 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetacognitive Capabilities of LLMs: An Exploration in Mathematical Problem Solving
May 20, 2024



Metacognitive knowledge refers to humans' intuitive knowledge of their own thinking and reasoning processes. Today's best LLMs clearly possess some reasoning processes. The paper gives evidence that they also have metacognitive knowledge, including ability to name skills and procedures to apply given a task. We explore this primarily in context of math reasoning, developing a prompt-guided interaction procedure to get a powerful LLM to assign sensible skill labels to math questions, followed by having it perform semantic clustering to obtain coarser families of skill labels. These coarse skill labels look interpretable to humans. To validate that these skill labels are meaningful and relevant to the LLM's reasoning processes we perform the following experiments. (a) We ask GPT-4 to assign skill labels to training questions in math datasets GSM8K and MATH. (b) When using an LLM to solve the test questions, we present it with the full list of skill labels and ask it to identify the skill needed. Then it is presented with randomly selected exemplar solved questions associated with that skill label. This improves accuracy on GSM8k and MATH for several strong LLMs, including code-assisted models. The methodology presented is domain-agnostic, even though this article applies it to math problems.
DiscoGen: Learning to Discover Gene Regulatory Networks
Apr 12, 2023Accurately inferring Gene Regulatory Networks (GRNs) is a critical and challenging task in biology. GRNs model the activatory and inhibitory interactions between genes and are inherently causal in nature. To accurately identify GRNs, perturbational data is required. However, most GRN discovery methods only operate on observational data. Recent advances in neural network-based causal discovery methods have significantly improved causal discovery, including handling interventional data, improvements in performance and scalability. However, applying state-of-the-art (SOTA) causal discovery methods in biology poses challenges, such as noisy data and a large number of samples. Thus, adapting the causal discovery methods is necessary to handle these challenges. In this paper, we introduce DiscoGen, a neural network-based GRN discovery method that can denoise gene expression measurements and handle interventional data. We demonstrate that our model outperforms SOTA neural network-based causal discovery methods.
Symmetry-Based Representations for Artificial and Biological General Intelligence
Mar 17, 2022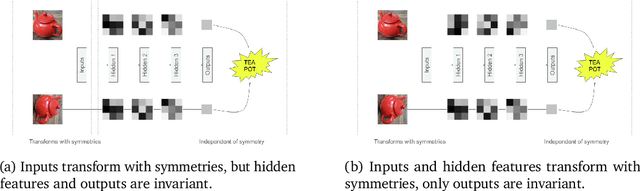
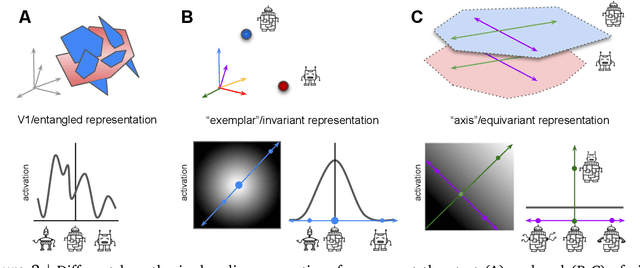
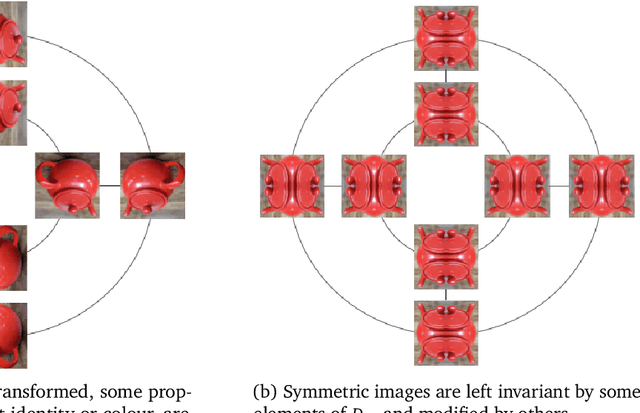
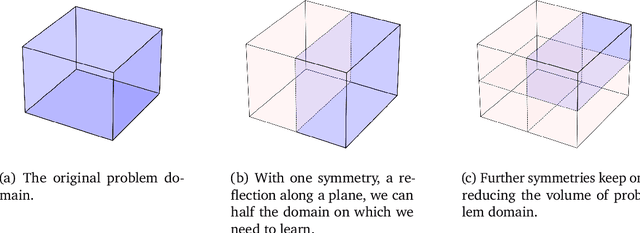
Biological intelligence is remarkable in its ability to produce complex behaviour in many diverse situations through data efficient, generalisable and transferable skill acquisition. It is believed that learning "good" sensory representations is important for enabling this, however there is little agreement as to what a good representation should look like. In this review article we are going to argue that symmetry transformations are a fundamental principle that can guide our search for what makes a good representation. The idea that there exist transformations (symmetries) that affect some aspects of the system but not others, and their relationship to conserved quantities has become central in modern physics, resulting in a more unified theoretical framework and even ability to predict the existence of new particles. Recently, symmetries have started to gain prominence in machine learning too, resulting in more data efficient and generalisable algorithms that can mimic some of the complex behaviours produced by biological intelligence. Finally, first demonstrations of the importance of symmetry transformations for representation learning in the brain are starting to arise in neuroscience. Taken together, the overwhelming positive effect that symmetries bring to these disciplines suggest that they may be an important general framework that determines the structure of the universe, constrains the nature of natural tasks and consequently shapes both biological and artificial intelligence.
From data to functa: Your data point is a function and you should treat it like one
Jan 28, 2022



It is common practice in deep learning to represent a measurement of the world on a discrete grid, e.g. a 2D grid of pixels. However, the underlying signal represented by these measurements is often continuous, e.g. the scene depicted in an image. A powerful continuous alternative is then to represent these measurements using an implicit neural representation, a neural function trained to output the appropriate measurement value for any input spatial location. In this paper, we take this idea to its next level: what would it take to perform deep learning on these functions instead, treating them as data? In this context we refer to the data as functa, and propose a framework for deep learning on functa. This view presents a number of challenges around efficient conversion from data to functa, compact representation of functa, and effectively solving downstream tasks on functa. We outline a recipe to overcome these challenges and apply it to a wide range of data modalities including images, 3D shapes, neural radiance fields (NeRF) and data on manifolds. We demonstrate that this approach has various compelling properties across data modalities, in particular on the canonical tasks of generative modeling, data imputation, novel view synthesis and classification.
Systematic Evaluation of Causal Discovery in Visual Model Based Reinforcement Learning
Jul 02, 2021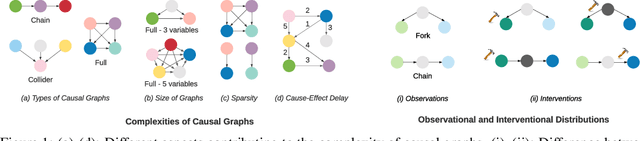
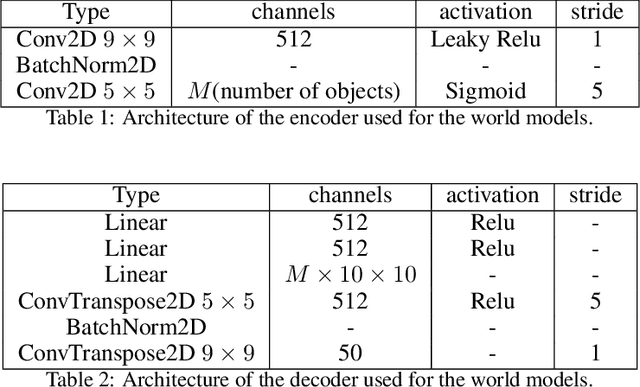
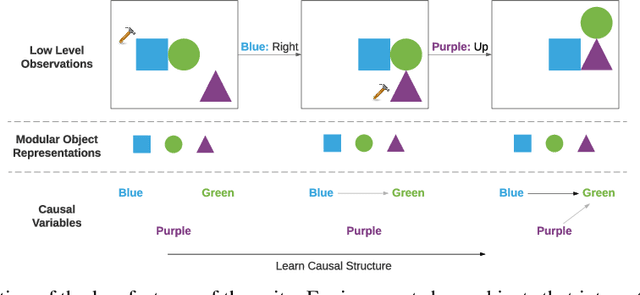
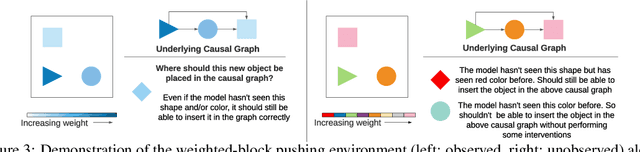
Inducing causal relationships from observations is a classic problem in machine learning. Most work in causality starts from the premise that the causal variables themselves are observed. However, for AI agents such as robots trying to make sense of their environment, the only observables are low-level variables like pixels in images. To generalize well, an agent must induce high-level variables, particularly those which are causal or are affected by causal variables. A central goal for AI and causality is thus the joint discovery of abstract representations and causal structure. However, we note that existing environments for studying causal induction are poorly suited for this objective because they have complicated task-specific causal graphs which are impossible to manipulate parametrically (e.g., number of nodes, sparsity, causal chain length, etc.). In this work, our goal is to facilitate research in learning representations of high-level variables as well as causal structures among them. In order to systematically probe the ability of methods to identify these variables and structures, we design a suite of benchmarking RL environments. We evaluate various representation learning algorithms from the literature and find that explicitly incorporating structure and modularity in models can help causal induction in model-based reinforcement learning.
Integrable Nonparametric Flows
Dec 03, 2020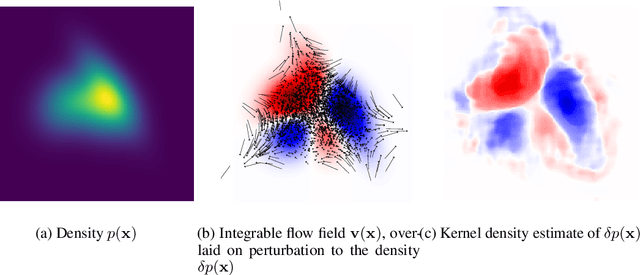
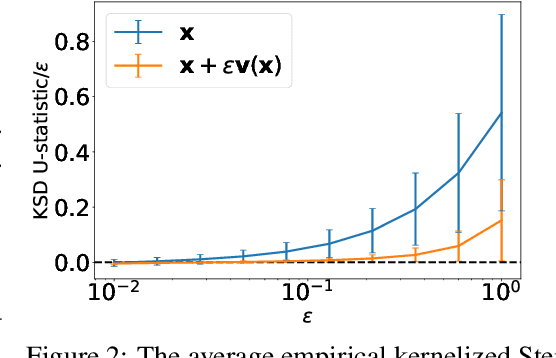
We introduce a method for reconstructing an infinitesimal normalizing flow given only an infinitesimal change to a (possibly unnormalized) probability distribution. This reverses the conventional task of normalizing flows -- rather than being given samples from a unknown target distribution and learning a flow that approximates the distribution, we are given a perturbation to an initial distribution and aim to reconstruct a flow that would generate samples from the known perturbed distribution. While this is an underdetermined problem, we find that choosing the flow to be an integrable vector field yields a solution closely related to electrostatics, and a solution can be computed by the method of Green's functions. Unlike conventional normalizing flows, this flow can be represented in an entirely nonparametric manner. We validate this derivation on low-dimensional problems, and discuss potential applications to problems in quantum Monte Carlo and machine learning.
Towards a Definition of Disentangled Representations
Dec 05, 2018
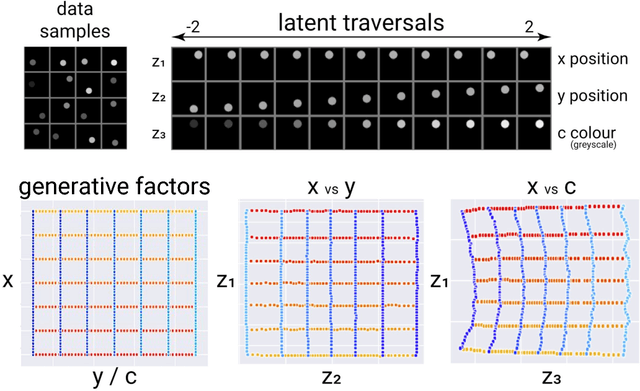
How can intelligent agents solve a diverse set of tasks in a data-efficient manner? The disentangled representation learning approach posits that such an agent would benefit from separating out (disentangling) the underlying structure of the world into disjoint parts of its representation. However, there is no generally agreed-upon definition of disentangling, not least because it is unclear how to formalise the notion of world structure beyond toy datasets with a known ground truth generative process. Here we propose that a principled solution to characterising disentangled representations can be found by focusing on the transformation properties of the world. In particular, we suggest that those transformations that change only some properties of the underlying world state, while leaving all other properties invariant, are what gives exploitable structure to any kind of data. Similar ideas have already been successfully applied in physics, where the study of symmetry transformations has revolutionised the understanding of the world structure. By connecting symmetry transformations to vector representations using the formalism of group and representation theory we arrive at the first formal definition of disentangled representations. Our new definition is in agreement with many of the current intuitions about disentangling, while also providing principled resolutions to a number of previous points of contention. While this work focuses on formally defining disentangling - as opposed to solving the learning problem - we believe that the shift in perspective to studying data transformations can stimulate the development of better representation learning algorithms.
Unsupervised Predictive Memory in a Goal-Directed Agent
Mar 28, 2018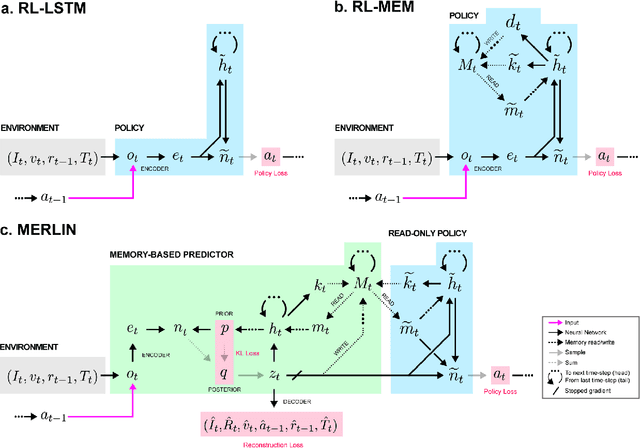
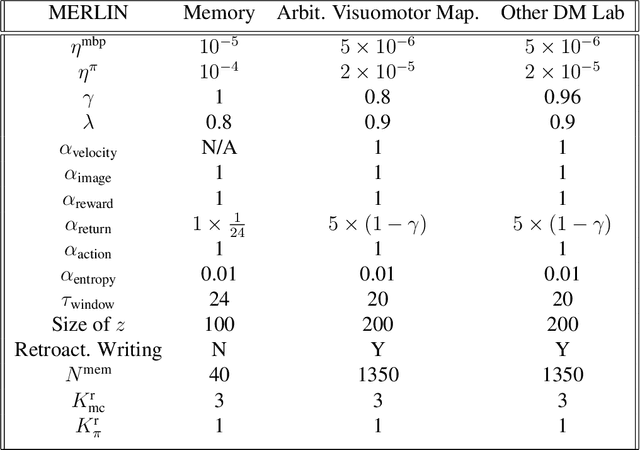
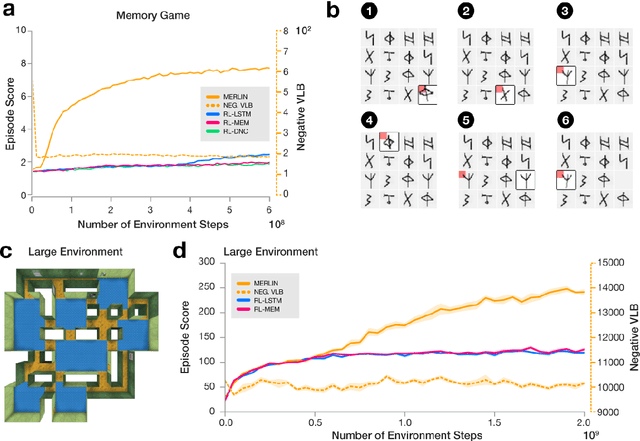

Animals execute goal-directed behaviours despite the limited range and scope of their sensors. To cope, they explore environments and store memories maintaining estimates of important information that is not presently available. Recently, progress has been made with artificial intelligence (AI) agents that learn to perform tasks from sensory input, even at a human level, by merging reinforcement learning (RL) algorithms with deep neural networks, and the excitement surrounding these results has led to the pursuit of related ideas as explanations of non-human animal learning. However, we demonstrate that contemporary RL algorithms struggle to solve simple tasks when enough information is concealed from the sensors of the agent, a property called "partial observability". An obvious requirement for handling partially observed tasks is access to extensive memory, but we show memory is not enough; it is critical that the right information be stored in the right format. We develop a model, the Memory, RL, and Inference Network (MERLIN), in which memory formation is guided by a process of predictive modeling. MERLIN facilitates the solution of tasks in 3D virtual reality environments for which partial observability is severe and memories must be maintained over long durations. Our model demonstrates a single learning agent architecture that can solve canonical behavioural tasks in psychology and neurobiology without strong simplifying assumptions about the dimensionality of sensory input or the duration of experiences.
Few-shot Autoregressive Density Estimation: Towards Learning to Learn Distributions
Feb 28, 2018
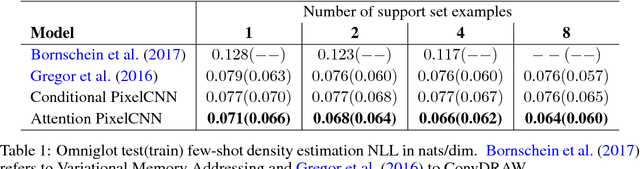

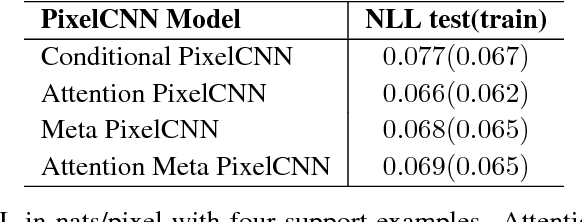
Deep autoregressive models have shown state-of-the-art performance in density estimation for natural images on large-scale datasets such as ImageNet. However, such models require many thousands of gradient-based weight updates and unique image examples for training. Ideally, the models would rapidly learn visual concepts from only a handful of examples, similar to the manner in which humans learns across many vision tasks. In this paper, we show how 1) neural attention and 2) meta learning techniques can be used in combination with autoregressive models to enable effective few-shot density estimation. Our proposed modifications to PixelCNN result in state-of-the art few-shot density estimation on the Omniglot dataset. Furthermore, we visualize the learned attention policy and find that it learns intuitive algorithms for simple tasks such as image mirroring on ImageNet and handwriting on Omniglot without supervision. Finally, we extend the model to natural images and demonstrate few-shot image generation on the Stanford Online Products dataset.
Learning and Querying Fast Generative Models for Reinforcement Learning
Feb 08, 2018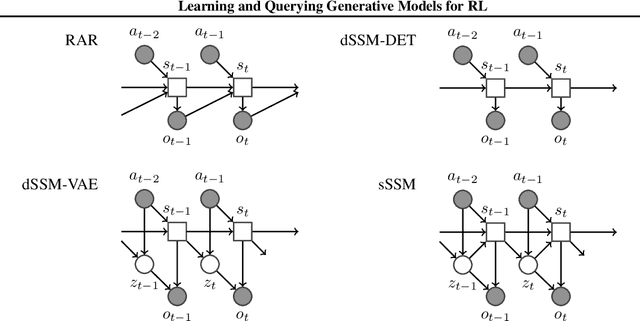

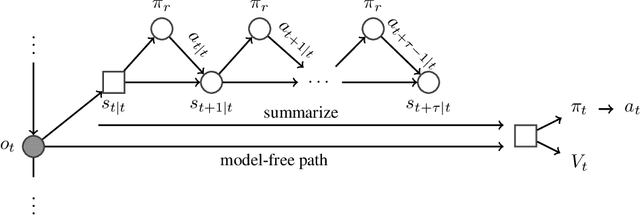
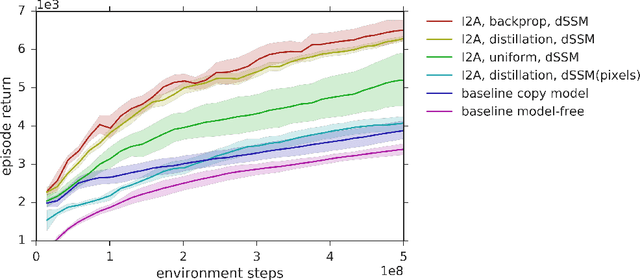
A key challenge in model-based reinforcement learning (RL) is to synthesize computationally efficient and accurate environment models. We show that carefully designed generative models that learn and operate on compact state representations, so-called state-space models, substantially reduce the computational costs for predicting outcomes of sequences of actions. Extensive experiments establish that state-space models accurately capture the dynamics of Atari games from the Arcade Learning Environment from raw pixels. The computational speed-up of state-space models while maintaining high accuracy makes their application in RL feasible: We demonstrate that agents which query these models for decision making outperform strong model-free baselines on the game MSPACMAN, demonstrating the potential of using learned environment models for planning.