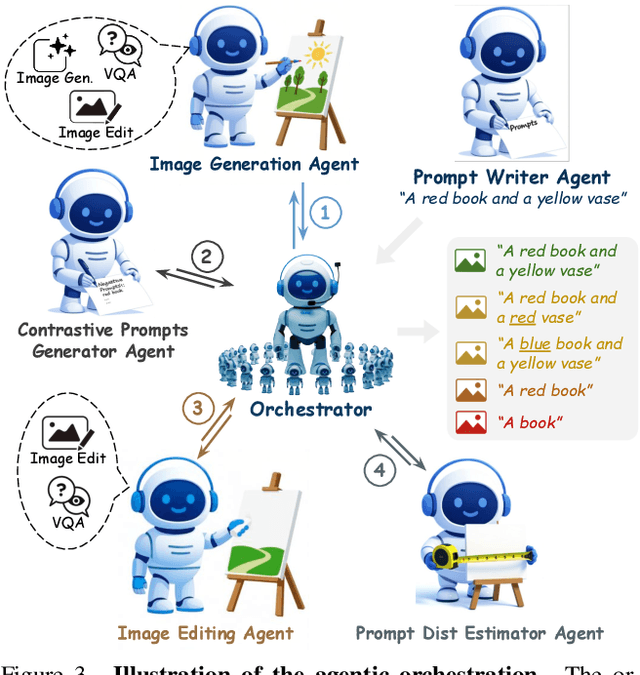
Text-to-image generative models have achieved remarkable visual quality but still struggle with compositionality$-$accurately capturing object relationships, attribute bindings, and fine-grained details in prompts. A key limitation is that models are not explicitly trained to differentiate between compositionally similar prompts and images, resulting in outputs that are close to the intended description yet deviate in fine-grained details. To address this, we propose AgentComp, a framework that explicitly trains models to better differentiate such compositional variations and enhance their reasoning ability. AgentComp leverages the reasoning and tool-use capabilities of large language models equipped with image generation, editing, and VQA tools to autonomously construct compositional datasets. Using these datasets, we apply an agentic preference optimization method to fine-tune text-to-image models, enabling them to better distinguish between compositionally similar samples and resulting in overall stronger compositional generation ability. AgentComp achieves state-of-the-art results on compositionality benchmarks such as T2I-CompBench, without compromising image quality$-$a common drawback in prior approaches$-$and even generalizes to other capabilities not explicitly trained for, such as text rendering.
SliderEdit: Continuous Image Editing with Fine-Grained Instruction Control
Nov 12, 2025Instruction-based image editing models have recently achieved impressive performance, enabling complex edits to an input image from a multi-instruction prompt. However, these models apply each instruction in the prompt with a fixed strength, limiting the user's ability to precisely and continuously control the intensity of individual edits. We introduce SliderEdit, a framework for continuous image editing with fine-grained, interpretable instruction control. Given a multi-part edit instruction, SliderEdit disentangles the individual instructions and exposes each as a globally trained slider, allowing smooth adjustment of its strength. Unlike prior works that introduced slider-based attribute controls in text-to-image generation, typically requiring separate training or fine-tuning for each attribute or concept, our method learns a single set of low-rank adaptation matrices that generalize across diverse edits, attributes, and compositional instructions. This enables continuous interpolation along individual edit dimensions while preserving both spatial locality and global semantic consistency. We apply SliderEdit to state-of-the-art image editing models, including FLUX-Kontext and Qwen-Image-Edit, and observe substantial improvements in edit controllability, visual consistency, and user steerability. To the best of our knowledge, we are the first to explore and propose a framework for continuous, fine-grained instruction control in instruction-based image editing models. Our results pave the way for interactive, instruction-driven image manipulation with continuous and compositional control.
Decomposition-Enhanced Training for Post-Hoc Attributions In Language Models
Oct 29, 2025Large language models (LLMs) are increasingly used for long-document question answering, where reliable attribution to sources is critical for trust. Existing post-hoc attribution methods work well for extractive QA but struggle in multi-hop, abstractive, and semi-extractive settings, where answers synthesize information across passages. To address these challenges, we argue that post-hoc attribution can be reframed as a reasoning problem, where answers are decomposed into constituent units, each tied to specific context. We first show that prompting models to generate such decompositions alongside attributions improves performance. Building on this, we introduce DecompTune, a post-training method that teaches models to produce answer decompositions as intermediate reasoning steps. We curate a diverse dataset of complex QA tasks, annotated with decompositions by a strong LLM, and post-train Qwen-2.5 (7B and 14B) using a two-stage SFT + GRPO pipeline with task-specific curated rewards. Across extensive experiments and ablations, DecompTune substantially improves attribution quality, outperforming prior methods and matching or exceeding state-of-the-art frontier models.
Maestro: Joint Graph & Config Optimization for Reliable AI Agents
Sep 04, 2025Building reliable LLM agents requires decisions at two levels: the graph (which modules exist and how information flows) and the configuration of each node (models, prompts, tools, control knobs). Most existing optimizers tune configurations while holding the graph fixed, leaving structural failure modes unaddressed. We introduce Maestro, a framework-agnostic holistic optimizer for LLM agents that jointly searches over graphs and configurations to maximize agent quality, subject to explicit rollout/token budgets. Beyond numeric metrics, Maestro leverages reflective textual feedback from traces to prioritize edits, improving sample efficiency and targeting specific failure modes. On the IFBench and HotpotQA benchmarks, Maestro consistently surpasses leading prompt optimizers--MIPROv2, GEPA, and GEPA+Merge--by an average of 12%, 4.9%, and 4.86%, respectively; even when restricted to prompt-only optimization, it still leads by 9.65%, 2.37%, and 2.41%. Maestro achieves these results with far fewer rollouts than GEPA. We further show large gains on two applications (interviewer & RAG agents), highlighting that joint graph & configuration search addresses structural failure modes that prompt tuning alone cannot fix.
Model State Arithmetic for Machine Unlearning
Jun 26, 2025


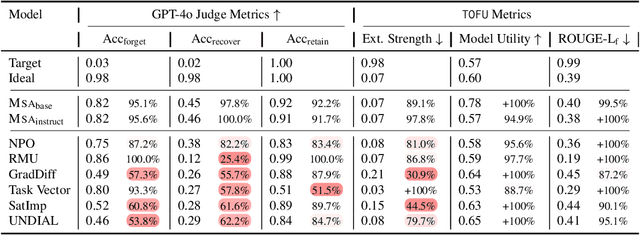
Large language models are trained on massive corpora of web data, which may include private data, copyrighted material, factually inaccurate data, or data that degrades model performance. Eliminating the influence of such problematic datapoints through complete retraining -- by repeatedly pretraining the model on datasets that exclude these specific instances -- is computationally prohibitive. For this reason, unlearning algorithms have emerged that aim to eliminate the influence of particular datapoints, while otherwise preserving the model -- at a low computational cost. However, precisely estimating and undoing the influence of individual datapoints has proved to be challenging. In this work, we propose a new algorithm, MSA, for estimating and undoing the influence of datapoints -- by leveraging model checkpoints i.e. artifacts capturing model states at different stages of pretraining. Our experimental results demonstrate that MSA consistently outperforms existing machine unlearning algorithms across multiple benchmarks, models, and evaluation metrics, suggesting that MSA could be an effective approach towards more flexible large language models that are capable of data erasure.
Adversarial Paraphrasing: A Universal Attack for Humanizing AI-Generated Text
Jun 08, 2025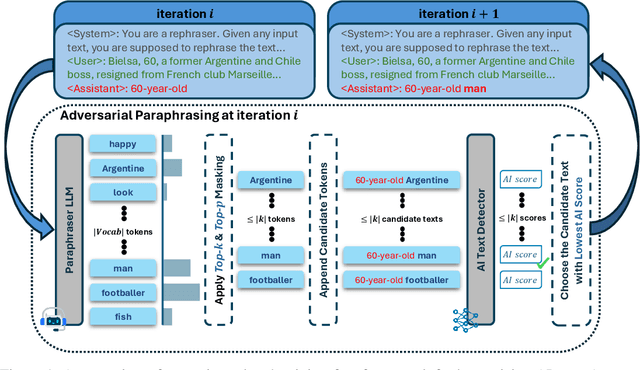

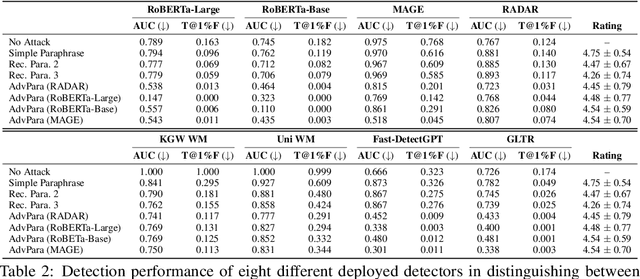
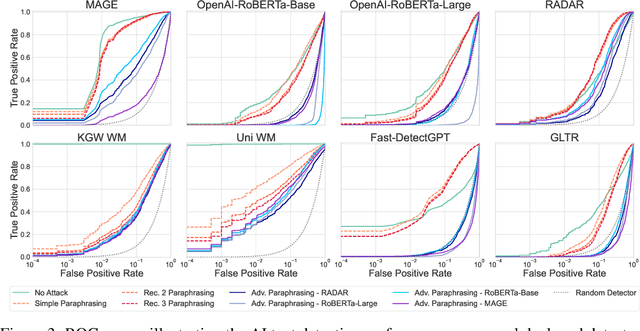
The increasing capabilities of Large Language Models (LLMs) have raised concerns about their misuse in AI-generated plagiarism and social engineering. While various AI-generated text detectors have been proposed to mitigate these risks, many remain vulnerable to simple evasion techniques such as paraphrasing. However, recent detectors have shown greater robustness against such basic attacks. In this work, we introduce Adversarial Paraphrasing, a training-free attack framework that universally humanizes any AI-generated text to evade detection more effectively. Our approach leverages an off-the-shelf instruction-following LLM to paraphrase AI-generated content under the guidance of an AI text detector, producing adversarial examples that are specifically optimized to bypass detection. Extensive experiments show that our attack is both broadly effective and highly transferable across several detection systems. For instance, compared to simple paraphrasing attack--which, ironically, increases the true positive at 1% false positive (T@1%F) by 8.57% on RADAR and 15.03% on Fast-DetectGPT--adversarial paraphrasing, guided by OpenAI-RoBERTa-Large, reduces T@1%F by 64.49% on RADAR and a striking 98.96% on Fast-DetectGPT. Across a diverse set of detectors--including neural network-based, watermark-based, and zero-shot approaches--our attack achieves an average T@1%F reduction of 87.88% under the guidance of OpenAI-RoBERTa-Large. We also analyze the tradeoff between text quality and attack success to find that our method can significantly reduce detection rates, with mostly a slight degradation in text quality. Our adversarial setup highlights the need for more robust and resilient detection strategies in the light of increasingly sophisticated evasion techniques.
DyePack: Provably Flagging Test Set Contamination in LLMs Using Backdoors
May 29, 2025Open benchmarks are essential for evaluating and advancing large language models, offering reproducibility and transparency. However, their accessibility makes them likely targets of test set contamination. In this work, we introduce DyePack, a framework that leverages backdoor attacks to identify models that used benchmark test sets during training, without requiring access to the loss, logits, or any internal details of the model. Like how banks mix dye packs with their money to mark robbers, DyePack mixes backdoor samples with the test data to flag models that trained on it. We propose a principled design incorporating multiple backdoors with stochastic targets, enabling exact false positive rate (FPR) computation when flagging every model. This provably prevents false accusations while providing strong evidence for every detected case of contamination. We evaluate DyePack on five models across three datasets, covering both multiple-choice and open-ended generation tasks. For multiple-choice questions, it successfully detects all contaminated models with guaranteed FPRs as low as 0.000073% on MMLU-Pro and 0.000017% on Big-Bench-Hard using eight backdoors. For open-ended generation tasks, it generalizes well and identifies all contaminated models on Alpaca with a guaranteed false positive rate of just 0.127% using six backdoors.
A Closer Look at Bias and Chain-of-Thought Faithfulness of Large (Vision) Language Models
May 29, 2025



Chain-of-thought (CoT) reasoning enhances performance of large language models, but questions remain about whether these reasoning traces faithfully reflect the internal processes of the model. We present the first comprehensive study of CoT faithfulness in large vision-language models (LVLMs), investigating how both text-based and previously unexplored image-based biases affect reasoning and bias articulation. Our work introduces a novel, fine-grained evaluation pipeline for categorizing bias articulation patterns, enabling significantly more precise analysis of CoT reasoning than previous methods. This framework reveals critical distinctions in how models process and respond to different types of biases, providing new insights into LVLM CoT faithfulness. Our findings reveal that subtle image-based biases are rarely articulated compared to explicit text-based ones, even in models specialized for reasoning. Additionally, many models exhibit a previously unidentified phenomenon we term ``inconsistent'' reasoning - correctly reasoning before abruptly changing answers, serving as a potential canary for detecting biased reasoning from unfaithful CoTs. We then apply the same evaluation pipeline to revisit CoT faithfulness in LLMs across various levels of implicit cues. Our findings reveal that current language-only reasoning models continue to struggle with articulating cues that are not overtly stated.