 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting 3D structure by latent posterior sampling
May 11, 2026The remarkable achievements of both generative models of 2D images and neural field representations for 3D scenes present a compelling opportunity to integrate the strengths of both approaches. In this work, we propose a methodology that combines a NeRF-based representation of 3D scenes with probabilistic modeling and reasoning using diffusion models. We view 3D reconstruction as a perception problem with inherent uncertainty that can thereby benefit from probabilistic inference methods. The core idea is to represent the 3D scene as a stochastic latent variable for which we can learn a prior and use it to perform posterior inference given a set of observations. We formulate posterior sampling using the score-based inference method of diffusion models in conjunction with a likelihood term computed from a reconstruction model that includes volumetric rendering. We train the model using a two-stage process: first we train the reconstruction model while auto-decoding the latent representations for a dataset of 3D scenes, and then we train the prior over the latents using a diffusion model. By using the model to generate samples from the posterior we demonstrate that various 3D reconstruction tasks can be performed, differing by the type of observation used as inputs. We showcase reconstruction from single-view, multi-view, noisy images, sparse pixels, and sparse depth data. These observations vary in the amount of information they provide for the scene and we show that our method can model the varying levels of inherent uncertainty associated with each task. Our experiments illustrate that this approach yields a comprehensive method capable of accurately predicting 3D structure from diverse types of observations.
BRICKS: Compositional Neural Markov Kernels for Zero-Shot Radiation-Matter Simulation
May 07, 2026We introduce a new strategy for compositional neural surrogates for radiation-matter interactions, a key task spanning domains from particle physics through nuclear and space engineering to medical physics. Exploiting the locality and the Markov nature of particle interactions, we create a \emph{next-particle prediction} kernel using hybrid discrete-continuous transformer models based on Riemannian Flow Matching on product manifolds. The model generates variable-sized typed sets of particles and radiation side effects that are the result of the interaction of an incident particle with a material volume. The resulting kernel can be composed to simulate unseen large-scale material distributions in a zero-shot manner. Unlike mechanistic simulators, our model is designed to be differentiable, provides tractable likelihoods for future downstream applications. A significant computational speed-up on GPU compared to CPU-bound mechanistic simulation is observed for single-kernel execution. We evaluate the model at the kernel level and demonstrate predictive stability over multi-round autoregressive rollouts. We additionally release a novel 20M-event radiation-matter interaction dataset for further research.
Looking Into the Water by Unsupervised Learning of the Surface Shape
Mar 08, 2026We address the problem of looking into the water from the air, where we seek to remove image distortions caused by refractions at the water surface. Our approach is based on modeling the different water surface structures at various points in time, assuming the underlying image is constant. To this end, we propose a model that consists of two neural-field networks. The first network predicts the height of the water surface at each spatial position and time, and the second network predicts the image color at each position. Using both networks, we reconstruct the observed sequence of images and can therefore use unsupervised training. We show that using implicit neural representations with periodic activation functions (SIREN) leads to effective modeling of the surface height spatio-temporal signal and its derivative, as required for image reconstruction. Using both simulated and real data we show that our method outperforms the latest unsupervised image restoration approach. In addition, it provides an estimate of the water surface.
Flow Matching Neural Processes
Dec 29, 2025Neural processes (NPs) are a class of models that learn stochastic processes directly from data and can be used for inference, sampling and conditional sampling. We introduce a new NP model based on flow matching, a generative modeling paradigm that has demonstrated strong performance on various data modalities. Following the NP training framework, the model provides amortized predictions of conditional distributions over any arbitrary points in the data. Compared to previous NP models, our model is simple to implement and can be used to sample from conditional distributions using an ODE solver, without requiring auxiliary conditioning methods. In addition, the model provides a controllable tradeoff between accuracy and running time via the number of steps in the ODE solver. We show that our model outperforms previous state-of-the-art neural process methods on various benchmarks including synthetic 1D Gaussian processes data, 2D images, and real-world weather data.
Robust Neural Processes for Noisy Data
Nov 03, 2024Models that adapt their predictions based on some given contexts, also known as in-context learning, have become ubiquitous in recent years. We propose to study the behavior of such models when data is contaminated by noise. Towards this goal we use the Neural Processes (NP) framework, as a simple and rigorous way to learn a distribution over functions, where predictions are based on a set of context points. Using this framework, we find that the models that perform best on clean data, are different than the models that perform best on noisy data. Specifically, models that process the context using attention, are more severely affected by noise, leading to in-context overfitting. We propose a simple method to train NP models that makes them more robust to noisy data. Experiments on 1D functions and 2D image datasets demonstrate that our method leads to models that outperform all other NP models for all noise levels.
Osmosis: RGBD Diffusion Prior for Underwater Image Restoration
Mar 21, 2024



Underwater image restoration is a challenging task because of strong water effects that increase dramatically with distance. This is worsened by lack of ground truth data of clean scenes without water. Diffusion priors have emerged as strong image restoration priors. However, they are often trained with a dataset of the desired restored output, which is not available in our case. To overcome this critical issue, we show how to leverage in-air images to train diffusion priors for underwater restoration. We also observe that only color data is insufficient, and augment the prior with a depth channel. We train an unconditional diffusion model prior on the joint space of color and depth, using standard RGBD datasets of natural outdoor scenes in air. Using this prior together with a novel guidance method based on the underwater image formation model, we generate posterior samples of clean images, removing the water effects. Even though our prior did not see any underwater images during training, our method outperforms state-of-the-art baselines for image restoration on very challenging scenes. Data, models and code are published in the project page.
SeaThru-NeRF: Neural Radiance Fields in Scattering Media
Apr 16, 2023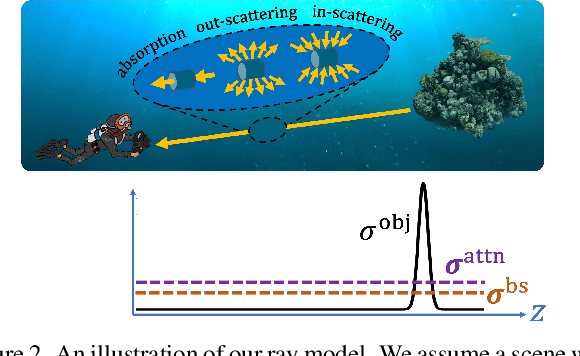

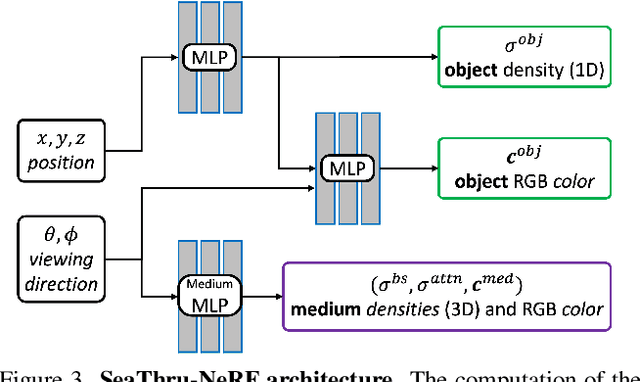

Research on neural radiance fields (NeRFs) for novel view generation is exploding with new models and extensions. However, a question that remains unanswered is what happens in underwater or foggy scenes where the medium strongly influences the appearance of objects. Thus far, NeRF and its variants have ignored these cases. However, since the NeRF framework is based on volumetric rendering, it has inherent capability to account for the medium's effects, once modeled appropriately. We develop a new rendering model for NeRFs in scattering media, which is based on the SeaThru image formation model, and suggest a suitable architecture for learning both scene information and medium parameters. We demonstrate the strength of our method using simulated and real-world scenes, correctly rendering novel photorealistic views underwater. Even more excitingly, we can render clear views of these scenes, removing the medium between the camera and the scene and reconstructing the appearance and depth of far objects, which are severely occluded by the medium. Our code and unique datasets are available on the project's website.
Spatial Functa: Scaling Functa to ImageNet Classification and Generation
Feb 09, 2023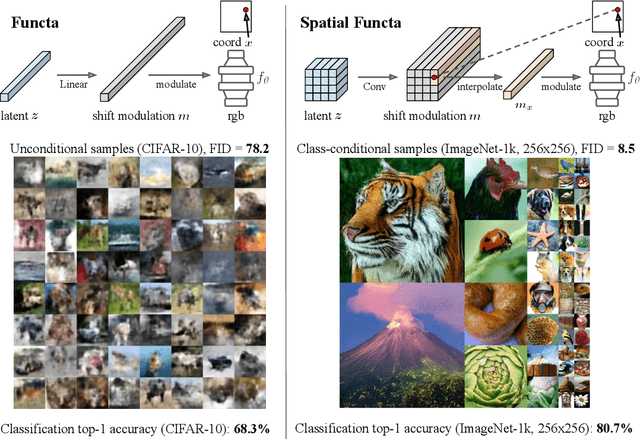
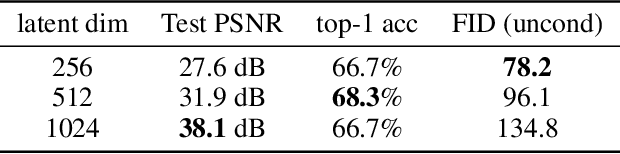


Neural fields, also known as implicit neural representations, have emerged as a powerful means to represent complex signals of various modalities. Based on this Dupont et al. (2022) introduce a framework that views neural fields as data, termed *functa*, and proposes to do deep learning directly on this dataset of neural fields. In this work, we show that the proposed framework faces limitations when scaling up to even moderately complex datasets such as CIFAR-10. We then propose *spatial functa*, which overcome these limitations by using spatially arranged latent representations of neural fields, thereby allowing us to scale up the approach to ImageNet-1k at 256x256 resolution. We demonstrate competitive performance to Vision Transformers (Steiner et al., 2022) on classification and Latent Diffusion (Rombach et al., 2022) on image generation respectively.
From data to functa: Your data point is a function and you should treat it like one
Jan 28, 2022



It is common practice in deep learning to represent a measurement of the world on a discrete grid, e.g. a 2D grid of pixels. However, the underlying signal represented by these measurements is often continuous, e.g. the scene depicted in an image. A powerful continuous alternative is then to represent these measurements using an implicit neural representation, a neural function trained to output the appropriate measurement value for any input spatial location. In this paper, we take this idea to its next level: what would it take to perform deep learning on these functions instead, treating them as data? In this context we refer to the data as functa, and propose a framework for deep learning on functa. This view presents a number of challenges around efficient conversion from data to functa, compact representation of functa, and effectively solving downstream tasks on functa. We outline a recipe to overcome these challenges and apply it to a wide range of data modalities including images, 3D shapes, neural radiance fields (NeRF) and data on manifolds. We demonstrate that this approach has various compelling properties across data modalities, in particular on the canonical tasks of generative modeling, data imputation, novel view synthesis and classification.
Inferring a Continuous Distribution of Atom Coordinates from Cryo-EM Images using VAEs
Jun 26, 2021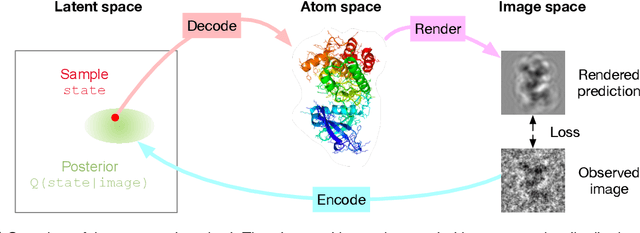
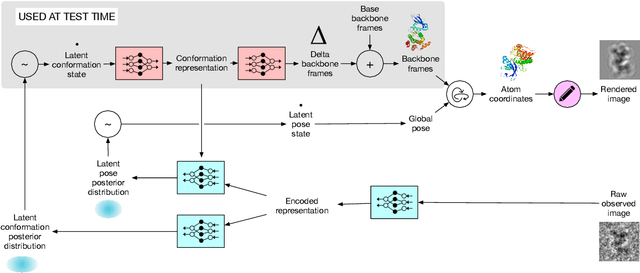
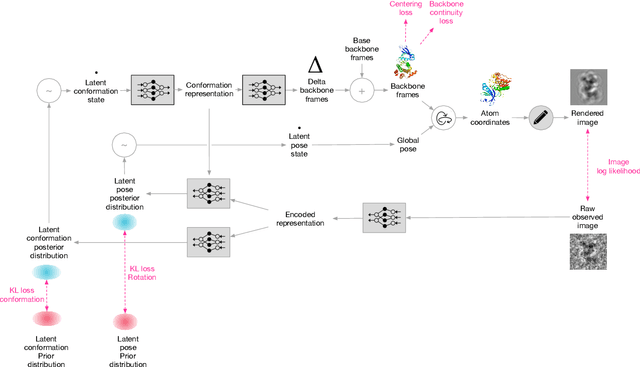
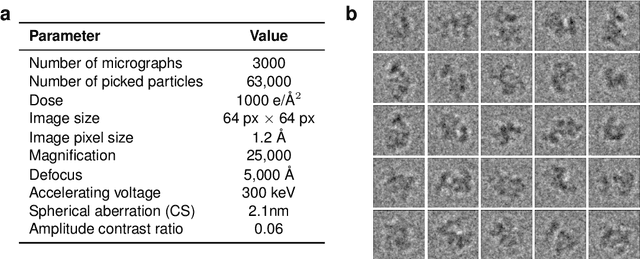
Cryo-electron microscopy (cryo-EM) has revolutionized experimental protein structure determination. Despite advances in high resolution reconstruction, a majority of cryo-EM experiments provide either a single state of the studied macromolecule, or a relatively small number of its conformations. This reduces the effectiveness of the technique for proteins with flexible regions, which are known to play a key role in protein function. Recent methods for capturing conformational heterogeneity in cryo-EM data model it in volume space, making recovery of continuous atomic structures challenging. Here we present a fully deep-learning-based approach using variational auto-encoders (VAEs) to recover a continuous distribution of atomic protein structures and poses directly from picked particle images and demonstrate its efficacy on realistic simulated data. We hope that methods built on this work will allow incorporation of stronger prior information about protein structure and enable better understanding of non-rigid protein structures.