 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Outliers in a Haystack: Anomaly Detection for Large Pointcloud Scenes
Aug 25, 2025LiDAR scanning in outdoor scenes acquires accurate distance measurements over wide areas, producing large-scale point clouds. Application examples for this data include robotics, automotive vehicles, and land surveillance. During such applications, outlier objects from outside the training data will inevitably appear. Our research contributes a novel approach to open-set segmentation, leveraging the learnings of object defect-detection research. We also draw on the Mamba architecture's strong performance in utilising long-range dependencies and scalability to large data. Combining both, we create a reconstruction based approach for the task of outdoor scene open-set segmentation. We show that our approach improves performance not only when applied to our our own open-set segmentation method, but also when applied to existing methods. Furthermore we contribute a Mamba based architecture which is competitive with existing voxel-convolution based methods on challenging, large-scale pointclouds.
Simultaneous Diffusion Sampling for Conditional LiDAR Generation
Oct 15, 2024

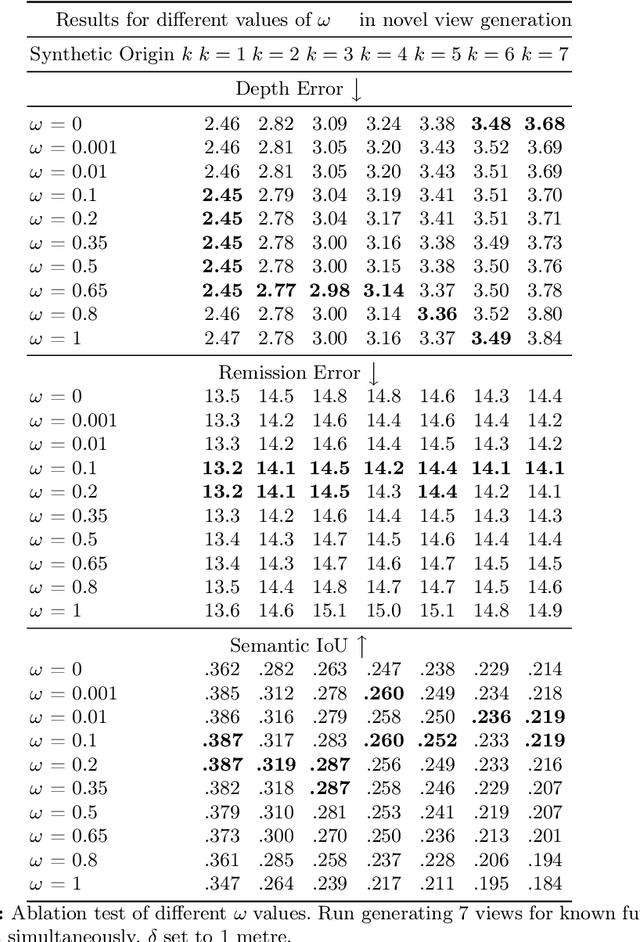
By enabling capturing of 3D point clouds that reflect the geometry of the immediate environment, LiDAR has emerged as a primary sensor for autonomous systems. If a LiDAR scan is too sparse, occluded by obstacles, or too small in range, enhancing the point cloud scan by while respecting the geometry of the scene is useful for downstream tasks. Motivated by the explosive growth of interest in generative methods in vision, conditional LiDAR generation is starting to take off. This paper proposes a novel simultaneous diffusion sampling methodology to generate point clouds conditioned on the 3D structure of the scene as seen from multiple views. The key idea is to impose multi-view geometric constraints on the generation process, exploiting mutual information for enhanced results. Our method begins by recasting the input scan to multiple new viewpoints around the scan, thus creating multiple synthetic LiDAR scans. Then, the synthetic and input LiDAR scans simultaneously undergo conditional generation according to our methodology. Results show that our method can produce accurate and geometrically consistent enhancements to point cloud scans, allowing it to outperform existing methods by a large margin in a variety of benchmarks.
Semantic Segmentation on 3D Point Clouds with High Density Variations
Jul 04, 2023



LiDAR scanning for surveying applications acquire measurements over wide areas and long distances, which produces large-scale 3D point clouds with significant local density variations. While existing 3D semantic segmentation models conduct downsampling and upsampling to build robustness against varying point densities, they are less effective under the large local density variations characteristic of point clouds from surveying applications. To alleviate this weakness, we propose a novel architecture called HDVNet that contains a nested set of encoder-decoder pathways, each handling a specific point density range. Limiting the interconnections between the feature maps enables HDVNet to gauge the reliability of each feature based on the density of a point, e.g., downweighting high density features not existing in low density objects. By effectively handling input density variations, HDVNet outperforms state-of-the-art models in segmentation accuracy on real point clouds with inconsistent density, using just over half the weights.
Solving Reasoning Tasks with a Slot Transformer
Oct 20, 2022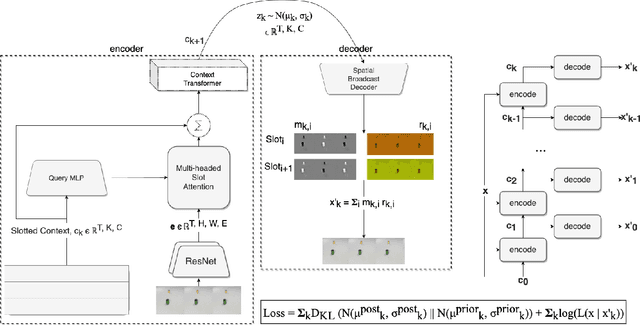
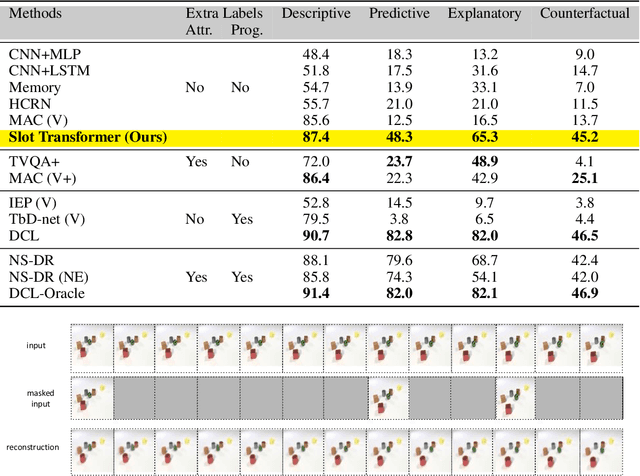
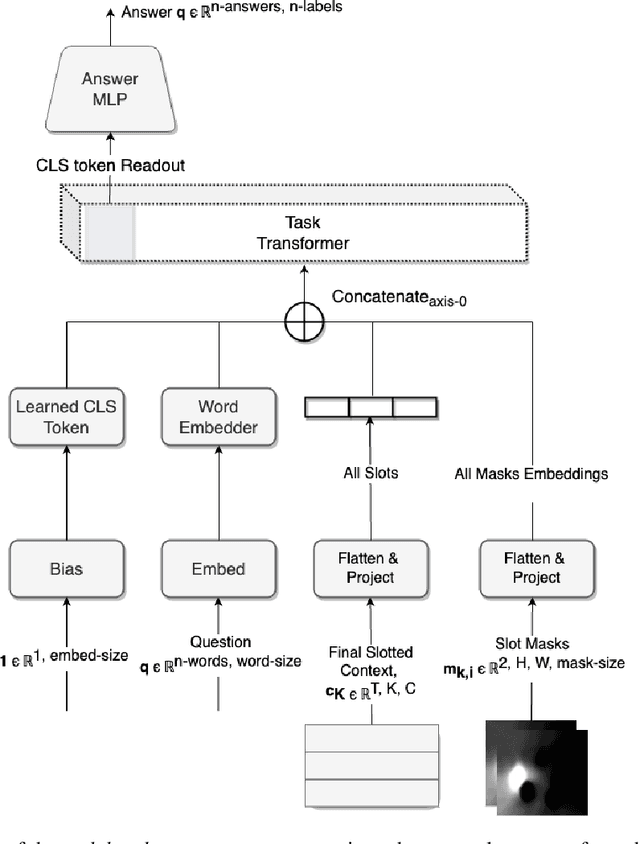
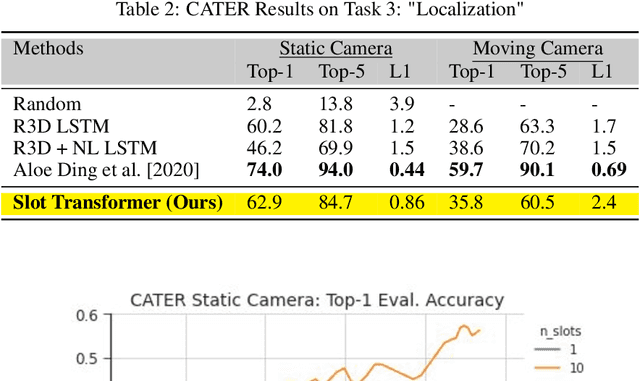
The ability to carve the world into useful abstractions in order to reason about time and space is a crucial component of intelligence. In order to successfully perceive and act effectively using senses we must parse and compress large amounts of information for further downstream reasoning to take place, allowing increasingly complex concepts to emerge. If there is any hope to scale representation learning methods to work with real world scenes and temporal dynamics then there must be a way to learn accurate, concise, and composable abstractions across time. We present the Slot Transformer, an architecture that leverages slot attention, transformers and iterative variational inference on video scene data to infer such representations. We evaluate the Slot Transformer on CLEVRER, Kinetics-600 and CATER datesets and demonstrate that the approach allows us to develop robust modeling and reasoning around complex behaviours as well as scores on these datasets that compare favourably to existing baselines. Finally we evaluate the effectiveness of key components of the architecture, the model's representational capacity and its ability to predict from incomplete input.
Rapid Task-Solving in Novel Environments
Jun 05, 2020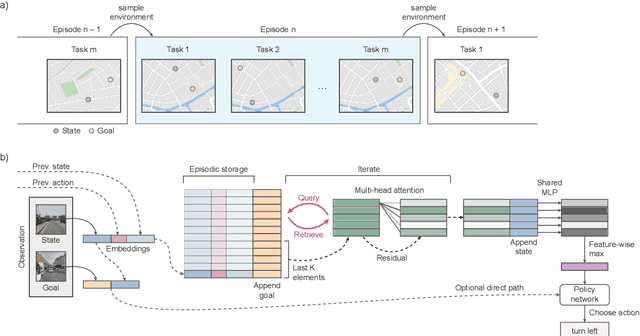

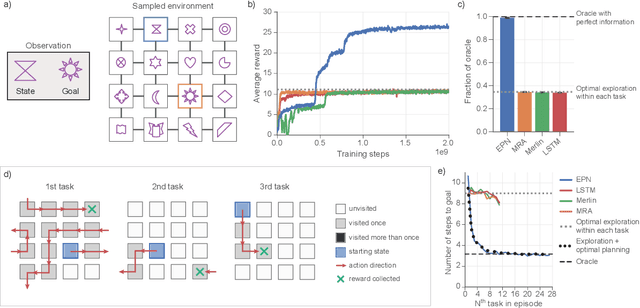
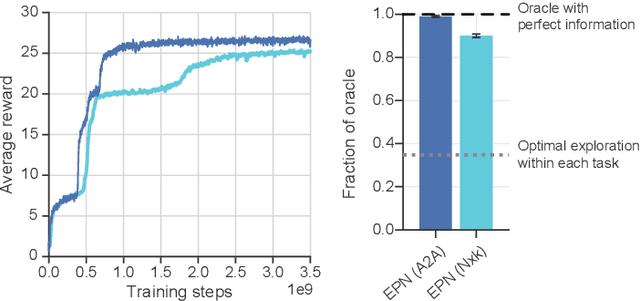
When thrust into an unfamiliar environment and charged with solving a series of tasks, an effective agent should (1) leverage prior knowledge to solve its current task while (2) efficiently exploring to gather knowledge for use in future tasks, and then (3) plan using that knowledge when faced with new tasks in that same environment. We introduce two domains for conducting research on this challenge, and find that state-of-the-art deep reinforcement learning (RL) agents fail to plan in novel environments. We develop a recursive implicit planning module that operates over episodic memories, and show that the resulting deep-RL agent is able to explore and plan in novel environments, outperforming the nearest baseline by factors of 2-3 across the two domains. We find evidence that our module (1) learned to execute a sensible information-propagating algorithm and (2) generalizes to situations beyond its training experience.
Generalization of Reinforcement Learners with Working and Episodic Memory
Oct 29, 2019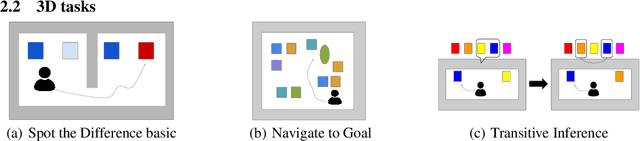
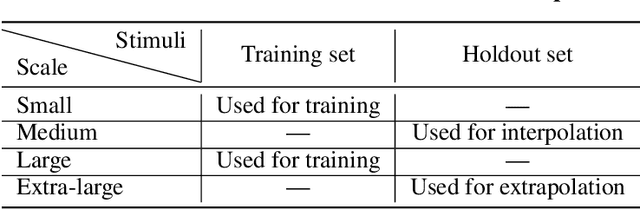
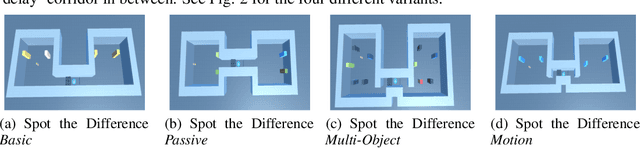
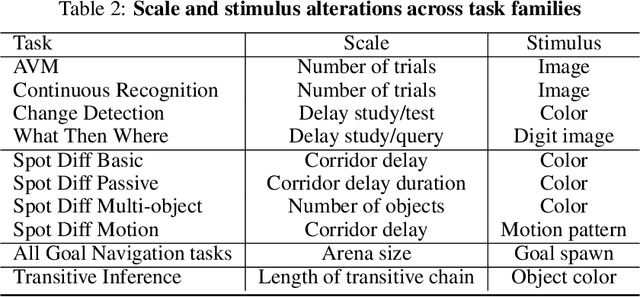
Memory is an important aspect of intelligence and plays a role in many deep reinforcement learning models. However, little progress has been made in understanding when specific memory systems help more than others and how well they generalize. The field also has yet to see a prevalent consistent and rigorous approach for evaluating agent performance on holdout data. In this paper, we aim to develop a comprehensive methodology to test different kinds of memory in an agent and assess how well the agent can apply what it learns in training to a holdout set that differs from the training set along dimensions that we suggest are relevant for evaluating memory-specific generalization. To that end, we first construct a diverse set of memory tasks that allow us to evaluate test-time generalization across multiple dimensions. Second, we develop and perform multiple ablations on an agent architecture that combines multiple memory systems, observe its baseline models, and investigate its performance against the task suite.
OpenSpiel: A Framework for Reinforcement Learning in Games
Oct 10, 2019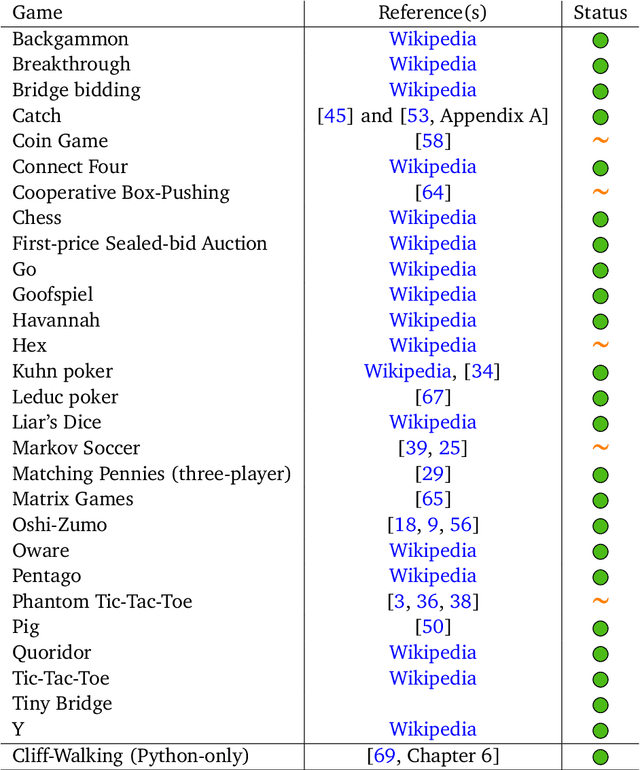
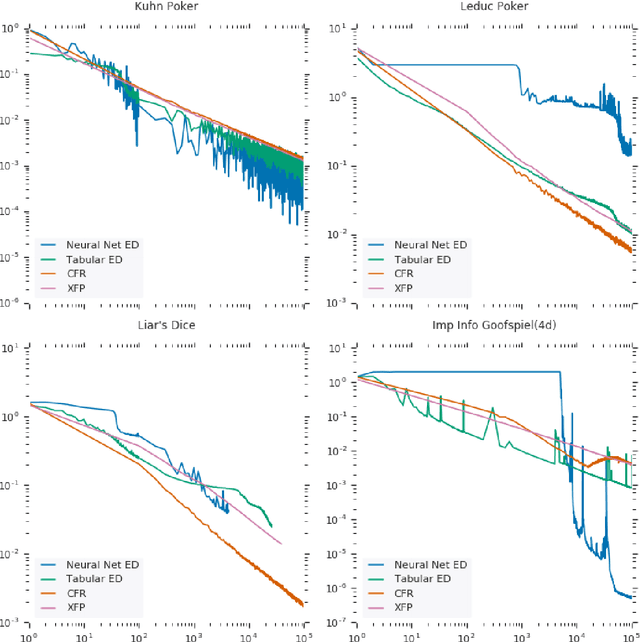
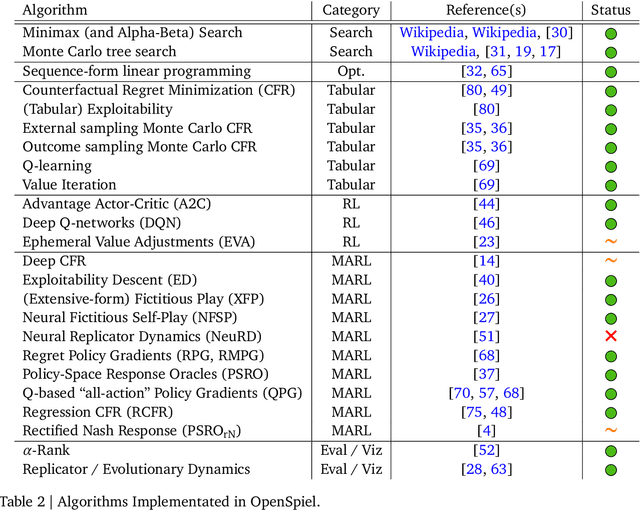
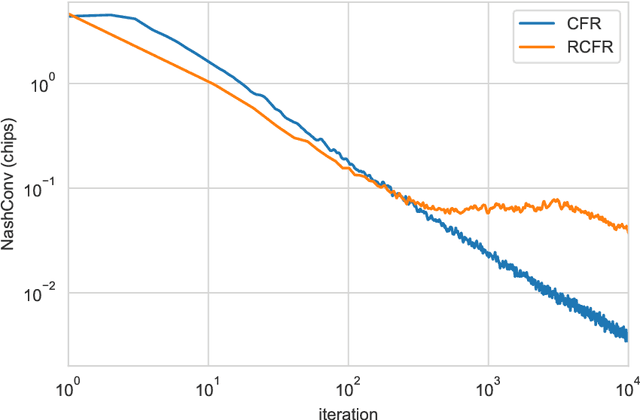
OpenSpiel is a collection of environments and algorithms for research in general reinforcement learning and search/planning in games. OpenSpiel supports n-player (single- and multi- agent) zero-sum, cooperative and general-sum, one-shot and sequential, strictly turn-taking and simultaneous-move, perfect and imperfect information games, as well as traditional multiagent environments such as (partially- and fully- observable) grid worlds and social dilemmas. OpenSpiel also includes tools to analyze learning dynamics and other common evaluation metrics. This document serves both as an overview of the code base and an introduction to the terminology, core concepts, and algorithms across the fields of reinforcement learning, computational game theory, and search.
Interval timing in deep reinforcement learning agents
May 31, 2019
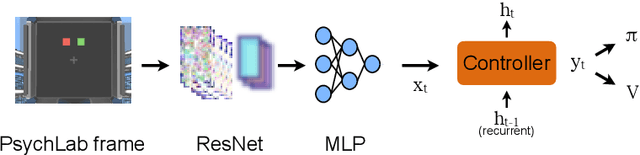
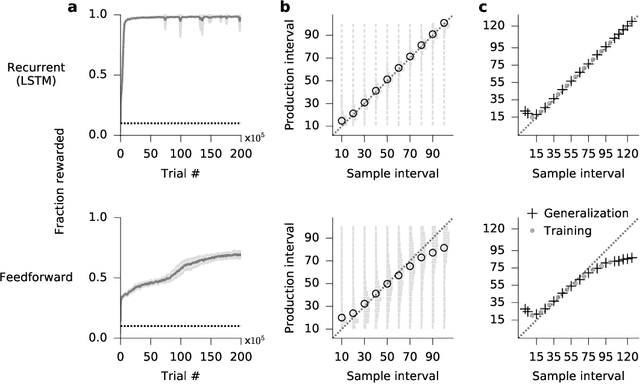
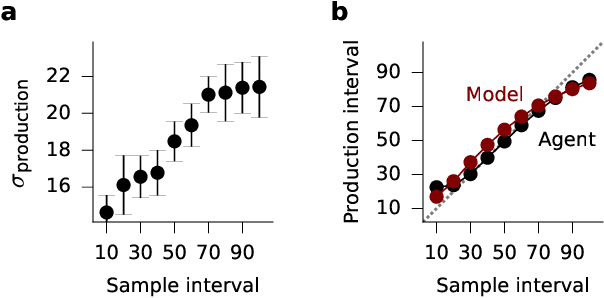
The measurement of time is central to intelligent behavior. We know that both animals and artificial agents can successfully use temporal dependencies to select actions. In artificial agents, little work has directly addressed (1) which architectural components are necessary for successful development of this ability, (2) how this timing ability comes to be represented in the units and actions of the agent, and (3) whether the resulting behavior of the system converges on solutions similar to those of biology. Here we studied interval timing abilities in deep reinforcement learning agents trained end-to-end on an interval reproduction paradigm inspired by experimental literature on mechanisms of timing. We characterize the strategies developed by recurrent and feedforward agents, which both succeed at temporal reproduction using distinct mechanisms, some of which bear specific and intriguing similarities to biological systems. These findings advance our understanding of how agents come to represent time, and they highlight the value of experimentally inspired approaches to characterizing agent abilities.
Relational inductive biases, deep learning, and graph networks
Oct 17, 2018
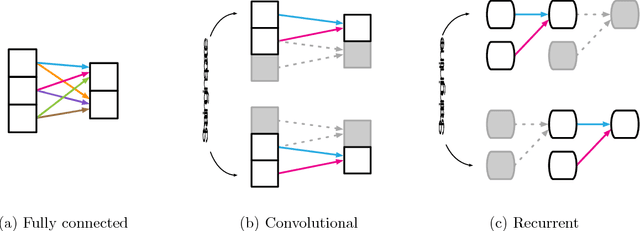
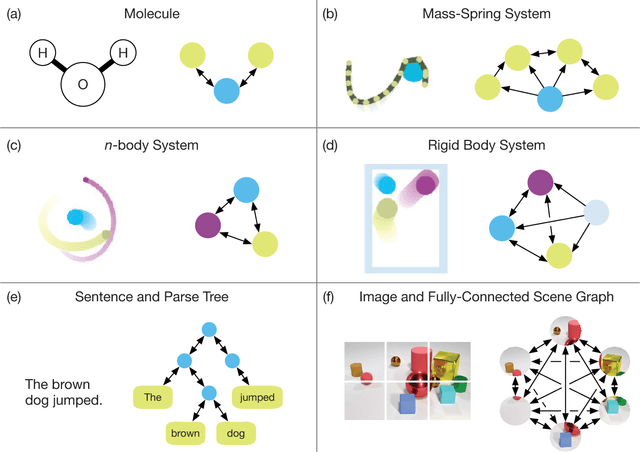
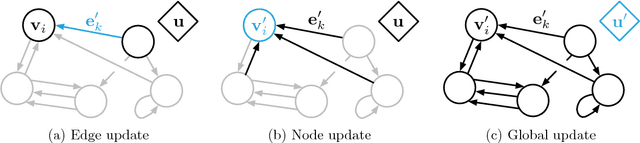
Artificial intelligence (AI) has undergone a renaissance recently, making major progress in key domains such as vision, language, control, and decision-making. This has been due, in part, to cheap data and cheap compute resources, which have fit the natural strengths of deep learning. However, many defining characteristics of human intelligence, which developed under much different pressures, remain out of reach for current approaches. In particular, generalizing beyond one's experiences--a hallmark of human intelligence from infancy--remains a formidable challenge for modern AI. The following is part position paper, part review, and part unification. We argue that combinatorial generalization must be a top priority for AI to achieve human-like abilities, and that structured representations and computations are key to realizing this objective. Just as biology uses nature and nurture cooperatively, we reject the false choice between "hand-engineering" and "end-to-end" learning, and instead advocate for an approach which benefits from their complementary strengths. We explore how using relational inductive biases within deep learning architectures can facilitate learning about entities, relations, and rules for composing them. We present a new building block for the AI toolkit with a strong relational inductive bias--the graph network--which generalizes and extends various approaches for neural networks that operate on graphs, and provides a straightforward interface for manipulating structured knowledge and producing structured behaviors. We discuss how graph networks can support relational reasoning and combinatorial generalization, laying the foundation for more sophisticated, interpretable, and flexible patterns of reasoning. As a companion to this paper, we have released an open-source software library for building graph networks, with demonstrations of how to use them in practice.
Relational recurrent neural networks
Jun 28, 2018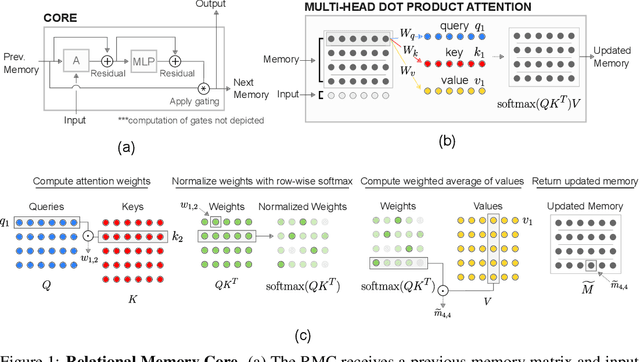
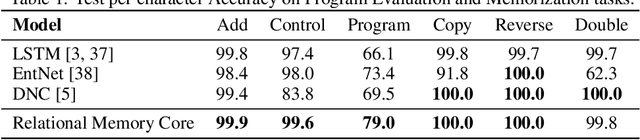
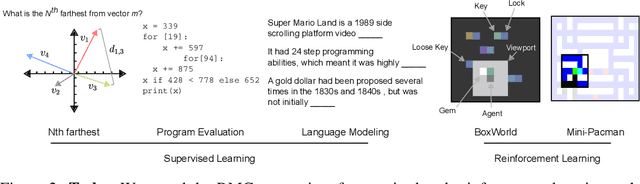
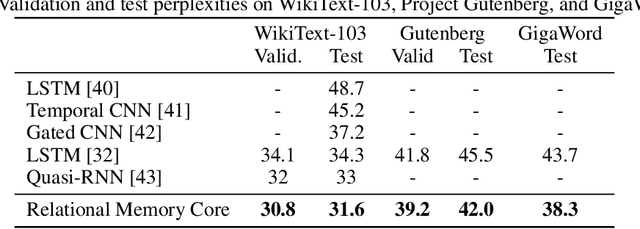
Memory-based neural networks model temporal data by leveraging an ability to remember information for long periods. It is unclear, however, whether they also have an ability to perform complex relational reasoning with the information they remember. Here, we first confirm our intuitions that standard memory architectures may struggle at tasks that heavily involve an understanding of the ways in which entities are connected -- i.e., tasks involving relational reasoning. We then improve upon these deficits by using a new memory module -- a \textit{Relational Memory Core} (RMC) -- which employs multi-head dot product attention to allow memories to interact. Finally, we test the RMC on a suite of tasks that may profit from more capable relational reasoning across sequential information, and show large gains in RL domains (e.g. Mini PacMan), program evaluation, and language modeling, achieving state-of-the-art results on the WikiText-103, Project Gutenberg, and GigaWord datasets.