 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Bridges, Not Walls -- Advancing Interpretability by Unifying Feature, Data, and Model Component Attribution
Jan 31, 2025



The increasing complexity of AI systems has made understanding their behavior a critical challenge. Numerous methods have been developed to attribute model behavior to three key aspects: input features, training data, and internal model components. However, these attribution methods are studied and applied rather independently, resulting in a fragmented landscape of approaches and terminology. This position paper argues that feature, data, and component attribution methods share fundamental similarities, and bridging them can benefit interpretability research. We conduct a detailed analysis of successful methods across three domains and present a unified view to demonstrate that these seemingly distinct methods employ similar approaches, such as perturbations, gradients, and linear approximations, differing primarily in their perspectives rather than core techniques. Our unified perspective enhances understanding of existing attribution methods, identifies shared concepts and challenges, makes this field more accessible to newcomers, and highlights new directions not only for attribution and interpretability but also for broader AI research, including model editing, steering, and regulation.
A Study on the Calibration of In-context Learning
Dec 11, 2023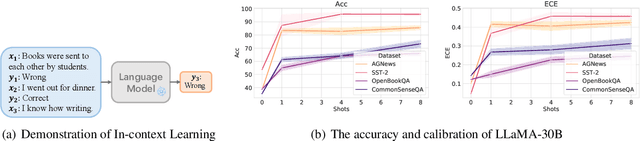

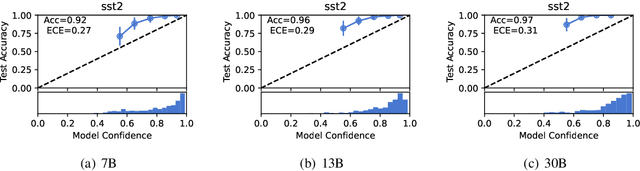
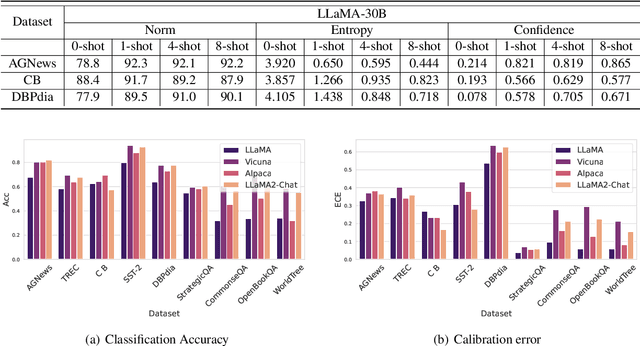
Modern auto-regressive language models are trained to minimize log loss on broad data by predicting the next token so they are expected to get calibrated answers in next-token prediction tasks. We study this for in-context learning (ICL), a widely used way to adapt frozen large language models (LLMs) via crafting prompts, and investigate the trade-offs between performance and calibration on a wide range of natural language understanding and reasoning tasks. We conduct extensive experiments to show that such trade-offs may get worse as we increase model size, incorporate more ICL examples, and fine-tune models using instruction, dialog, or reinforcement learning from human feedback (RLHF) on carefully curated datasets. Furthermore, we find that common recalibration techniques that are widely effective such as temperature scaling provide limited gains in calibration errors, suggesting that new methods may be required for settings where models are expected to be reliable.
Certifying LLM Safety against Adversarial Prompting
Sep 06, 2023
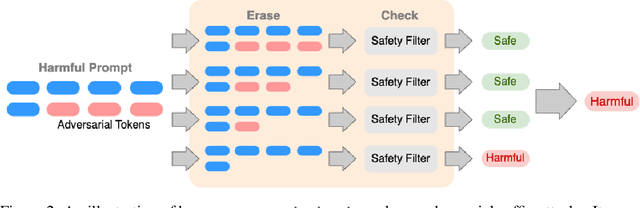

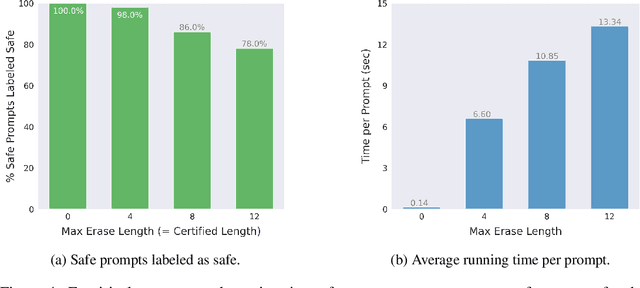
Large language models (LLMs) released for public use incorporate guardrails to ensure their output is safe, often referred to as "model alignment." An aligned language model should decline a user's request to produce harmful content. However, such safety measures are vulnerable to adversarial prompts, which contain maliciously designed token sequences to circumvent the model's safety guards and cause it to produce harmful content. In this work, we introduce erase-and-check, the first framework to defend against adversarial prompts with verifiable safety guarantees. We erase tokens individually and inspect the resulting subsequences using a safety filter. Our procedure labels the input prompt as harmful if any subsequences or the input prompt are detected as harmful by the filter. This guarantees that any adversarial modification of a harmful prompt up to a certain size is also labeled harmful. We defend against three attack modes: i) adversarial suffix, which appends an adversarial sequence at the end of the prompt; ii) adversarial insertion, where the adversarial sequence is inserted anywhere in the middle of the prompt; and iii) adversarial infusion, where adversarial tokens are inserted at arbitrary positions in the prompt, not necessarily as a contiguous block. Empirical results demonstrate that our technique obtains strong certified safety guarantees on harmful prompts while maintaining good performance on safe prompts. For example, against adversarial suffixes of length 20, it certifiably detects 93% of the harmful prompts and labels 94% of the safe prompts as safe using the open source language model Llama 2 as the safety filter.
Fair Machine Unlearning: Data Removal while Mitigating Disparities
Jul 27, 2023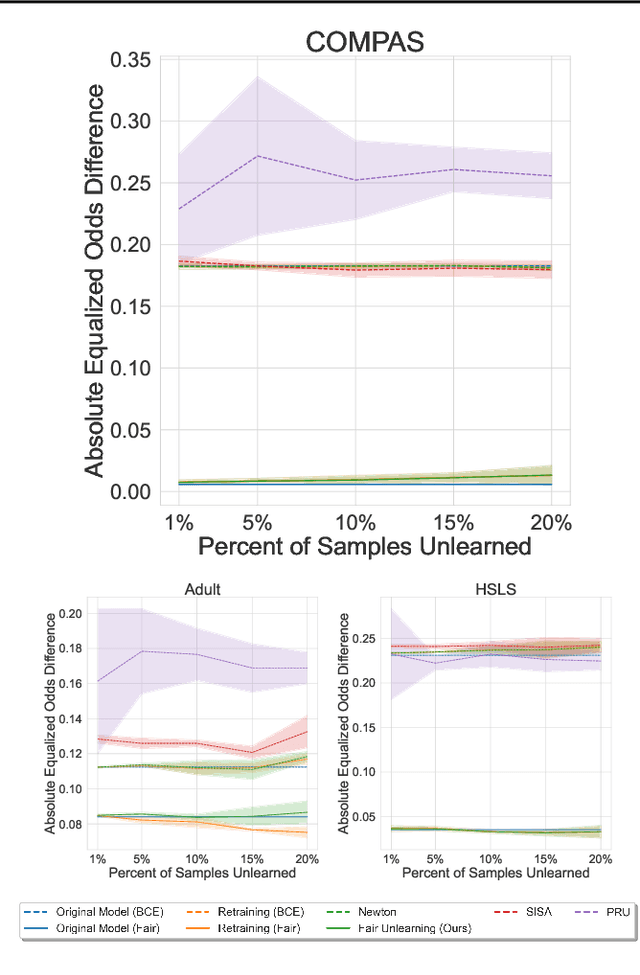
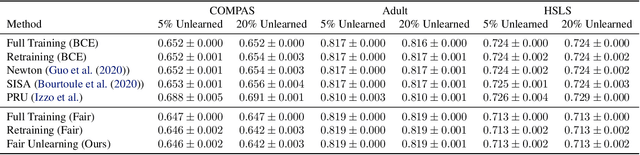
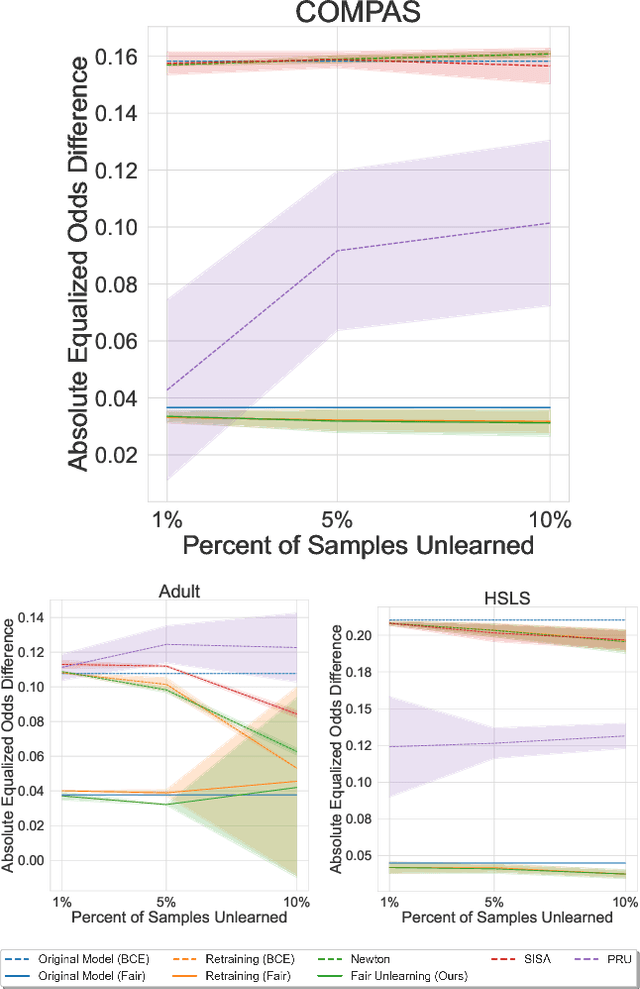
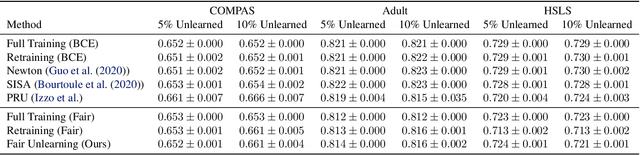
As public consciousness regarding the collection and use of personal information by corporations grows, it is of increasing importance that consumers be active participants in the curation of corporate datasets. In light of this, data governance frameworks such as the General Data Protection Regulation (GDPR) have outlined the right to be forgotten as a key principle allowing individuals to request that their personal data be deleted from the databases and models used by organizations. To achieve forgetting in practice, several machine unlearning methods have been proposed to address the computational inefficiencies of retraining a model from scratch with each unlearning request. While efficient online alternatives to retraining, it is unclear how these methods impact other properties critical to real-world applications, such as fairness. In this work, we propose the first fair machine unlearning method that can provably and efficiently unlearn data instances while preserving group fairness. We derive theoretical results which demonstrate that our method can provably unlearn data instances while maintaining fairness objectives. Extensive experimentation with real-world datasets highlight the efficacy of our method at unlearning data instances while preserving fairness.
Which Models have Perceptually-Aligned Gradients? An Explanation via Off-Manifold Robustness
May 30, 2023



One of the remarkable properties of robust computer vision models is that their input-gradients are often aligned with human perception, referred to in the literature as perceptually-aligned gradients (PAGs). Despite only being trained for classification, PAGs cause robust models to have rudimentary generative capabilities, including image generation, denoising, and in-painting. However, the underlying mechanisms behind these phenomena remain unknown. In this work, we provide a first explanation of PAGs via \emph{off-manifold robustness}, which states that models must be more robust off- the data manifold than they are on-manifold. We first demonstrate theoretically that off-manifold robustness leads input gradients to lie approximately on the data manifold, explaining their perceptual alignment. We then show that Bayes optimal models satisfy off-manifold robustness, and confirm the same empirically for robust models trained via gradient norm regularization, noise augmentation, and randomized smoothing. Quantifying the perceptual alignment of model gradients via their similarity with the gradients of generative models, we show that off-manifold robustness correlates well with perceptual alignment. Finally, based on the levels of on- and off-manifold robustness, we identify three different regimes of robustness that affect both perceptual alignment and model accuracy: weak robustness, bayes-aligned robustness, and excessive robustness.