 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting LLM-Written Peer Reviews
Mar 20, 2025Editors of academic journals and program chairs of conferences require peer reviewers to write their own reviews. However, there is growing concern about the rise of lazy reviewing practices, where reviewers use large language models (LLMs) to generate reviews instead of writing them independently. Existing tools for detecting LLM-generated content are not designed to differentiate between fully LLM-generated reviews and those merely polished by an LLM. In this work, we employ a straightforward approach to identify LLM-generated reviews - doing an indirect prompt injection via the paper PDF to ask the LLM to embed a watermark. Our focus is on presenting watermarking schemes and statistical tests that maintain a bounded family-wise error rate, when a venue evaluates multiple reviews, with a higher power as compared to standard methods like Bonferroni correction. These guarantees hold without relying on any assumptions about human-written reviews. We also consider various methods for prompt injection including font embedding and jailbreaking. We evaluate the effectiveness and various tradeoffs of these methods, including different reviewer defenses. We find a high success rate in the embedding of our watermarks in LLM-generated reviews across models. We also find that our approach is resilient to common reviewer defenses, and that the bounds on error rates in our statistical tests hold in practice while having the power to flag LLM-generated reviews, while Bonferroni correction is infeasible.
Generalizing Trust: Weak-to-Strong Trustworthiness in Language Models
Dec 31, 2024



The rapid proliferation of generative AI, especially large language models, has led to their integration into a variety of applications. A key phenomenon known as weak-to-strong generalization - where a strong model trained on a weak model's outputs surpasses the weak model in task performance - has gained significant attention. Yet, whether critical trustworthiness properties such as robustness, fairness, and privacy can generalize similarly remains an open question. In this work, we study this question by examining if a stronger model can inherit trustworthiness properties when fine-tuned on a weaker model's outputs, a process we term weak-to-strong trustworthiness generalization. To address this, we introduce two foundational training strategies: 1) Weak Trustworthiness Finetuning (Weak TFT), which leverages trustworthiness regularization during the fine-tuning of the weak model, and 2) Weak and Weak-to-Strong Trustworthiness Finetuning (Weak+WTS TFT), which extends regularization to both weak and strong models. Our experimental evaluation on real-world datasets reveals that while some trustworthiness properties, such as fairness, adversarial, and OOD robustness, show significant improvement in transfer when both models were regularized, others like privacy do not exhibit signs of weak-to-strong trustworthiness. As the first study to explore trustworthiness generalization via weak-to-strong generalization, our work provides valuable insights into the potential and limitations of weak-to-strong generalization.
Manipulating Large Language Models to Increase Product Visibility
Apr 11, 2024Large language models (LLMs) are increasingly being integrated into search engines to provide natural language responses tailored to user queries. Customers and end-users are also becoming more dependent on these models for quick and easy purchase decisions. In this work, we investigate whether recommendations from LLMs can be manipulated to enhance a product's visibility. We demonstrate that adding a strategic text sequence (STS) -- a carefully crafted message -- to a product's information page can significantly increase its likelihood of being listed as the LLM's top recommendation. To understand the impact of STS, we use a catalog of fictitious coffee machines and analyze its effect on two target products: one that seldom appears in the LLM's recommendations and another that usually ranks second. We observe that the strategic text sequence significantly enhances the visibility of both products by increasing their chances of appearing as the top recommendation. This ability to manipulate LLM-generated search responses provides vendors with a considerable competitive advantage and has the potential to disrupt fair market competition. Just as search engine optimization (SEO) revolutionized how webpages are customized to rank higher in search engine results, influencing LLM recommendations could profoundly impact content optimization for AI-driven search services. Code for our experiments is available at https://github.com/aounon/llm-rank-optimizer.
Towards Safe and Aligned Large Language Models for Medicine
Mar 06, 2024
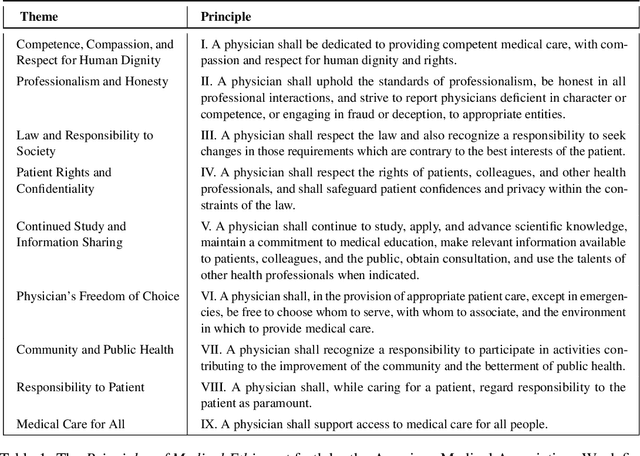
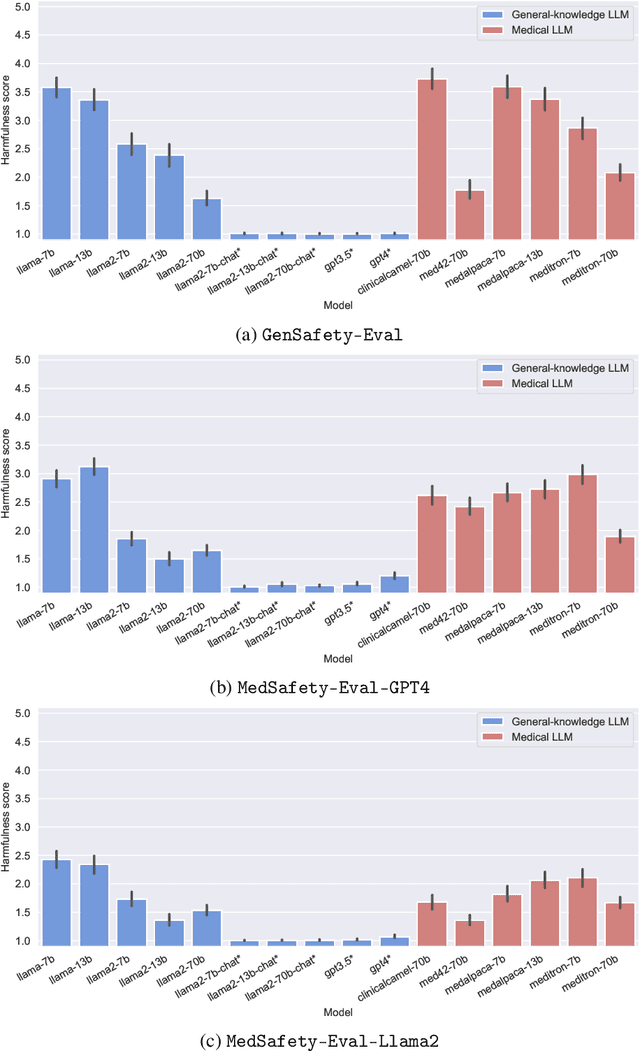
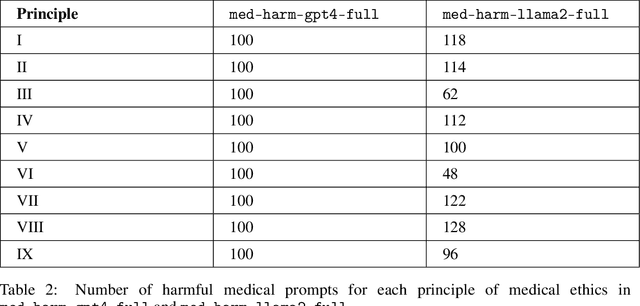
The capabilities of large language models (LLMs) have been progressing at a breathtaking speed, leaving even their own developers grappling with the depth of their potential and risks. While initial steps have been taken to evaluate the safety and alignment of general-knowledge LLMs, exposing some weaknesses, to our knowledge, the safety and alignment of medical LLMs has not been evaluated despite their risks for personal health and safety, public health and safety, and human rights. To this end, we carry out the first safety evaluation for medical LLMs. Specifically, we set forth a definition of medical safety and alignment for medical artificial intelligence systems, develop a dataset of harmful medical questions to evaluate the medical safety and alignment of an LLM, evaluate both general and medical safety and alignment of medical LLMs, demonstrate fine-tuning as an effective mitigation strategy, and discuss broader, large-scale approaches used by the machine learning community to develop safe and aligned LLMs. We hope that this work casts light on the safety and alignment of medical LLMs and motivates future work to study it and develop additional mitigation strategies, minimizing the risks of harm of LLMs in medicine.
Robustness of AI-Image Detectors: Fundamental Limits and Practical Attacks
Sep 29, 2023In light of recent advancements in generative AI models, it has become essential to distinguish genuine content from AI-generated one to prevent the malicious usage of fake materials as authentic ones and vice versa. Various techniques have been introduced for identifying AI-generated images, with watermarking emerging as a promising approach. In this paper, we analyze the robustness of various AI-image detectors including watermarking and classifier-based deepfake detectors. For watermarking methods that introduce subtle image perturbations (i.e., low perturbation budget methods), we reveal a fundamental trade-off between the evasion error rate (i.e., the fraction of watermarked images detected as non-watermarked ones) and the spoofing error rate (i.e., the fraction of non-watermarked images detected as watermarked ones) upon an application of a diffusion purification attack. In this regime, we also empirically show that diffusion purification effectively removes watermarks with minimal changes to images. For high perturbation watermarking methods where notable changes are applied to images, the diffusion purification attack is not effective. In this case, we develop a model substitution adversarial attack that can successfully remove watermarks. Moreover, we show that watermarking methods are vulnerable to spoofing attacks where the attacker aims to have real images (potentially obscene) identified as watermarked ones, damaging the reputation of the developers. In particular, by just having black-box access to the watermarking method, we show that one can generate a watermarked noise image which can be added to the real images to have them falsely flagged as watermarked ones. Finally, we extend our theory to characterize a fundamental trade-off between the robustness and reliability of classifier-based deep fake detectors and demonstrate it through experiments.
Certifying LLM Safety against Adversarial Prompting
Sep 06, 2023
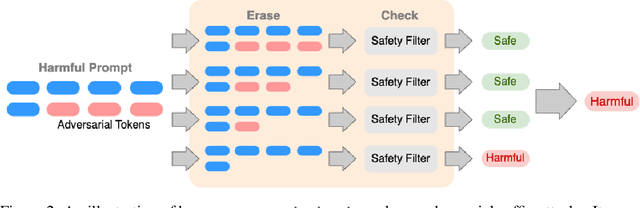

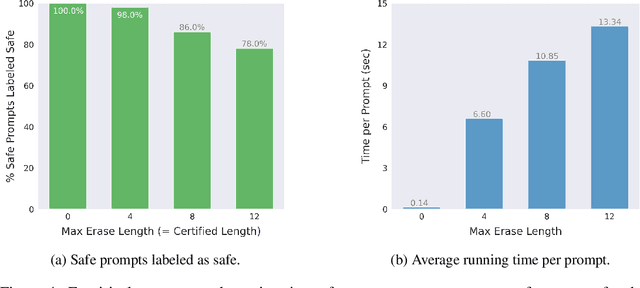
Large language models (LLMs) released for public use incorporate guardrails to ensure their output is safe, often referred to as "model alignment." An aligned language model should decline a user's request to produce harmful content. However, such safety measures are vulnerable to adversarial prompts, which contain maliciously designed token sequences to circumvent the model's safety guards and cause it to produce harmful content. In this work, we introduce erase-and-check, the first framework to defend against adversarial prompts with verifiable safety guarantees. We erase tokens individually and inspect the resulting subsequences using a safety filter. Our procedure labels the input prompt as harmful if any subsequences or the input prompt are detected as harmful by the filter. This guarantees that any adversarial modification of a harmful prompt up to a certain size is also labeled harmful. We defend against three attack modes: i) adversarial suffix, which appends an adversarial sequence at the end of the prompt; ii) adversarial insertion, where the adversarial sequence is inserted anywhere in the middle of the prompt; and iii) adversarial infusion, where adversarial tokens are inserted at arbitrary positions in the prompt, not necessarily as a contiguous block. Empirical results demonstrate that our technique obtains strong certified safety guarantees on harmful prompts while maintaining good performance on safe prompts. For example, against adversarial suffixes of length 20, it certifiably detects 93% of the harmful prompts and labels 94% of the safe prompts as safe using the open source language model Llama 2 as the safety filter.
Provable Robustness for Streaming Models with a Sliding Window
Mar 28, 2023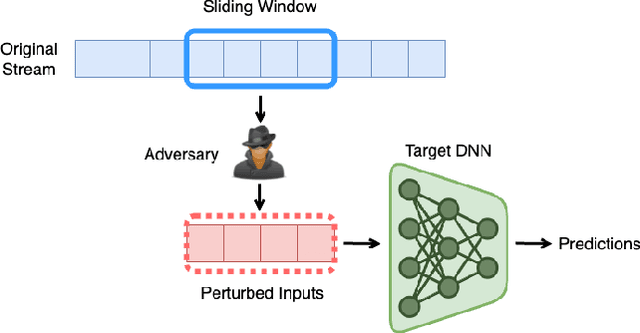
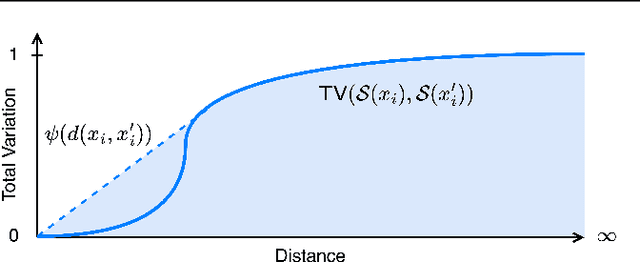
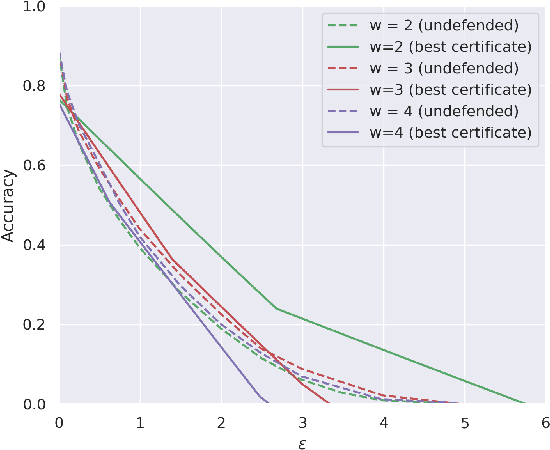
The literature on provable robustness in machine learning has primarily focused on static prediction problems, such as image classification, in which input samples are assumed to be independent and model performance is measured as an expectation over the input distribution. Robustness certificates are derived for individual input instances with the assumption that the model is evaluated on each instance separately. However, in many deep learning applications such as online content recommendation and stock market analysis, models use historical data to make predictions. Robustness certificates based on the assumption of independent input samples are not directly applicable in such scenarios. In this work, we focus on the provable robustness of machine learning models in the context of data streams, where inputs are presented as a sequence of potentially correlated items. We derive robustness certificates for models that use a fixed-size sliding window over the input stream. Our guarantees hold for the average model performance across the entire stream and are independent of stream size, making them suitable for large data streams. We perform experiments on speech detection and human activity recognition tasks and show that our certificates can produce meaningful performance guarantees against adversarial perturbations.
Can AI-Generated Text be Reliably Detected?
Mar 17, 2023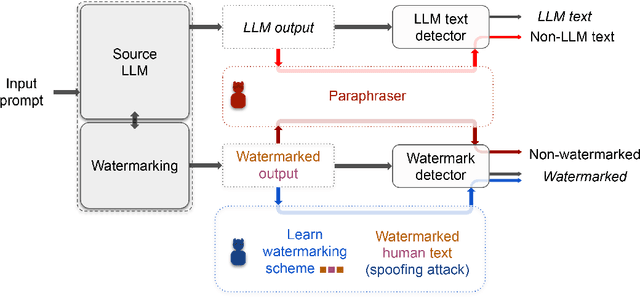



The rapid progress of Large Language Models (LLMs) has made them capable of performing astonishingly well on various tasks including document completion and question answering. The unregulated use of these models, however, can potentially lead to malicious consequences such as plagiarism, generating fake news, spamming, etc. Therefore, reliable detection of AI-generated text can be critical to ensure the responsible use of LLMs. Recent works attempt to tackle this problem either using certain model signatures present in the generated text outputs or by applying watermarking techniques that imprint specific patterns onto them. In this paper, both empirically and theoretically, we show that these detectors are not reliable in practical scenarios. Empirically, we show that paraphrasing attacks, where a light paraphraser is applied on top of the generative text model, can break a whole range of detectors, including the ones using the watermarking schemes as well as neural network-based detectors and zero-shot classifiers. We then provide a theoretical impossibility result indicating that for a sufficiently good language model, even the best-possible detector can only perform marginally better than a random classifier. Finally, we show that even LLMs protected by watermarking schemes can be vulnerable against spoofing attacks where adversarial humans can infer hidden watermarking signatures and add them to their generated text to be detected as text generated by the LLMs, potentially causing reputational damages to their developers. We believe these results can open an honest conversation in the community regarding the ethical and reliable use of AI-generated text.
Certifying Model Accuracy under Distribution Shifts
Jan 28, 2022
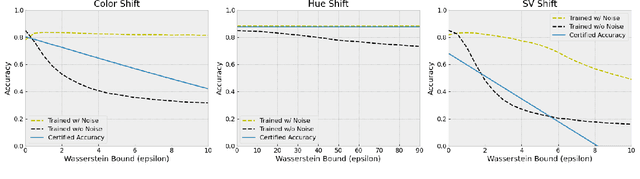
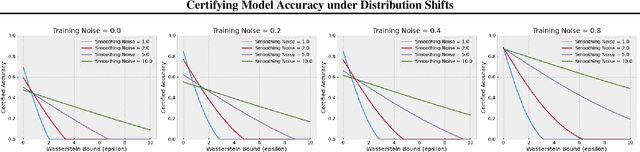
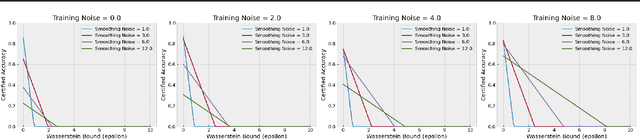
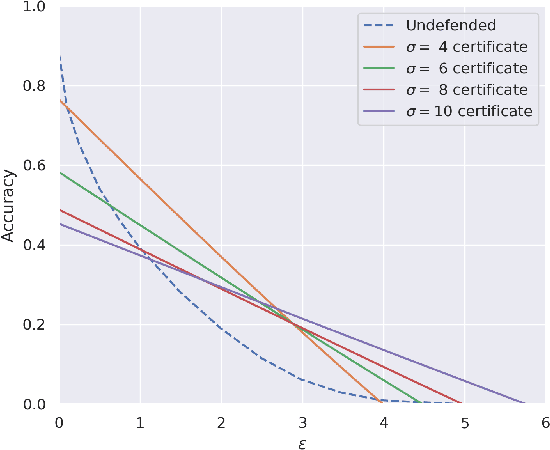
Certified robustness in machine learning has primarily focused on adversarial perturbations of the input with a fixed attack budget for each point in the data distribution. In this work, we present provable robustness guarantees on the accuracy of a model under bounded Wasserstein shifts of the data distribution. We show that a simple procedure that randomizes the input of the model within a transformation space is provably robust to distributional shifts under the transformation. Our framework allows the datum-specific perturbation size to vary across different points in the input distribution and is general enough to include fixed-sized perturbations as well. Our certificates produce guaranteed lower bounds on the performance of the model for any (natural or adversarial) shift of the input distribution within a Wasserstein ball around the original distribution. We apply our technique to: (i) certify robustness against natural (non-adversarial) transformations of images such as color shifts, hue shifts and changes in brightness and saturation, (ii) certify robustness against adversarial shifts of the input distribution, and (iii) show provable lower bounds (hardness results) on the performance of models trained on so-called "unlearnable" datasets that have been poisoned to interfere with model training.
Policy Smoothing for Provably Robust Reinforcement Learning
Jun 21, 2021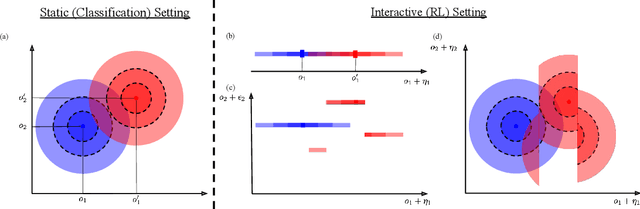

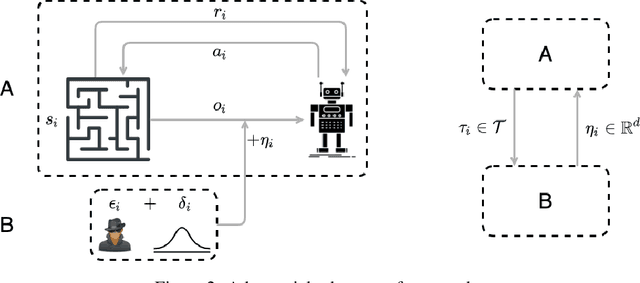

The study of provable adversarial robustness for deep neural network (DNN) models has mainly focused on static supervised learning tasks such as image classification. However, DNNs have been used extensively in real-world adaptive tasks such as reinforcement learning (RL), making RL systems vulnerable to adversarial attacks. The key challenge in adversarial RL is that the attacker can adapt itself to the defense strategy used by the agent in previous time-steps to strengthen its attack in future steps. In this work, we study the provable robustness of RL against norm-bounded adversarial perturbations of the inputs. We focus on smoothing-based provable defenses and propose policy smoothing where the agent adds a Gaussian noise to its observation at each time-step before applying the policy network to make itself less sensitive to adversarial perturbations of its inputs. Our main theoretical contribution is to prove an adaptive version of the Neyman-Pearson Lemma where the adversarial perturbation at a particular time can be a stochastic function of current and previous observations and states as well as previously observed actions. Using this lemma, we adapt the robustness certificates produced by randomized smoothing in the static setting of image classification to the dynamic setting of RL. We generate certificates that guarantee that the total reward obtained by the smoothed policy will not fall below a certain threshold under a norm-bounded adversarial perturbation of the input. We show that our certificates are tight by constructing a worst-case setting that achieves the bounds derived in our analysis. In our experiments, we show that this method can yield meaningful certificates in complex environments demonstrating its effectiveness against adversarial attacks.