 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Scaling Laws for Routed Language Models
Feb 09, 2022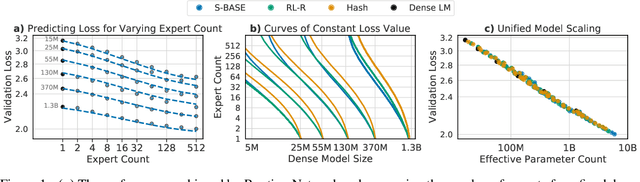

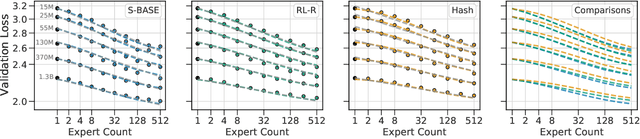
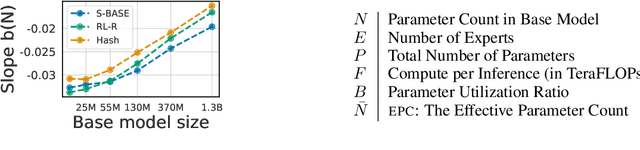
The performance of a language model has been shown to be effectively modeled as a power-law in its parameter count. Here we study the scaling behaviors of Routing Networks: architectures that conditionally use only a subset of their parameters while processing an input. For these models, parameter count and computational requirement form two independent axes along which an increase leads to better performance. In this work we derive and justify scaling laws defined on these two variables which generalize those known for standard language models and describe the performance of a wide range of routing architectures trained via three different techniques. Afterwards we provide two applications of these laws: first deriving an Effective Parameter Count along which all models scale at the same rate, and then using the scaling coefficients to give a quantitative comparison of the three routing techniques considered. Our analysis derives from an extensive evaluation of Routing Networks across five orders of magnitude of size, including models with hundreds of experts and hundreds of billions of parameters.
Reducing Sentiment Bias in Language Models via Counterfactual Evaluation
Nov 08, 2019

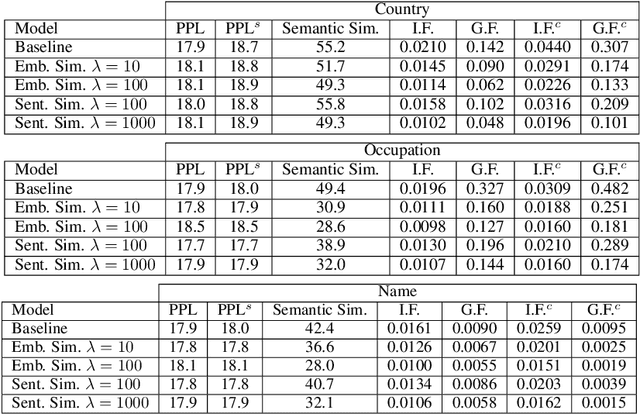
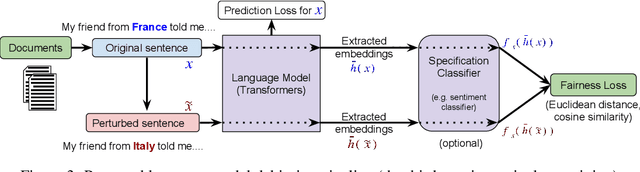
Recent improvements in large-scale language models have driven progress on automatic generation of syntactically and semantically consistent text for many real-world applications. Many of these advances leverage the availability of large corpora. While training on such corpora encourages the model to understand long-range dependencies in text, it can also result in the models internalizing the social biases present in the corpora. This paper aims to quantify and reduce biases exhibited by language models. Given a conditioning context (e.g. a writing prompt) and a language model, we analyze if (and how) the sentiment of the generated text is affected by changes in values of sensitive attributes (e.g. country names, occupations, genders, etc.) in the conditioning context, a.k.a. counterfactual evaluation. We quantify these biases by adapting individual and group fairness metrics from the fair machine learning literature. Extensive evaluation on two different corpora (news articles and Wikipedia) shows that state-of-the-art Transformer-based language models exhibit biases learned from data. We propose embedding-similarity and sentiment-similarity regularization methods that improve both individual and group fairness metrics without sacrificing perplexity and semantic similarity---a positive step toward development and deployment of fairer language models for real-world applications.
Training language GANs from Scratch
May 23, 2019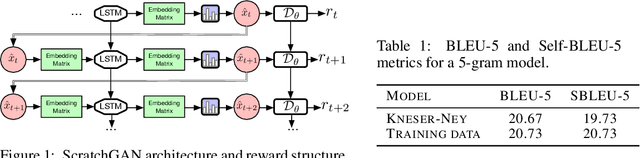
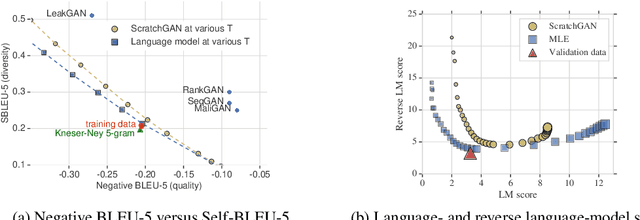

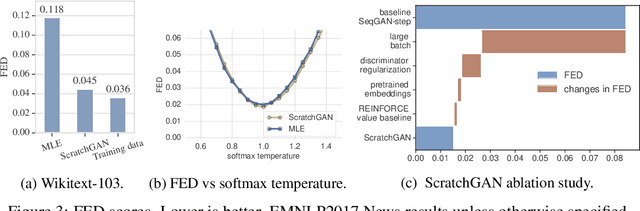
Generative Adversarial Networks (GANs) enjoy great success at image generation, but have proven difficult to train in the domain of natural language. Challenges with gradient estimation, optimization instability, and mode collapse have lead practitioners to resort to maximum likelihood pre-training, followed by small amounts of adversarial fine-tuning. The benefits of GAN fine-tuning for language generation are unclear, as the resulting models produce comparable or worse samples than traditional language models. We show it is in fact possible to train a language GAN from scratch -- without maximum likelihood pre-training. We combine existing techniques such as large batch sizes, dense rewards and discriminator regularization to stabilize and improve language GANs. The resulting model, ScratchGAN, performs comparably to maximum likelihood training on EMNLP2017 News and WikiText-103 corpora according to quality and diversity metrics.
Neural Arithmetic Logic Units
Aug 01, 2018



Neural networks can learn to represent and manipulate numerical information, but they seldom generalize well outside of the range of numerical values encountered during training. To encourage more systematic numerical extrapolation, we propose an architecture that represents numerical quantities as linear activations which are manipulated using primitive arithmetic operators, controlled by learned gates. We call this module a neural arithmetic logic unit (NALU), by analogy to the arithmetic logic unit in traditional processors. Experiments show that NALU-enhanced neural networks can learn to track time, perform arithmetic over images of numbers, translate numerical language into real-valued scalars, execute computer code, and count objects in images. In contrast to conventional architectures, we obtain substantially better generalization both inside and outside of the range of numerical values encountered during training, often extrapolating orders of magnitude beyond trained numerical ranges.
Relational recurrent neural networks
Jun 28, 2018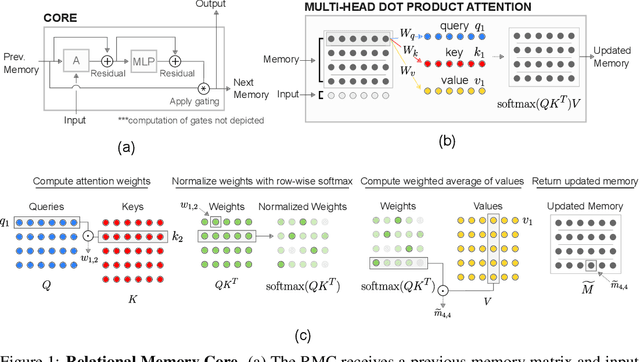
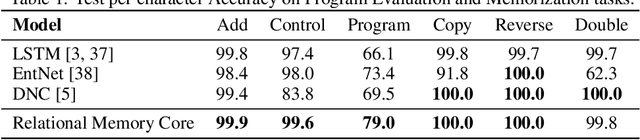
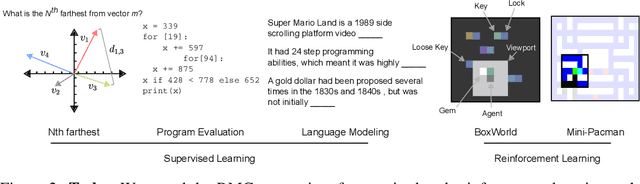
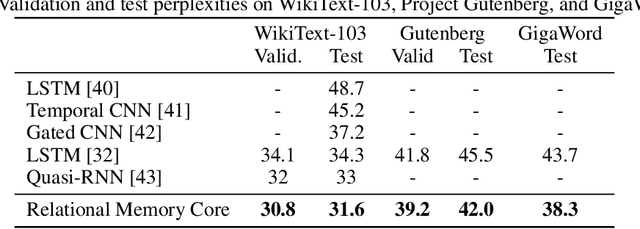
Memory-based neural networks model temporal data by leveraging an ability to remember information for long periods. It is unclear, however, whether they also have an ability to perform complex relational reasoning with the information they remember. Here, we first confirm our intuitions that standard memory architectures may struggle at tasks that heavily involve an understanding of the ways in which entities are connected -- i.e., tasks involving relational reasoning. We then improve upon these deficits by using a new memory module -- a \textit{Relational Memory Core} (RMC) -- which employs multi-head dot product attention to allow memories to interact. Finally, we test the RMC on a suite of tasks that may profit from more capable relational reasoning across sequential information, and show large gains in RL domains (e.g. Mini PacMan), program evaluation, and language modeling, achieving state-of-the-art results on the WikiText-103, Project Gutenberg, and GigaWord datasets.
Unsupervised Predictive Memory in a Goal-Directed Agent
Mar 28, 2018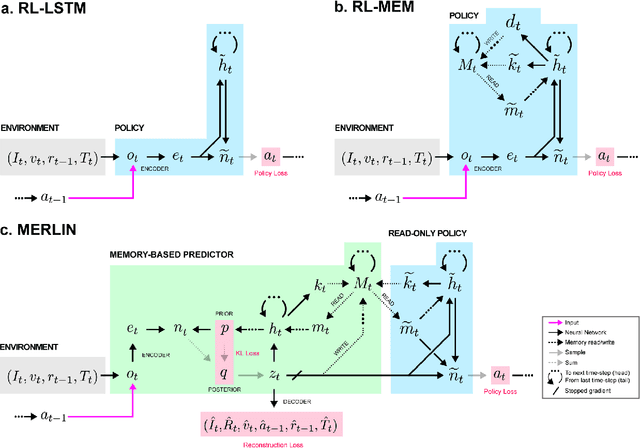
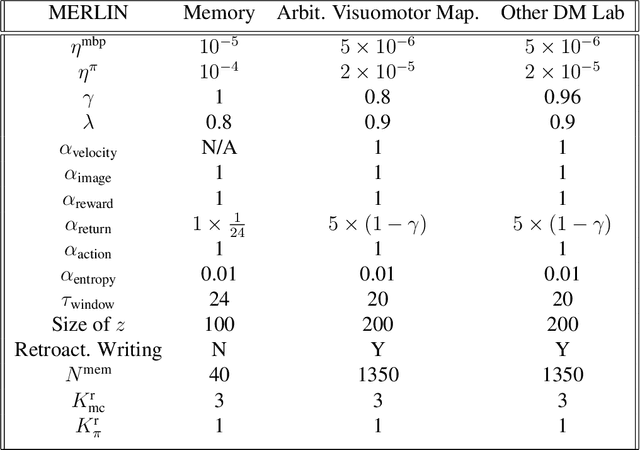
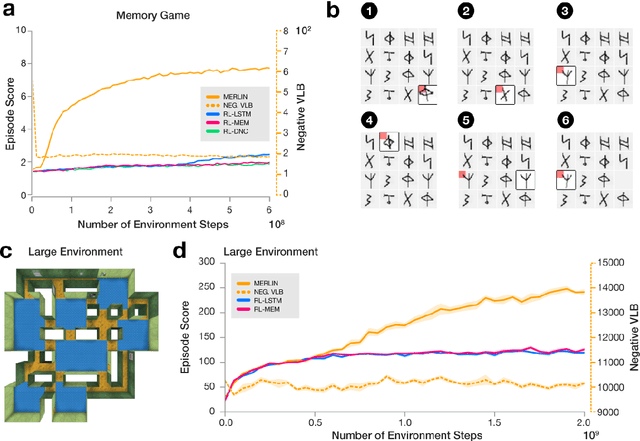

Animals execute goal-directed behaviours despite the limited range and scope of their sensors. To cope, they explore environments and store memories maintaining estimates of important information that is not presently available. Recently, progress has been made with artificial intelligence (AI) agents that learn to perform tasks from sensory input, even at a human level, by merging reinforcement learning (RL) algorithms with deep neural networks, and the excitement surrounding these results has led to the pursuit of related ideas as explanations of non-human animal learning. However, we demonstrate that contemporary RL algorithms struggle to solve simple tasks when enough information is concealed from the sensors of the agent, a property called "partial observability". An obvious requirement for handling partially observed tasks is access to extensive memory, but we show memory is not enough; it is critical that the right information be stored in the right format. We develop a model, the Memory, RL, and Inference Network (MERLIN), in which memory formation is guided by a process of predictive modeling. MERLIN facilitates the solution of tasks in 3D virtual reality environments for which partial observability is severe and memories must be maintained over long durations. Our model demonstrates a single learning agent architecture that can solve canonical behavioural tasks in psychology and neurobiology without strong simplifying assumptions about the dimensionality of sensory input or the duration of experiences.
Model-Free Episodic Control
Jun 14, 2016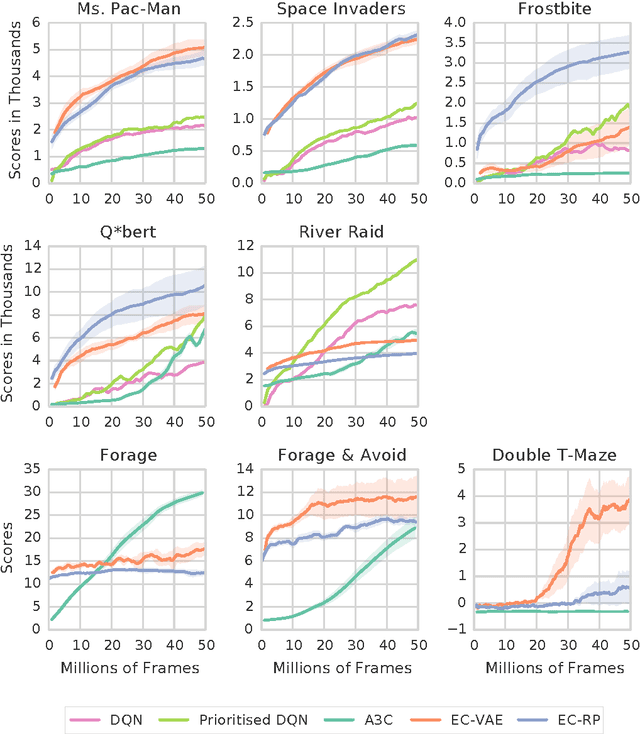

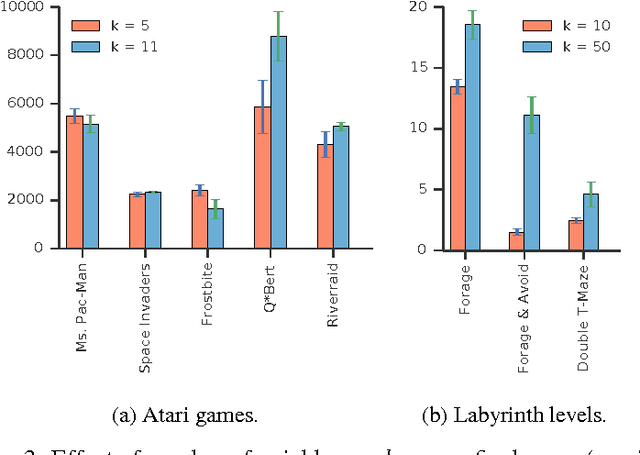
State of the art deep reinforcement learning algorithms take many millions of interactions to attain human-level performance. Humans, on the other hand, can very quickly exploit highly rewarding nuances of an environment upon first discovery. In the brain, such rapid learning is thought to depend on the hippocampus and its capacity for episodic memory. Here we investigate whether a simple model of hippocampal episodic control can learn to solve difficult sequential decision-making tasks. We demonstrate that it not only attains a highly rewarding strategy significantly faster than state-of-the-art deep reinforcement learning algorithms, but also achieves a higher overall reward on some of the more challenging domains.