 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSA-Tokenizer: Disentangled Semantic-Acoustic Tokenization via Flow Matching-based Hierarchical Fusion
Jan 15, 2026Speech tokenizers serve as the cornerstone of discrete Speech Large Language Models (Speech LLMs). Existing tokenizers either prioritize semantic encoding, fuse semantic content with acoustic style inseparably, or achieve incomplete semantic-acoustic disentanglement. To achieve better disentanglement, we propose DSA-Tokenizer, which explicitly disentangles speech into discrete semantic and acoustic tokens via distinct optimization constraints. Specifically, semantic tokens are supervised by ASR to capture linguistic content, while acoustic tokens focus on mel-spectrograms restoration to encode style. To eliminate rigid length constraints between the two sequences, we introduce a hierarchical Flow-Matching decoder that further improve speech generation quality. Furthermore, We employ a joint reconstruction-recombination training strategy to enforce this separation. DSA-Tokenizer enables high fidelity reconstruction and flexible recombination through robust disentanglement, facilitating controllable generation in speech LLMs. Our analysis highlights disentangled tokenization as a pivotal paradigm for future speech modeling. Audio samples are avaialble at https://anonymous.4open.science/w/DSA_Tokenizer_demo/. The code and model will be made publicly available after the paper has been accepted.
Discovering Hierarchical Latent Capabilities of Language Models via Causal Representation Learning
Jun 12, 2025Faithful evaluation of language model capabilities is crucial for deriving actionable insights that can inform model development. However, rigorous causal evaluations in this domain face significant methodological challenges, including complex confounding effects and prohibitive computational costs associated with extensive retraining. To tackle these challenges, we propose a causal representation learning framework wherein observed benchmark performance is modeled as a linear transformation of a few latent capability factors. Crucially, these latent factors are identified as causally interrelated after appropriately controlling for the base model as a common confounder. Applying this approach to a comprehensive dataset encompassing over 1500 models evaluated across six benchmarks from the Open LLM Leaderboard, we identify a concise three-node linear causal structure that reliably explains the observed performance variations. Further interpretation of this causal structure provides substantial scientific insights beyond simple numerical rankings: specifically, we reveal a clear causal direction starting from general problem-solving capabilities, advancing through instruction-following proficiency, and culminating in mathematical reasoning ability. Our results underscore the essential role of carefully controlling base model variations during evaluation, a step critical to accurately uncovering the underlying causal relationships among latent model capabilities.
Connections between Schedule-Free Optimizers, AdEMAMix, and Accelerated SGD Variants
Feb 04, 2025


Recent advancements in deep learning optimization have introduced new algorithms, such as Schedule-Free optimizers, AdEMAMix, MARS and Lion which modify traditional momentum mechanisms. In a separate line of work, theoretical acceleration of stochastic gradient descent (SGD) in noise-dominated regime has been achieved by decoupling the momentum coefficient from the current gradient's weight. In this paper, we establish explicit connections between these two lines of work. We substantiate our theoretical findings with preliminary experiments on a 150m language modeling task. We find that AdEMAMix, which most closely resembles accelerated versions of stochastic gradient descent, exhibits superior performance. Building on these insights, we introduce a modification to AdEMAMix, termed Simplified-AdEMAMix, which maintains the same performance as AdEMAMix across both large and small batch-size settings while eliminating the need for two different momentum terms. The code for Simplified-AdEMAMix is available on the repository: https://github.com/DepenM/Simplified-AdEMAMix/.
Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models
Dec 03, 2024Self-improvement is a mechanism in Large Language Model (LLM) pre-training, post-training and test-time inference. We explore a framework where the model verifies its own outputs, filters or reweights data based on this verification, and distills the filtered data. Despite several empirical successes, a fundamental understanding is still lacking. In this work, we initiate a comprehensive, modular and controlled study on LLM self-improvement. We provide a mathematical formulation for self-improvement, which is largely governed by a quantity which we formalize as the generation-verification gap. Through experiments with various model families and tasks, we discover a scaling phenomenon of self-improvement -- a variant of the generation-verification gap scales monotonically with the model pre-training flops. We also examine when self-improvement is possible, an iterative self-improvement procedure, and ways to improve its performance. Our findings not only advance understanding of LLM self-improvement with practical implications, but also open numerous avenues for future research into its capabilities and boundaries.
How Does Critical Batch Size Scale in Pre-training?
Oct 29, 2024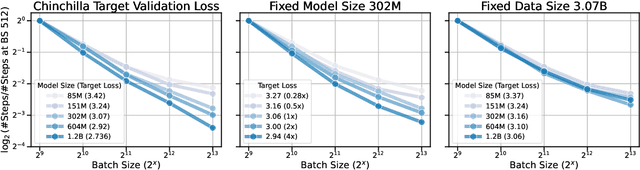

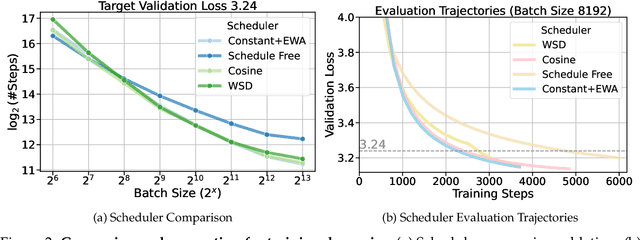
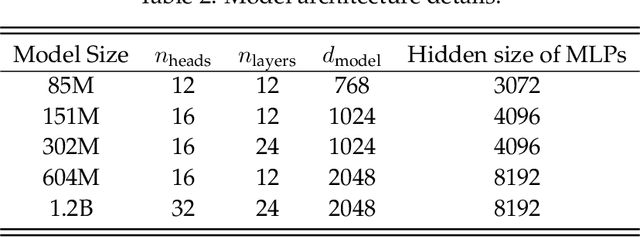
Training large-scale models under given resources requires careful design of parallelism strategies. In particular, the efficiency notion of critical batch size, concerning the compromise between time and compute, marks the threshold beyond which greater data parallelism leads to diminishing returns. To operationalize it, we propose a measure of CBS and pre-train a series of auto-regressive language models, ranging from 85 million to 1.2 billion parameters, on the C4 dataset. Through extensive hyper-parameter sweeps and careful control on factors such as batch size, momentum, and learning rate along with its scheduling, we systematically investigate the impact of scale on CBS. Then we fit scaling laws with respect to model and data sizes to decouple their effects. Overall, our results demonstrate that CBS scales primarily with data size rather than model size, a finding we justify theoretically through the analysis of infinite-width limits of neural networks and infinite-dimensional least squares regression. Of independent interest, we highlight the importance of common hyper-parameter choices and strategies for studying large-scale pre-training beyond fixed training durations.
Eliminating Position Bias of Language Models: A Mechanistic Approach
Jul 01, 2024
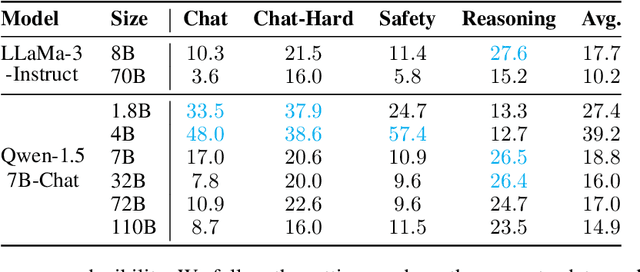


Position bias has proven to be a prevalent issue of modern language models (LMs), where the models prioritize content based on its position within the given context. This bias often leads to unexpected model failures and hurts performance, robustness, and reliability across various applications. Our mechanistic analysis attributes the position bias to two components employed in nearly all state-of-the-art LMs: causal attention and relative positional encodings. Specifically, we find that causal attention generally causes models to favor distant content, while relative positional encodings like RoPE prefer nearby ones based on the analysis of retrieval-augmented question answering (QA). Further, our empirical study on object detection reveals that position bias is also present in vision-language models (VLMs). Based on the above analyses, we propose to ELIMINATE position bias caused by different input segment orders (e.g., options in LM-as-a-judge, retrieved documents in QA) in a TRAINING-FREE ZERO-SHOT manner. Our method changes the causal attention to bidirectional attention between segments and utilizes model attention values to decide the relative orders of segments instead of using the order provided in input prompts, therefore enabling Position-INvariant inferencE (PINE) at the segment level. By eliminating position bias, models achieve better performance and reliability in downstream tasks where position bias widely exists, such as LM-as-a-judge and retrieval-augmented QA. Notably, PINE is especially useful when adapting LMs for evaluating reasoning pairs: it consistently provides 8 to 10 percentage points performance gains in most cases, and makes Llama-3-70B-Instruct perform even better than GPT-4-0125-preview on the RewardBench reasoning subset.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
CoLoR-Filter: Conditional Loss Reduction Filtering for Targeted Language Model Pre-training
Jun 15, 2024Selecting high-quality data for pre-training is crucial in shaping the downstream task performance of language models. A major challenge lies in identifying this optimal subset, a problem generally considered intractable, thus necessitating scalable and effective heuristics. In this work, we propose a data selection method, CoLoR-Filter (Conditional Loss Reduction Filtering), which leverages an empirical Bayes-inspired approach to derive a simple and computationally efficient selection criterion based on the relative loss values of two auxiliary models. In addition to the modeling rationale, we evaluate CoLoR-Filter empirically on two language modeling tasks: (1) selecting data from C4 for domain adaptation to evaluation on Books and (2) selecting data from C4 for a suite of downstream multiple-choice question answering tasks. We demonstrate favorable scaling both as we subselect more aggressively and using small auxiliary models to select data for large target models. As one headline result, CoLoR-Filter data selected using a pair of 150m parameter auxiliary models can train a 1.2b parameter target model to match a 1.2b parameter model trained on 25b randomly selected tokens with 25x less data for Books and 11x less data for the downstream tasks. Code: https://github.com/davidbrandfonbrener/color-filter-olmo Filtered data: https://huggingface.co/datasets/davidbrandfonbrener/color-filtered-c4
Follow My Instruction and Spill the Beans: Scalable Data Extraction from Retrieval-Augmented Generation Systems
Feb 27, 2024Retrieval-Augmented Generation (RAG) improves pre-trained models by incorporating external knowledge at test time to enable customized adaptation. We study the risk of datastore leakage in Retrieval-In-Context RAG Language Models (LMs). We show that an adversary can exploit LMs' instruction-following capabilities to easily extract text data verbatim from the datastore of RAG systems built with instruction-tuned LMs via prompt injection. The vulnerability exists for a wide range of modern LMs that span Llama2, Mistral/Mixtral, Vicuna, SOLAR, WizardLM, Qwen1.5, and Platypus2, and the exploitability exacerbates as the model size scales up. Extending our study to production RAG models GPTs, we design an attack that can cause datastore leakage with a 100% success rate on 25 randomly selected customized GPTs with at most 2 queries, and we extract text data verbatim at a rate of 41% from a book of 77,000 words and 3% from a corpus of 1,569,000 words by prompting the GPTs with only 100 queries generated by themselves.
A Study on the Calibration of In-context Learning
Dec 11, 2023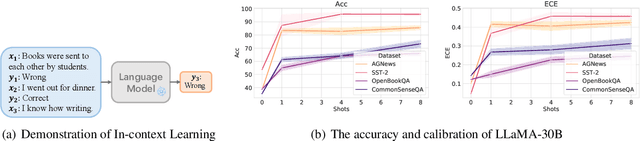

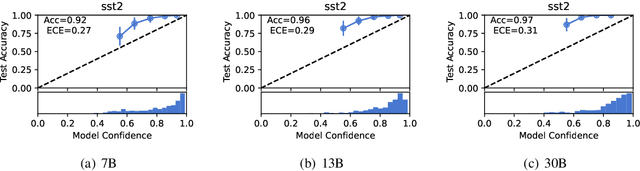
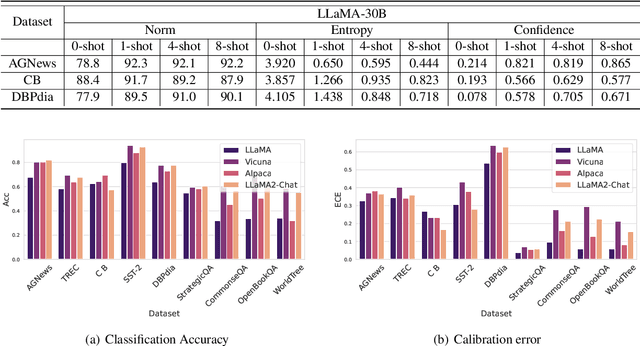
Modern auto-regressive language models are trained to minimize log loss on broad data by predicting the next token so they are expected to get calibrated answers in next-token prediction tasks. We study this for in-context learning (ICL), a widely used way to adapt frozen large language models (LLMs) via crafting prompts, and investigate the trade-offs between performance and calibration on a wide range of natural language understanding and reasoning tasks. We conduct extensive experiments to show that such trade-offs may get worse as we increase model size, incorporate more ICL examples, and fine-tune models using instruction, dialog, or reinforcement learning from human feedback (RLHF) on carefully curated datasets. Furthermore, we find that common recalibration techniques that are widely effective such as temperature scaling provide limited gains in calibration errors, suggesting that new methods may be required for settings where models are expected to be reliable.