 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Diffusion Sampling for Conditional LiDAR Generation
Oct 15, 2024

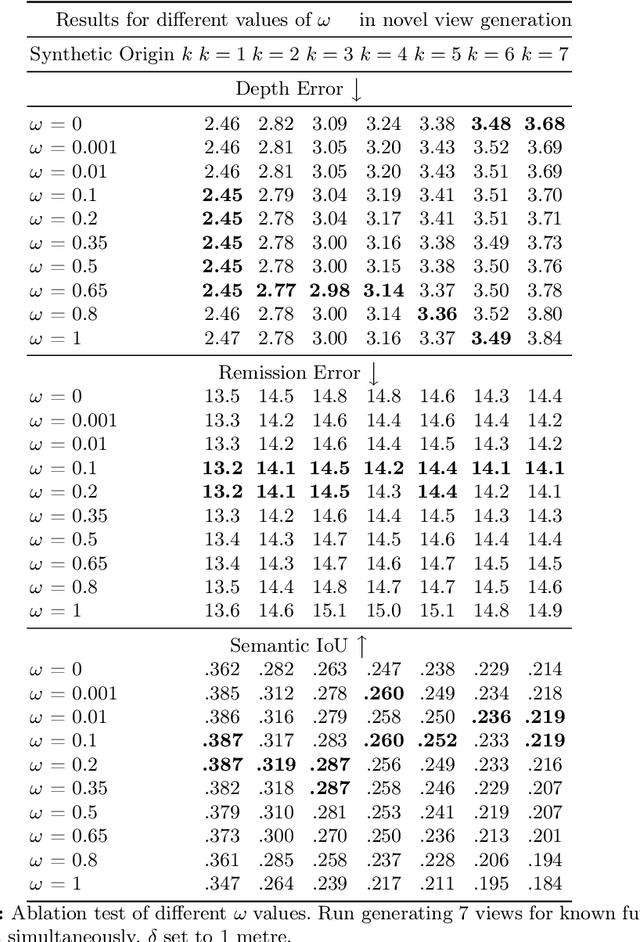
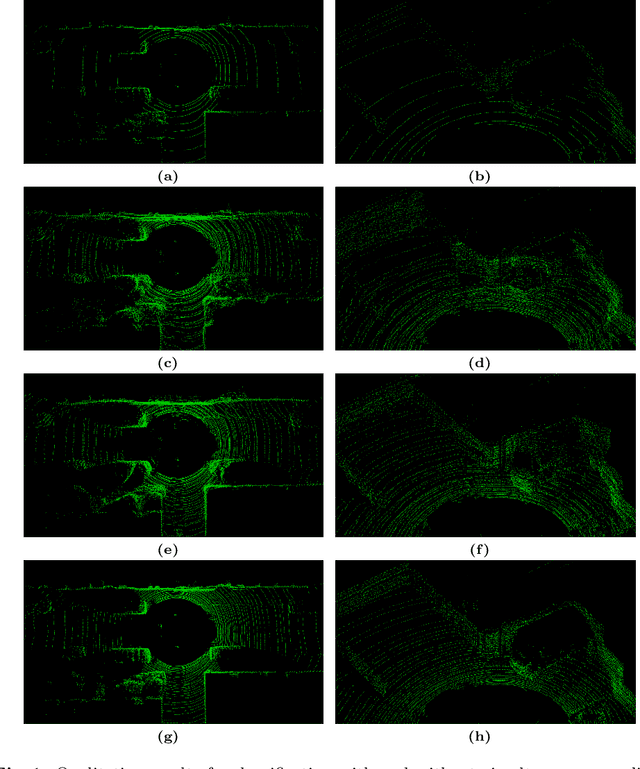
By enabling capturing of 3D point clouds that reflect the geometry of the immediate environment, LiDAR has emerged as a primary sensor for autonomous systems. If a LiDAR scan is too sparse, occluded by obstacles, or too small in range, enhancing the point cloud scan by while respecting the geometry of the scene is useful for downstream tasks. Motivated by the explosive growth of interest in generative methods in vision, conditional LiDAR generation is starting to take off. This paper proposes a novel simultaneous diffusion sampling methodology to generate point clouds conditioned on the 3D structure of the scene as seen from multiple views. The key idea is to impose multi-view geometric constraints on the generation process, exploiting mutual information for enhanced results. Our method begins by recasting the input scan to multiple new viewpoints around the scan, thus creating multiple synthetic LiDAR scans. Then, the synthetic and input LiDAR scans simultaneously undergo conditional generation according to our methodology. Results show that our method can produce accurate and geometrically consistent enhancements to point cloud scans, allowing it to outperform existing methods by a large margin in a variety of benchmarks.
Semantic Segmentation on 3D Point Clouds with High Density Variations
Jul 04, 2023



LiDAR scanning for surveying applications acquire measurements over wide areas and long distances, which produces large-scale 3D point clouds with significant local density variations. While existing 3D semantic segmentation models conduct downsampling and upsampling to build robustness against varying point densities, they are less effective under the large local density variations characteristic of point clouds from surveying applications. To alleviate this weakness, we propose a novel architecture called HDVNet that contains a nested set of encoder-decoder pathways, each handling a specific point density range. Limiting the interconnections between the feature maps enables HDVNet to gauge the reliability of each feature based on the density of a point, e.g., downweighting high density features not existing in low density objects. By effectively handling input density variations, HDVNet outperforms state-of-the-art models in segmentation accuracy on real point clouds with inconsistent density, using just over half the weights.