 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Decay Improves Language Model Plasticity
Feb 11, 2026The prevailing paradigm in large language model (LLM) development is to pretrain a base model, then perform further training to improve performance and model behavior. However, hyperparameter optimization and scaling laws have been studied primarily from the perspective of the base model's validation loss, ignoring downstream adaptability. In this work, we study pretraining from the perspective of model plasticity, that is, the ability of the base model to successfully adapt to downstream tasks through fine-tuning. We focus on the role of weight decay, a key regularization parameter during pretraining. Through systematic experiments, we show that models trained with larger weight decay values are more plastic, meaning they show larger performance gains when fine-tuned on downstream tasks. This phenomenon can lead to counterintuitive trade-offs where base models that perform worse after pretraining can perform better after fine-tuning. Further investigation of weight decay's mechanistic effects on model behavior reveals that it encourages linearly separable representations, regularizes attention matrices, and reduces overfitting on the training data. In conclusion, this work demonstrates the importance of using evaluation metrics beyond cross-entropy loss for hyperparameter optimization and casts light on the multifaceted role of that a single optimization hyperparameter plays in shaping model behavior.
Building Bridges, Not Walls -- Advancing Interpretability by Unifying Feature, Data, and Model Component Attribution
Jan 31, 2025



The increasing complexity of AI systems has made understanding their behavior a critical challenge. Numerous methods have been developed to attribute model behavior to three key aspects: input features, training data, and internal model components. However, these attribution methods are studied and applied rather independently, resulting in a fragmented landscape of approaches and terminology. This position paper argues that feature, data, and component attribution methods share fundamental similarities, and bridging them can benefit interpretability research. We conduct a detailed analysis of successful methods across three domains and present a unified view to demonstrate that these seemingly distinct methods employ similar approaches, such as perturbations, gradients, and linear approximations, differing primarily in their perspectives rather than core techniques. Our unified perspective enhances understanding of existing attribution methods, identifies shared concepts and challenges, makes this field more accessible to newcomers, and highlights new directions not only for attribution and interpretability but also for broader AI research, including model editing, steering, and regulation.
Towards Safe and Aligned Large Language Models for Medicine
Mar 06, 2024
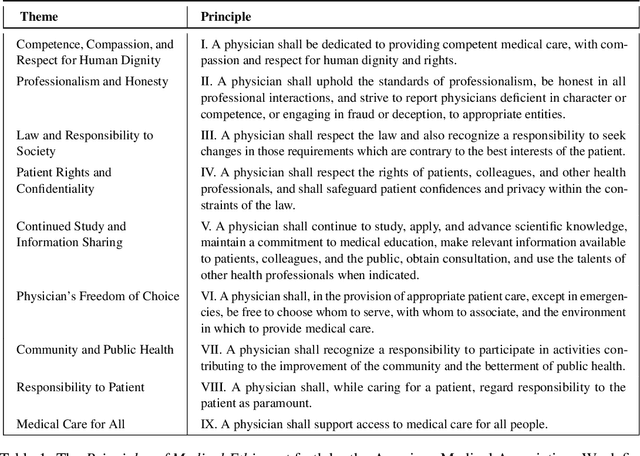
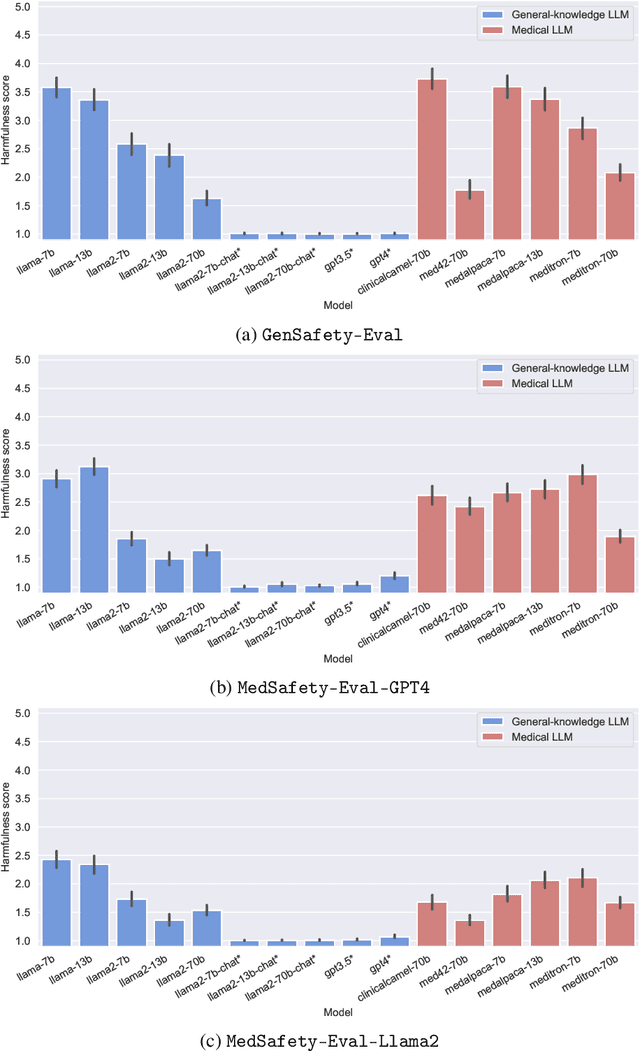
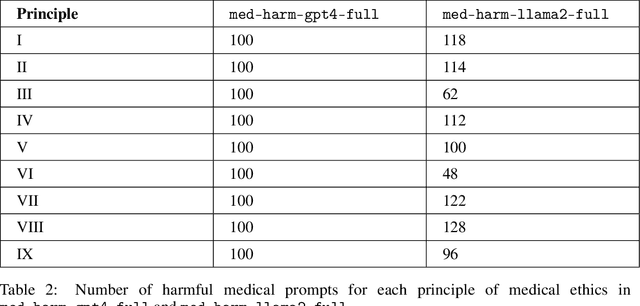
The capabilities of large language models (LLMs) have been progressing at a breathtaking speed, leaving even their own developers grappling with the depth of their potential and risks. While initial steps have been taken to evaluate the safety and alignment of general-knowledge LLMs, exposing some weaknesses, to our knowledge, the safety and alignment of medical LLMs has not been evaluated despite their risks for personal health and safety, public health and safety, and human rights. To this end, we carry out the first safety evaluation for medical LLMs. Specifically, we set forth a definition of medical safety and alignment for medical artificial intelligence systems, develop a dataset of harmful medical questions to evaluate the medical safety and alignment of an LLM, evaluate both general and medical safety and alignment of medical LLMs, demonstrate fine-tuning as an effective mitigation strategy, and discuss broader, large-scale approaches used by the machine learning community to develop safe and aligned LLMs. We hope that this work casts light on the safety and alignment of medical LLMs and motivates future work to study it and develop additional mitigation strategies, minimizing the risks of harm of LLMs in medicine.
Efficient Estimation of the Local Robustness of Machine Learning Models
Jul 26, 2023Machine learning models often need to be robust to noisy input data. The effect of real-world noise (which is often random) on model predictions is captured by a model's local robustness, i.e., the consistency of model predictions in a local region around an input. However, the na\"ive approach to computing local robustness based on Monte-Carlo sampling is statistically inefficient, leading to prohibitive computational costs for large-scale applications. In this work, we develop the first analytical estimators to efficiently compute local robustness of multi-class discriminative models using local linear function approximation and the multivariate Normal CDF. Through the derivation of these estimators, we show how local robustness is connected to concepts such as randomized smoothing and softmax probability. We also confirm empirically that these estimators accurately and efficiently compute the local robustness of standard deep learning models. In addition, we demonstrate these estimators' usefulness for various tasks involving local robustness, such as measuring robustness bias and identifying examples that are vulnerable to noise perturbation in a dataset. By developing these analytical estimators, this work not only advances conceptual understanding of local robustness, but also makes its computation practical, enabling the use of local robustness in critical downstream applications.
Which Explanation Should I Choose? A Function Approximation Perspective to Characterizing Post hoc Explanations
Jun 02, 2022

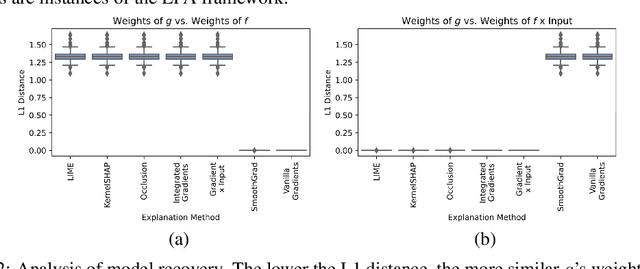
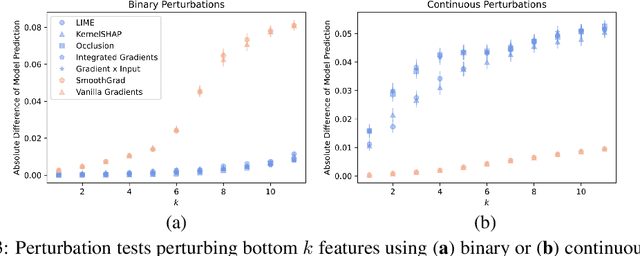
Despite the plethora of post hoc model explanation methods, the basic properties and behavior of these methods and the conditions under which each one is effective are not well understood. In this work, we bridge these gaps and address a fundamental question: Which explanation method should one use in a given situation? To this end, we adopt a function approximation perspective and formalize the local function approximation (LFA) framework. We show that popular explanation methods are instances of this framework, performing function approximations of the underlying model in different neighborhoods using different loss functions. We introduce a no free lunch theorem for explanation methods which demonstrates that no single method can perform optimally across all neighbourhoods and calls for choosing among methods. To choose among methods, we set forth a guiding principle based on the function approximation perspective, considering a method to be effective if it recovers the underlying model when the model is a member of the explanation function class. Then, we analyze the conditions under which popular explanation methods are effective and provide recommendations for choosing among explanation methods and creating new ones. Lastly, we empirically validate our theoretical results using various real world datasets, model classes, and prediction tasks. By providing a principled mathematical framework which unifies diverse explanation methods, our work characterizes the behaviour of these methods and their relation to one another, guides the choice of explanation methods, and paves the way for the creation of new ones.
The Disagreement Problem in Explainable Machine Learning: A Practitioner's Perspective
Feb 08, 2022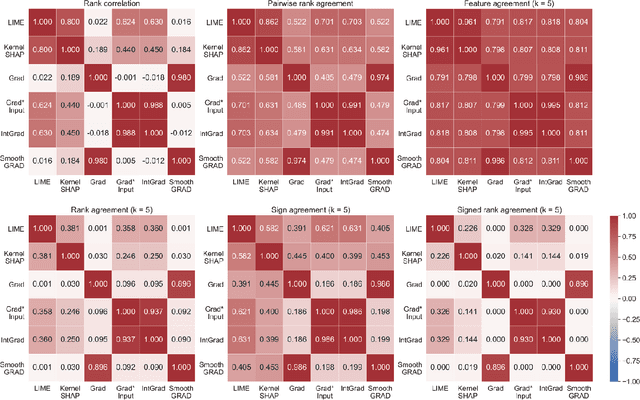

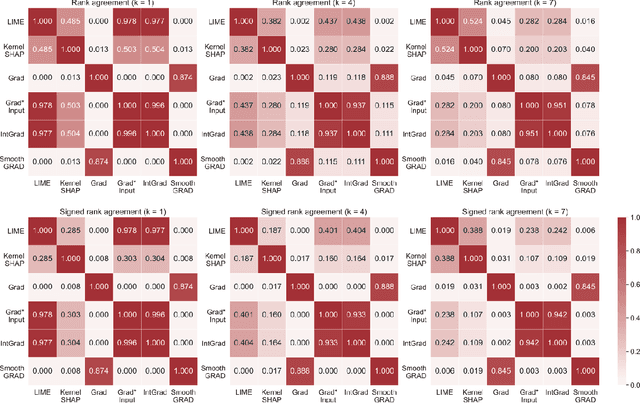
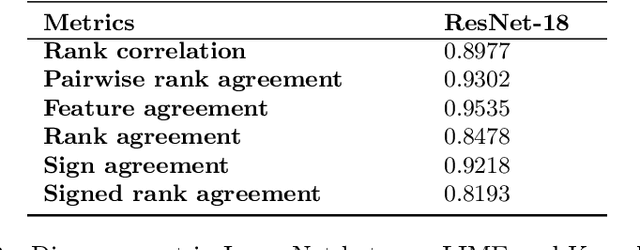
As various post hoc explanation methods are increasingly being leveraged to explain complex models in high-stakes settings, it becomes critical to develop a deeper understanding of if and when the explanations output by these methods disagree with each other, and how such disagreements are resolved in practice. However, there is little to no research that provides answers to these critical questions. In this work, we introduce and study the disagreement problem in explainable machine learning. More specifically, we formalize the notion of disagreement between explanations, analyze how often such disagreements occur in practice, and how do practitioners resolve these disagreements. To this end, we first conduct interviews with data scientists to understand what constitutes disagreement between explanations generated by different methods for the same model prediction, and introduce a novel quantitative framework to formalize this understanding. We then leverage this framework to carry out a rigorous empirical analysis with four real-world datasets, six state-of-the-art post hoc explanation methods, and eight different predictive models, to measure the extent of disagreement between the explanations generated by various popular explanation methods. In addition, we carry out an online user study with data scientists to understand how they resolve the aforementioned disagreements. Our results indicate that state-of-the-art explanation methods often disagree in terms of the explanations they output. Our findings also underscore the importance of developing principled evaluation metrics that enable practitioners to effectively compare explanations.