 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHop, Skip, and Overthink: Diagnosing Why Reasoning Models Fumble during Multi-Hop Analysis
Aug 06, 2025The emergence of reasoning models and their integration into practical AI chat bots has led to breakthroughs in solving advanced math, deep search, and extractive question answering problems that requires a complex and multi-step thought process. Yet, a complete understanding of why these models hallucinate more than general purpose language models is missing. In this investigative study, we systematicallyexplore reasoning failures of contemporary language models on multi-hop question answering tasks. We introduce a novel, nuanced error categorization framework that examines failures across three critical dimensions: the diversity and uniqueness of source documents involved ("hops"), completeness in capturing relevant information ("coverage"), and cognitive inefficiency ("overthinking"). Through rigorous hu-man annotation, supported by complementary automated metrics, our exploration uncovers intricate error patterns often hidden by accuracy-centric evaluations. This investigative approach provides deeper insights into the cognitive limitations of current models and offers actionable guidance toward enhancing reasoning fidelity, transparency, and robustness in future language modeling efforts.
A Closer Look at Bias and Chain-of-Thought Faithfulness of Large (Vision) Language Models
May 29, 2025



Chain-of-thought (CoT) reasoning enhances performance of large language models, but questions remain about whether these reasoning traces faithfully reflect the internal processes of the model. We present the first comprehensive study of CoT faithfulness in large vision-language models (LVLMs), investigating how both text-based and previously unexplored image-based biases affect reasoning and bias articulation. Our work introduces a novel, fine-grained evaluation pipeline for categorizing bias articulation patterns, enabling significantly more precise analysis of CoT reasoning than previous methods. This framework reveals critical distinctions in how models process and respond to different types of biases, providing new insights into LVLM CoT faithfulness. Our findings reveal that subtle image-based biases are rarely articulated compared to explicit text-based ones, even in models specialized for reasoning. Additionally, many models exhibit a previously unidentified phenomenon we term ``inconsistent'' reasoning - correctly reasoning before abruptly changing answers, serving as a potential canary for detecting biased reasoning from unfaithful CoTs. We then apply the same evaluation pipeline to revisit CoT faithfulness in LLMs across various levels of implicit cues. Our findings reveal that current language-only reasoning models continue to struggle with articulating cues that are not overtly stated.
Gaming Tool Preferences in Agentic LLMs
May 23, 2025Large language models (LLMs) can now access a wide range of external tools, thanks to the Model Context Protocol (MCP). This greatly expands their abilities as various agents. However, LLMs rely entirely on the text descriptions of tools to decide which ones to use--a process that is surprisingly fragile. In this work, we expose a vulnerability in prevalent tool/function-calling protocols by investigating a series of edits to tool descriptions, some of which can drastically increase a tool's usage from LLMs when competing with alternatives. Through controlled experiments, we show that tools with properly edited descriptions receive over 10 times more usage from GPT-4.1 and Qwen2.5-7B than tools with original descriptions. We further evaluate how various edits to tool descriptions perform when competing directly with one another and how these trends generalize or differ across a broader set of 10 different models. These phenomenons, while giving developers a powerful way to promote their tools, underscore the need for a more reliable foundation for agentic LLMs to select and utilize tools and resources.
Seeing What's Not There: Spurious Correlation in Multimodal LLMs
Mar 11, 2025Unimodal vision models are known to rely on spurious correlations, but it remains unclear to what extent Multimodal Large Language Models (MLLMs) exhibit similar biases despite language supervision. In this paper, we investigate spurious bias in MLLMs and introduce SpurLens, a pipeline that leverages GPT-4 and open-set object detectors to automatically identify spurious visual cues without human supervision. Our findings reveal that spurious correlations cause two major failure modes in MLLMs: (1) over-reliance on spurious cues for object recognition, where removing these cues reduces accuracy, and (2) object hallucination, where spurious cues amplify the hallucination by over 10x. We validate our findings in various MLLMs and datasets. Beyond diagnosing these failures, we explore potential mitigation strategies, such as prompt ensembling and reasoning-based prompting, and conduct ablation studies to examine the root causes of spurious bias in MLLMs. By exposing the persistence of spurious correlations, our study calls for more rigorous evaluation methods and mitigation strategies to enhance the reliability of MLLMs.
A Survey on Mechanistic Interpretability for Multi-Modal Foundation Models
Feb 22, 2025



The rise of foundation models has transformed machine learning research, prompting efforts to uncover their inner workings and develop more efficient and reliable applications for better control. While significant progress has been made in interpreting Large Language Models (LLMs), multimodal foundation models (MMFMs) - such as contrastive vision-language models, generative vision-language models, and text-to-image models - pose unique interpretability challenges beyond unimodal frameworks. Despite initial studies, a substantial gap remains between the interpretability of LLMs and MMFMs. This survey explores two key aspects: (1) the adaptation of LLM interpretability methods to multimodal models and (2) understanding the mechanistic differences between unimodal language models and crossmodal systems. By systematically reviewing current MMFM analysis techniques, we propose a structured taxonomy of interpretability methods, compare insights across unimodal and multimodal architectures, and highlight critical research gaps.
Decomposing and Interpreting Image Representations via Text in ViTs Beyond CLIP
Jun 03, 2024Recent works have explored how individual components of the CLIP-ViT model contribute to the final representation by leveraging the shared image-text representation space of CLIP. These components, such as attention heads and MLPs, have been shown to capture distinct image features like shape, color or texture. However, understanding the role of these components in arbitrary vision transformers (ViTs) is challenging. To this end, we introduce a general framework which can identify the roles of various components in ViTs beyond CLIP. Specifically, we (a) automate the decomposition of the final representation into contributions from different model components, and (b) linearly map these contributions to CLIP space to interpret them via text. Additionally, we introduce a novel scoring function to rank components by their importance with respect to specific features. Applying our framework to various ViT variants (e.g. DeiT, DINO, DINOv2, Swin, MaxViT), we gain insights into the roles of different components concerning particular image features.These insights facilitate applications such as image retrieval using text descriptions or reference images, visualizing token importance heatmaps, and mitigating spurious correlations.
Rethinking Artistic Copyright Infringements in the Era of Text-to-Image Generative Models
Apr 11, 2024



Recent text-to-image generative models such as Stable Diffusion are extremely adept at mimicking and generating copyrighted content, raising concerns amongst artists that their unique styles may be improperly copied. Understanding how generative models copy "artistic style" is more complex than duplicating a single image, as style is comprised by a set of elements (or signature) that frequently co-occurs across a body of work, where each individual work may vary significantly. In our paper, we first reformulate the problem of "artistic copyright infringement" to a classification problem over image sets, instead of probing image-wise similarities. We then introduce ArtSavant, a practical (i.e., efficient and easy to understand) tool to (i) determine the unique style of an artist by comparing it to a reference dataset of works from 372 artists curated from WikiArt, and (ii) recognize if the identified style reappears in generated images. We leverage two complementary methods to perform artistic style classification over image sets, includingTagMatch, which is a novel inherently interpretable and attributable method, making it more suitable for broader use by non-technical stake holders (artists, lawyers, judges, etc). Leveraging ArtSavant, we then perform a large-scale empirical study to provide quantitative insight on the prevalence of artistic style copying across 3 popular text-to-image generative models. Namely, amongst a dataset of prolific artists (including many famous ones), only 20% of them appear to have their styles be at a risk of copying via simple prompting of today's popular text-to-image generative models.
Exploring Geometry of Blind Spots in Vision Models
Oct 30, 2023



Despite the remarkable success of deep neural networks in a myriad of settings, several works have demonstrated their overwhelming sensitivity to near-imperceptible perturbations, known as adversarial attacks. On the other hand, prior works have also observed that deep networks can be under-sensitive, wherein large-magnitude perturbations in input space do not induce appreciable changes to network activations. In this work, we study in detail the phenomenon of under-sensitivity in vision models such as CNNs and Transformers, and present techniques to study the geometry and extent of "equi-confidence" level sets of such networks. We propose a Level Set Traversal algorithm that iteratively explores regions of high confidence with respect to the input space using orthogonal components of the local gradients. Given a source image, we use this algorithm to identify inputs that lie in the same equi-confidence level set as the source image despite being perceptually similar to arbitrary images from other classes. We further observe that the source image is linearly connected by a high-confidence path to these inputs, uncovering a star-like structure for level sets of deep networks. Furthermore, we attempt to identify and estimate the extent of these connected higher-dimensional regions over which the model maintains a high degree of confidence. The code for this project is publicly available at https://github.com/SriramB-98/blindspots-neurips-sub
Can AI-Generated Text be Reliably Detected?
Mar 17, 2023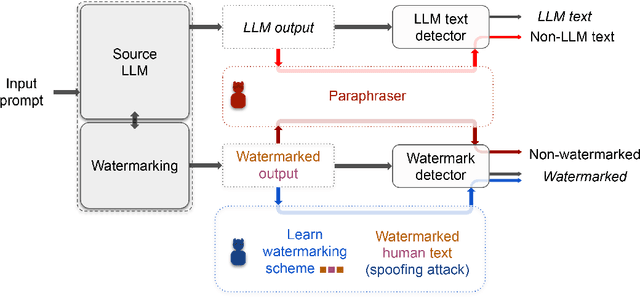



The rapid progress of Large Language Models (LLMs) has made them capable of performing astonishingly well on various tasks including document completion and question answering. The unregulated use of these models, however, can potentially lead to malicious consequences such as plagiarism, generating fake news, spamming, etc. Therefore, reliable detection of AI-generated text can be critical to ensure the responsible use of LLMs. Recent works attempt to tackle this problem either using certain model signatures present in the generated text outputs or by applying watermarking techniques that imprint specific patterns onto them. In this paper, both empirically and theoretically, we show that these detectors are not reliable in practical scenarios. Empirically, we show that paraphrasing attacks, where a light paraphraser is applied on top of the generative text model, can break a whole range of detectors, including the ones using the watermarking schemes as well as neural network-based detectors and zero-shot classifiers. We then provide a theoretical impossibility result indicating that for a sufficiently good language model, even the best-possible detector can only perform marginally better than a random classifier. Finally, we show that even LLMs protected by watermarking schemes can be vulnerable against spoofing attacks where adversarial humans can infer hidden watermarking signatures and add them to their generated text to be detected as text generated by the LLMs, potentially causing reputational damages to their developers. We believe these results can open an honest conversation in the community regarding the ethical and reliable use of AI-generated text.
Towards Better Input Masking for Convolutional Neural Networks
Nov 26, 2022The ability to remove features from the input of machine learning models is very important to understand and interpret model predictions. However, this is non-trivial for vision models since masking out parts of the input image and replacing them with a baseline color like black or grey typically causes large distribution shifts. Masking may even make the model focus on the masking patterns for its prediction rather than the unmasked portions of the image. In recent work, it has been shown that vision transformers are less affected by such issues as one can simply drop the tokens corresponding to the masked image portions. They are thus more easily interpretable using techniques like LIME which rely on input perturbation. Using the same intuition, we devise a masking technique for CNNs called layer masking, which simulates running the CNN on only the unmasked input. We find that our method is (i) much less disruptive to the model's output and its intermediate activations, and (ii) much better than commonly used masking techniques for input perturbation based interpretability techniques like LIME. Thus, layer masking is able to close the interpretability gap between CNNs and transformers, and even make CNNs more interpretable in many cases.