 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Language Model Benchmarks with Pairwise Preferences
Feb 02, 2026Language model benchmarks are pervasive and computationally-efficient proxies for real-world performance. However, many recent works find that benchmarks often fail to predict real utility. Towards bridging this gap, we introduce benchmark alignment, where we use limited amounts of information about model performance to automatically update offline benchmarks, aiming to produce new static benchmarks that predict model pairwise preferences in given test settings. We then propose BenchAlign, the first solution to this problem, which learns preference-aligned weight- ings for benchmark questions using the question-level performance of language models alongside ranked pairs of models that could be collected during deployment, producing new benchmarks that rank previously unseen models according to these preferences. Our experiments show that our aligned benchmarks can accurately rank unseen models according to models of human preferences, even across different sizes, while remaining interpretable. Overall, our work provides insights into the limits of aligning benchmarks with practical human preferences, which stands to accelerate model development towards real utility.
Knowledge Graph-Assisted LLM Post-Training for Enhanced Legal Reasoning
Jan 20, 2026LLM post-training has primarily relied on large text corpora and human feedback, without capturing the structure of domain knowledge. This has caused models to struggle dealing with complex reasoning tasks, especially for high-stakes professional domains. In Law, reasoning requires deep understanding of the relations between various legal concepts, a key component missing in current LLM post-training. In this paper, we propose a knowledge graph (KG)-assisted approach for enhancing LLMs' reasoning capability in Legal that is generalizable to other high-stakes domains. We model key legal concepts by following the \textbf{IRAC} (Issue, Rule, Analysis and Conclusion) framework, and construct a KG with 12K legal cases. We then produce training data using our IRAC KG, and conduct both Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) with three state-of-the-art (SOTA) LLMs (30B, 49B and 70B), varying architecture and base model family. Our post-trained models obtained better average performance on 4/5 diverse legal benchmarks (14 tasks) than baselines. In particular, our 70B DPO model achieved the best score on 4/6 reasoning tasks, among baselines and a 141B SOTA legal LLM, demonstrating the effectiveness of our KG for enhancing LLMs' legal reasoning capability.
Scales++: Compute Efficient Evaluation Subset Selection with Cognitive Scales Embeddings
Oct 30, 2025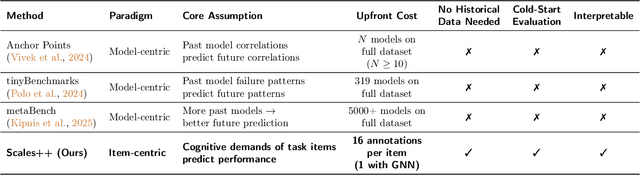
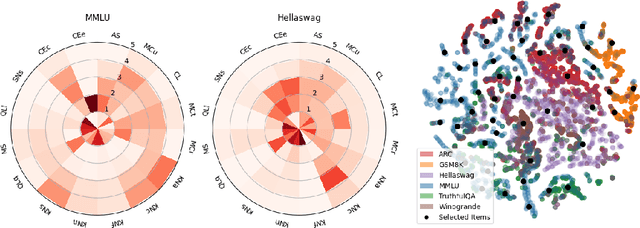
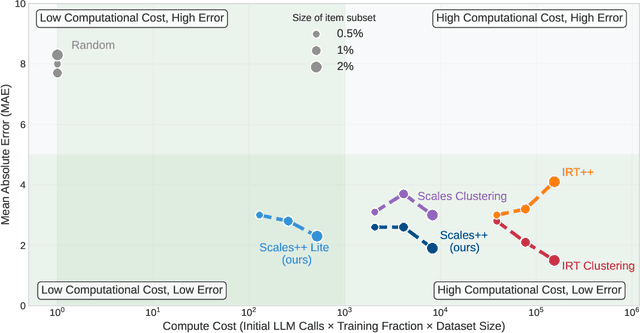
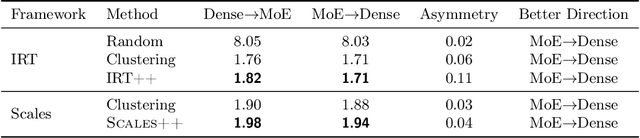
The prohibitive cost of evaluating large language models (LLMs) on comprehensive benchmarks necessitates the creation of small yet representative data subsets (i.e., tiny benchmarks) that enable efficient assessment while retaining predictive fidelity. Current methods for this task operate under a model-centric paradigm, selecting benchmarking items based on the collective performance of existing models. Such approaches are limited by large upfront costs, an inability to immediately handle new benchmarks (`cold-start'), and the fragile assumption that future models will share the failure patterns of their predecessors. In this work, we challenge this paradigm and propose a item-centric approach to benchmark subset selection, arguing that selection should be based on the intrinsic properties of the task items themselves, rather than on model-specific failure patterns. We instantiate this item-centric efficient benchmarking approach via a novel method, Scales++, where data selection is based on the cognitive demands of the benchmark samples. Empirically, we show Scales++ reduces the upfront selection cost by over 18x while achieving competitive predictive fidelity. On the Open LLM Leaderboard, using just a 0.5\% data subset, we predict full benchmark scores with a 2.9% mean absolute error. We demonstrate that this item-centric approach enables more efficient model evaluation without significant fidelity degradation, while also providing better cold-start performance and more interpretable benchmarking.
Beyond Pointwise Scores: Decomposed Criteria-Based Evaluation of LLM Responses
Sep 19, 2025Evaluating long-form answers in high-stakes domains such as law or medicine remains a fundamental challenge. Standard metrics like BLEU and ROUGE fail to capture semantic correctness, and current LLM-based evaluators often reduce nuanced aspects of answer quality into a single undifferentiated score. We introduce DeCE, a decomposed LLM evaluation framework that separates precision (factual accuracy and relevance) and recall (coverage of required concepts), using instance-specific criteria automatically extracted from gold answer requirements. DeCE is model-agnostic and domain-general, requiring no predefined taxonomies or handcrafted rubrics. We instantiate DeCE to evaluate different LLMs on a real-world legal QA task involving multi-jurisdictional reasoning and citation grounding. DeCE achieves substantially stronger correlation with expert judgments ($r=0.78$), compared to traditional metrics ($r=0.12$), pointwise LLM scoring ($r=0.35$), and modern multidimensional evaluators ($r=0.48$). It also reveals interpretable trade-offs: generalist models favor recall, while specialized models favor precision. Importantly, only 11.95% of LLM-generated criteria required expert revision, underscoring DeCE's scalability. DeCE offers an interpretable and actionable LLM evaluation framework in expert domains.
Automatic Expert Discovery in LLM Upcycling via Sparse Interpolated Mixture-of-Experts
Jun 14, 2025We present Sparse Interpolated Mixture-of-Experts (SIMoE) instruction-tuning, an end-to-end algorithm designed to fine-tune a dense pre-trained Large Language Model (LLM) into a MoE-style model that possesses capabilities in multiple specialized domains. During instruction-tuning, SIMoE automatically identifies multiple specialized experts under a specified sparsity constraint, with each expert representing a structurally sparse subset of the seed LLM's parameters that correspond to domain-specific knowledge within the data. SIMoE simultaneously learns an input-dependent expert merging strategy via a router network, leveraging rich cross-expert knowledge for superior downstream generalization that surpasses existing baselines. Empirically, SIMoE consistently achieves state-of-the-art performance on common instruction-tuning benchmarks while maintaining an optimal performance-compute trade-off compared to all baselines.
Composable Interventions for Language Models
Jul 09, 2024



Test-time interventions for language models can enhance factual accuracy, mitigate harmful outputs, and improve model efficiency without costly retraining. But despite a flood of new methods, different types of interventions are largely developing independently. In practice, multiple interventions must be applied sequentially to the same model, yet we lack standardized ways to study how interventions interact. We fill this gap by introducing composable interventions, a framework to study the effects of using multiple interventions on the same language models, featuring new metrics and a unified codebase. Using our framework, we conduct extensive experiments and compose popular methods from three emerging intervention categories -- Knowledge Editing, Model Compression, and Machine Unlearning. Our results from 310 different compositions uncover meaningful interactions: compression hinders editing and unlearning, composing interventions hinges on their order of application, and popular general-purpose metrics are inadequate for assessing composability. Taken together, our findings showcase clear gaps in composability, suggesting a need for new multi-objective interventions. All of our code is public: https://github.com/hartvigsen-group/composable-interventions.
CoLoR-Filter: Conditional Loss Reduction Filtering for Targeted Language Model Pre-training
Jun 15, 2024Selecting high-quality data for pre-training is crucial in shaping the downstream task performance of language models. A major challenge lies in identifying this optimal subset, a problem generally considered intractable, thus necessitating scalable and effective heuristics. In this work, we propose a data selection method, CoLoR-Filter (Conditional Loss Reduction Filtering), which leverages an empirical Bayes-inspired approach to derive a simple and computationally efficient selection criterion based on the relative loss values of two auxiliary models. In addition to the modeling rationale, we evaluate CoLoR-Filter empirically on two language modeling tasks: (1) selecting data from C4 for domain adaptation to evaluation on Books and (2) selecting data from C4 for a suite of downstream multiple-choice question answering tasks. We demonstrate favorable scaling both as we subselect more aggressively and using small auxiliary models to select data for large target models. As one headline result, CoLoR-Filter data selected using a pair of 150m parameter auxiliary models can train a 1.2b parameter target model to match a 1.2b parameter model trained on 25b randomly selected tokens with 25x less data for Books and 11x less data for the downstream tasks. Code: https://github.com/davidbrandfonbrener/color-filter-olmo Filtered data: https://huggingface.co/datasets/davidbrandfonbrener/color-filtered-c4
Empowering Biomedical Discovery with AI Agents
Apr 03, 2024



We envision 'AI scientists' as systems capable of skeptical learning and reasoning that empower biomedical research through collaborative agents that integrate machine learning tools with experimental platforms. Rather than taking humans out of the discovery process, biomedical AI agents combine human creativity and expertise with AI's ability to analyze large datasets, navigate hypothesis spaces, and execute repetitive tasks. AI agents are proficient in a variety of tasks, including self-assessment and planning of discovery workflows. These agents use large language models and generative models to feature structured memory for continual learning and use machine learning tools to incorporate scientific knowledge, biological principles, and theories. AI agents can impact areas ranging from hybrid cell simulation, programmable control of phenotypes, and the design of cellular circuits to the development of new therapies.
Unleashing the Power of Meta-tuning for Few-shot Generalization Through Sparse Interpolated Experts
Mar 13, 2024Conventional wisdom suggests parameter-efficient fine-tuning of foundation models as the state-of-the-art method for transfer learning in vision, replacing the rich literature of alternatives such as meta-learning. In trying to harness the best of both worlds, meta-tuning introduces a subsequent optimization stage of foundation models but has so far only shown limited success and crucially tends to underperform on out-of-domain (OOD) tasks. In this paper, we introduce Sparse MetA-Tuning (SMAT), a method inspired by sparse mixture-of-experts approaches and trained to isolate subsets of pre-trained parameters automatically for meta-tuning on each task. SMAT successfully overcomes OOD sensitivity and delivers on the promise of enhancing the transfer abilities of vision foundation models beyond parameter-efficient finetuning. We establish new state-of-the-art results on a challenging combination of Meta-Dataset augmented with additional OOD tasks in both zero-shot and gradient-based adaptation settings. In addition, we provide a thorough analysis of the superiority of learned over hand-designed sparsity patterns for sparse expert methods and the pivotal importance of the sparsity level in balancing between in-domain and out-of-domain generalization. Our code is publicly available.
Online Adaptation of Language Models with a Memory of Amortized Contexts
Mar 07, 2024Due to the rapid generation and dissemination of information, large language models (LLMs) quickly run out of date despite enormous development costs. Due to this crucial need to keep models updated, online learning has emerged as a critical necessity when utilizing LLMs for real-world applications. However, given the ever-expanding corpus of unseen documents and the large parameter space of modern LLMs, efficient adaptation is essential. To address these challenges, we propose Memory of Amortized Contexts (MAC), an efficient and effective online adaptation framework for LLMs with strong knowledge retention. We propose an amortized feature extraction and memory-augmentation approach to compress and extract information from new documents into compact modulations stored in a memory bank. When answering questions, our model attends to and extracts relevant knowledge from this memory bank. To learn informative modulations in an efficient manner, we utilize amortization-based meta-learning, which substitutes the optimization process with a single forward pass of the encoder. Subsequently, we learn to choose from and aggregate selected documents into a single modulation by conditioning on the question, allowing us to adapt a frozen language model during test time without requiring further gradient updates. Our experiment demonstrates the superiority of MAC in multiple aspects, including online adaptation performance, time, and memory efficiency. Code is available at: https://github.com/jihoontack/MAC.