 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Diffusion Sampling for Conditional LiDAR Generation
Oct 15, 2024

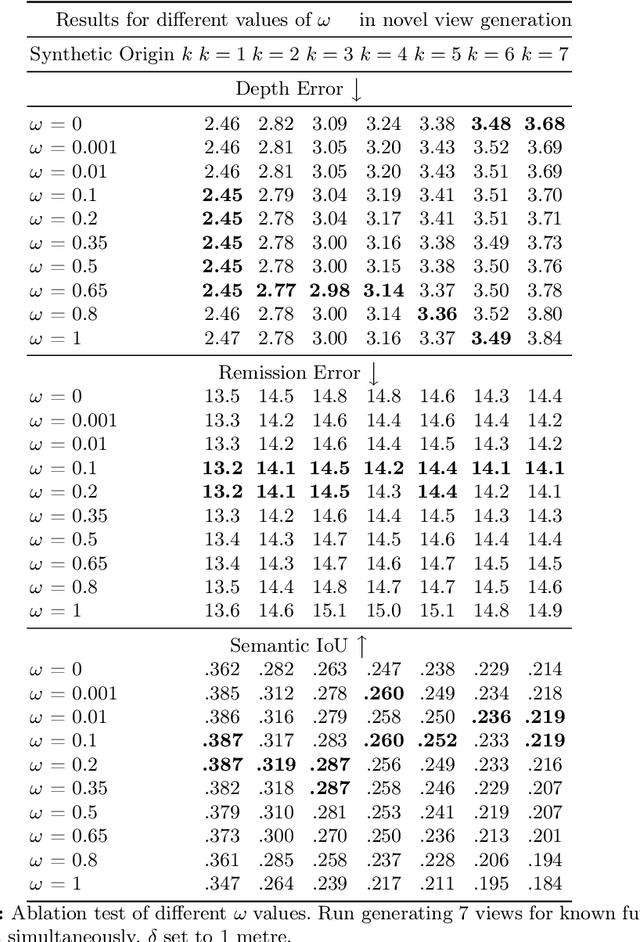
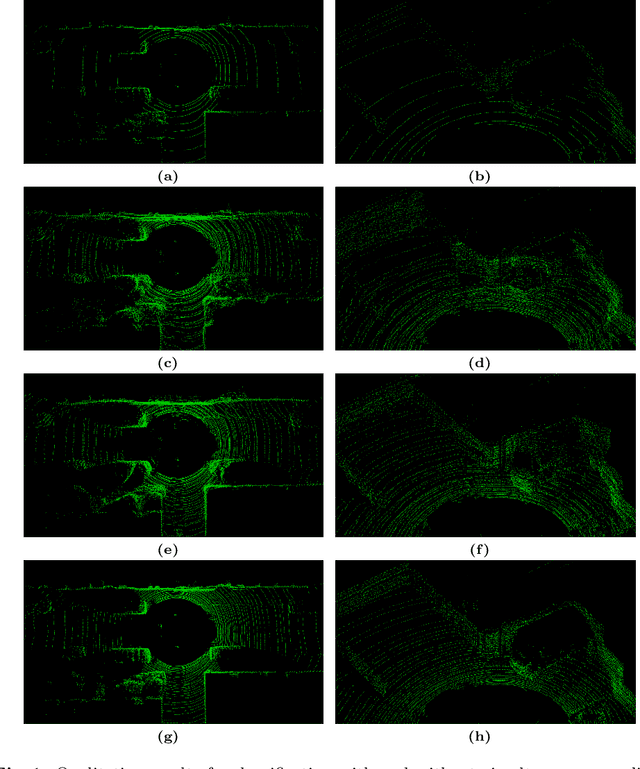
By enabling capturing of 3D point clouds that reflect the geometry of the immediate environment, LiDAR has emerged as a primary sensor for autonomous systems. If a LiDAR scan is too sparse, occluded by obstacles, or too small in range, enhancing the point cloud scan by while respecting the geometry of the scene is useful for downstream tasks. Motivated by the explosive growth of interest in generative methods in vision, conditional LiDAR generation is starting to take off. This paper proposes a novel simultaneous diffusion sampling methodology to generate point clouds conditioned on the 3D structure of the scene as seen from multiple views. The key idea is to impose multi-view geometric constraints on the generation process, exploiting mutual information for enhanced results. Our method begins by recasting the input scan to multiple new viewpoints around the scan, thus creating multiple synthetic LiDAR scans. Then, the synthetic and input LiDAR scans simultaneously undergo conditional generation according to our methodology. Results show that our method can produce accurate and geometrically consistent enhancements to point cloud scans, allowing it to outperform existing methods by a large margin in a variety of benchmarks.
TC-PDM: Temporally Consistent Patch Diffusion Models for Infrared-to-Visible Video Translation
Aug 26, 2024



Infrared imaging offers resilience against changing lighting conditions by capturing object temperatures. Yet, in few scenarios, its lack of visual details compared to daytime visible images, poses a significant challenge for human and machine interpretation. This paper proposes a novel diffusion method, dubbed Temporally Consistent Patch Diffusion Models (TC-DPM), for infrared-to-visible video translation. Our method, extending the Patch Diffusion Model, consists of two key components. Firstly, we propose a semantic-guided denoising, leveraging the strong representations of foundational models. As such, our method faithfully preserves the semantic structure of generated visible images. Secondly, we propose a novel temporal blending module to guide the denoising trajectory, ensuring the temporal consistency between consecutive frames. Experiment shows that TC-PDM outperforms state-of-the-art methods by 35.3% in FVD for infrared-to-visible video translation and by 6.1% in AP50 for day-to-night object detection. Our code is publicly available at https://github.com/dzungdoan6/tc-pdm
Weakly Supervised Test-Time Domain Adaptation for Object Detection
Jul 08, 2024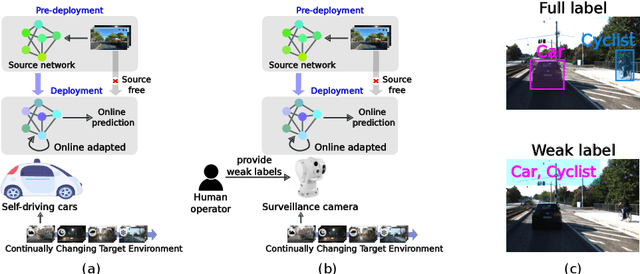

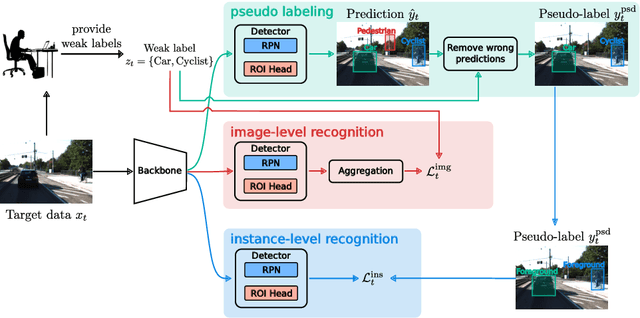

Prior to deployment, an object detector is trained on a dataset compiled from a previous data collection campaign. However, the environment in which the object detector is deployed will invariably evolve, particularly in outdoor settings where changes in lighting, weather and seasons will significantly affect the appearance of the scene and target objects. It is almost impossible for all potential scenarios that the object detector may come across to be present in a finite training dataset. This necessitates continuous updates to the object detector to maintain satisfactory performance. Test-time domain adaptation techniques enable machine learning models to self-adapt based on the distributions of the testing data. However, existing methods mainly focus on fully automated adaptation, which makes sense for applications such as self-driving cars. Despite the prevalence of fully automated approaches, in some applications such as surveillance, there is usually a human operator overseeing the system's operation. We propose to involve the operator in test-time domain adaptation to raise the performance of object detection beyond what is achievable by fully automated adaptation. To reduce manual effort, the proposed method only requires the operator to provide weak labels, which are then used to guide the adaptation process. Furthermore, the proposed method can be performed in a streaming setting, where each online sample is observed only once. We show that the proposed method outperforms existing works, demonstrating a great benefit of human-in-the-loop test-time domain adaptation. Our code is publicly available at https://github.com/dzungdoan6/WSTTA
Domain Adaptation for Satellite-Borne Hyperspectral Cloud Detection
Sep 05, 2023


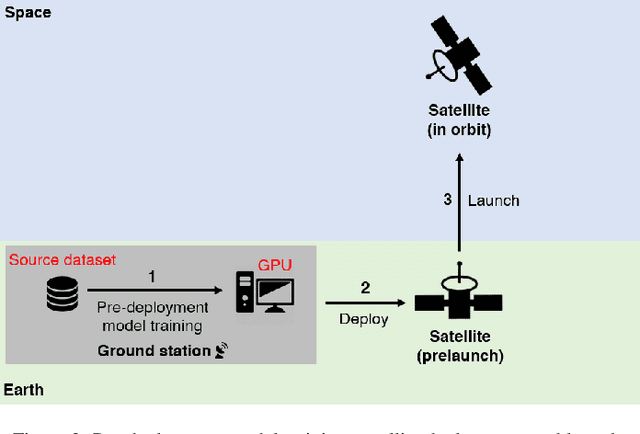
The advent of satellite-borne machine learning hardware accelerators has enabled the on-board processing of payload data using machine learning techniques such as convolutional neural networks (CNN). A notable example is using a CNN to detect the presence of clouds in hyperspectral data captured on Earth observation (EO) missions, whereby only clear sky data is downlinked to conserve bandwidth. However, prior to deployment, new missions that employ new sensors will not have enough representative datasets to train a CNN model, while a model trained solely on data from previous missions will underperform when deployed to process the data on the new missions. This underperformance stems from the domain gap, i.e., differences in the underlying distributions of the data generated by the different sensors in previous and future missions. In this paper, we address the domain gap problem in the context of on-board hyperspectral cloud detection. Our main contributions lie in formulating new domain adaptation tasks that are motivated by a concrete EO mission, developing a novel algorithm for bandwidth-efficient supervised domain adaptation, and demonstrating test-time adaptation algorithms on space deployable neural network accelerators. Our contributions enable minimal data transmission to be invoked (e.g., only 1% of the weights in ResNet50) to achieve domain adaptation, thereby allowing more sophisticated CNN models to be deployed and updated on satellites without being hampered by domain gap and bandwidth limitations.
Assessing Domain Gap for Continual Domain Adaptation in Object Detection
Feb 21, 2023



To ensure reliable object detection in autonomous systems, the detector must be able to adapt to changes in appearance caused by environmental factors such as time of day, weather, and seasons. Continually adapting the detector to incorporate these changes is a promising solution, but it can be computationally costly. Our proposed approach is to selectively adapt the detector only when necessary, using new data that does not have the same distribution as the current training data. To this end, we investigate three popular metrics for domain gap evaluation and find that there is a correlation between the domain gap and detection accuracy. Therefore, we apply the domain gap as a criterion to decide when to adapt the detector. Our experiments show that our approach has the potential to improve the efficiency of the detector's operation in real-world scenarios, where environmental conditions change in a cyclical manner, without sacrificing the overall performance of the detector. Our code is publicly available at https://github.com/dadung/DGE-CDA.
A Hybrid Quantum-Classical Algorithm for Robust Fitting
Jan 31, 2022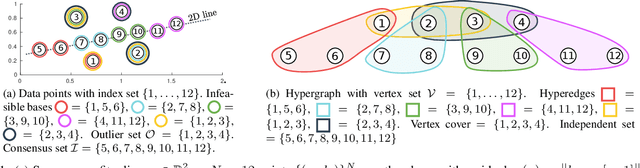
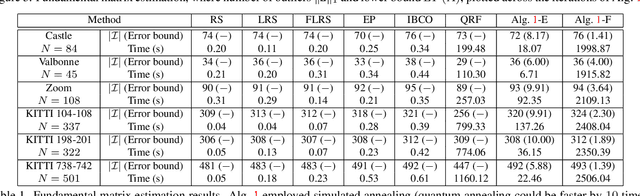
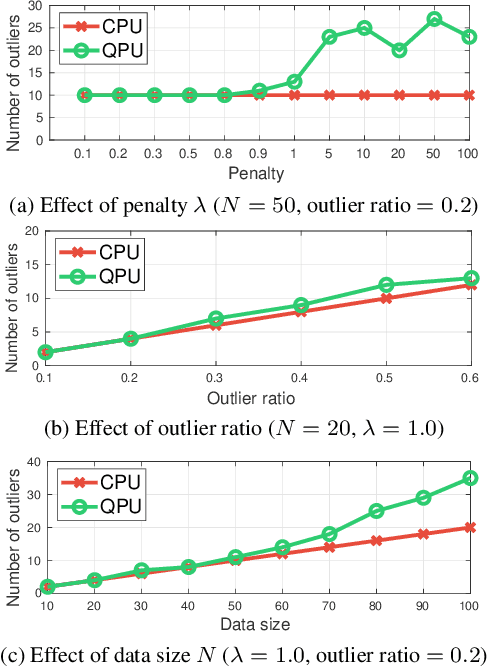
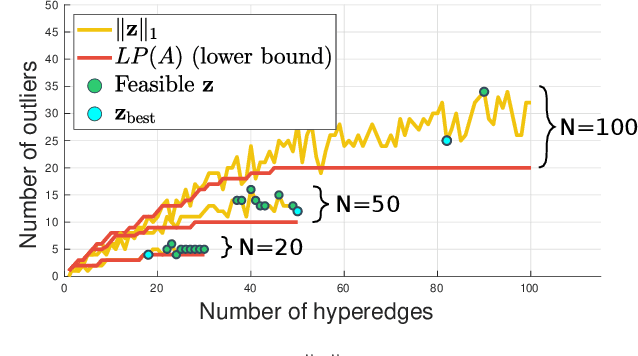
Fitting geometric models onto outlier contaminated data is provably intractable. Many computer vision systems rely on random sampling heuristics to solve robust fitting, which do not provide optimality guarantees and error bounds. It is therefore critical to develop novel approaches that can bridge the gap between exact solutions that are costly, and fast heuristics that offer no quality assurances. In this paper, we propose a hybrid quantum-classical algorithm for robust fitting. Our core contribution is a novel robust fitting formulation that solves a sequence of integer programs and terminates with a global solution or an error bound. The combinatorial subproblems are amenable to a quantum annealer, which helps to tighten the bound efficiently. While our usage of quantum computing does not surmount the fundamental intractability of robust fitting, by providing error bounds our algorithm is a practical improvement over randomised heuristics. Moreover, our work represents a concrete application of quantum computing in computer vision. We present results obtained using an actual quantum computer (D-Wave Advantage) and via simulation. Source code: https://github.com/dadung/HQC-robust-fitting
Robotic Vision for Space Mining
Sep 30, 2021

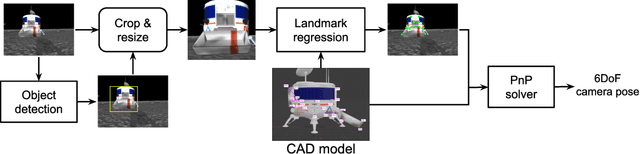

Future Moon bases will likely be constructed using resources mined from the surface of the Moon. The difficulty of maintaining a human workforce on the Moon and communications lag with Earth means that mining will need to be conducted using collaborative robots with a high degree of autonomy. In this paper, we explore the utility of robotic vision towards addressing several major challenges in autonomous mining in the lunar environment: lack of satellite positioning systems, navigation in hazardous terrain, and delicate robot interactions. Specifically, we describe and report the results of robotic vision algorithms that we developed for Phase 2 of the NASA Space Robotics Challenge, which was framed in the context of autonomous collaborative robots for mining on the Moon. The competition provided a simulated lunar environment that exhibits the complexities alluded to above. We show how machine learning-enabled vision could help alleviate the challenges posed by the lunar environment. A robust multi-robot coordinator was also developed to achieve long-term operation and effective collaboration between robots.
Learning to Predict Repeatability of Interest Points
May 08, 2021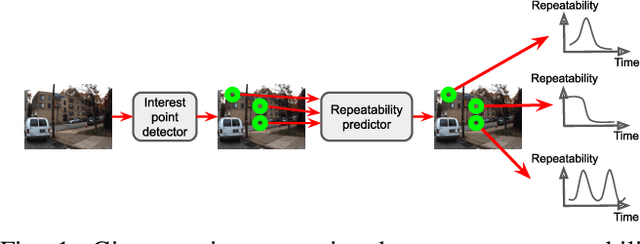
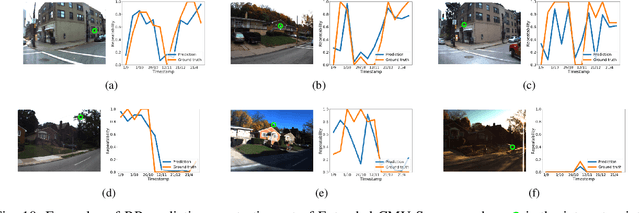
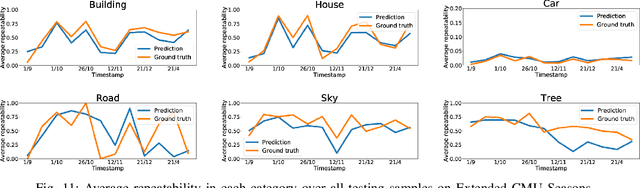
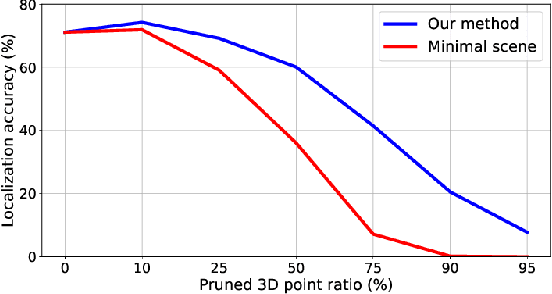
Many robotics applications require interest points that are highly repeatable under varying viewpoints and lighting conditions. However, this requirement is very challenging as the environment changes continuously and indefinitely, leading to appearance changes of interest points with respect to time. This paper proposes to predict the repeatability of an interest point as a function of time, which can tell us the lifespan of the interest point considering daily or seasonal variation. The repeatability predictor (RP) is formulated as a regressor trained on repeated interest points from multiple viewpoints over a long period of time. Through comprehensive experiments, we demonstrate that our RP can estimate when a new interest point is repeated, and also highlight an insightful analysis about this problem. For further comparison, we apply our RP to the map summarization under visual localization framework, which builds a compact representation of the full context map given the query time. The experimental result shows a careful selection of potentially repeatable interest points predicted by our RP can significantly mitigate the degeneration of localization accuracy from map summarization.
HM4: Hidden Markov Model with Memory Management for Visual Place Recognition
Nov 01, 2020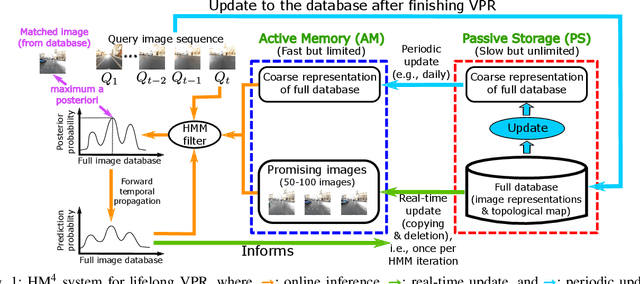
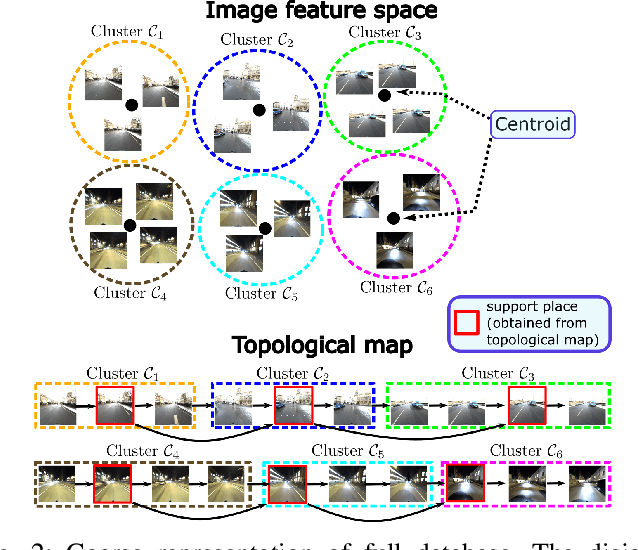
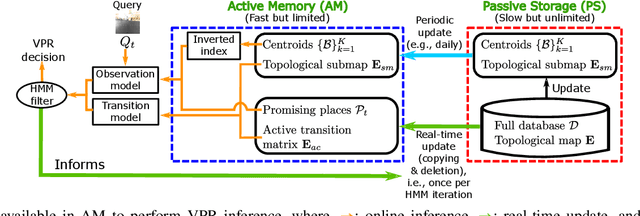
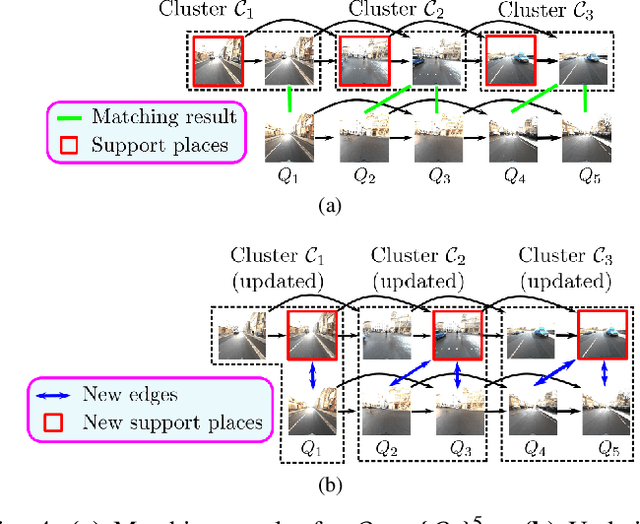
Visual place recognition needs to be robust against appearance variability due to natural and man-made causes. Training data collection should thus be an ongoing process to allow continuous appearance changes to be recorded. However, this creates an unboundedly-growing database that poses time and memory scalability challenges for place recognition methods. To tackle the scalability issue for visual place recognition in autonomous driving, we develop a Hidden Markov Model approach with a two-tiered memory management. Our algorithm, dubbed HM$^4$, exploits temporal look-ahead to transfer promising candidate images between passive storage and active memory when needed. The inference process takes into account both promising images and a coarse representations of the full database. We show that this allows constant time and space inference for a fixed coverage area. The coarse representations can also be updated incrementally to absorb new data. To further reduce the memory requirements, we derive a compact image representation inspired by Locality Sensitive Hashing (LSH). Through experiments on real world data, we demonstrate the excellent scalability and accuracy of the approach under appearance changes and provide comparisons against state-of-the-art techniques.
In defense of OSVOS
Aug 20, 2019
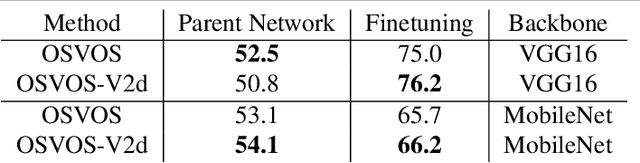

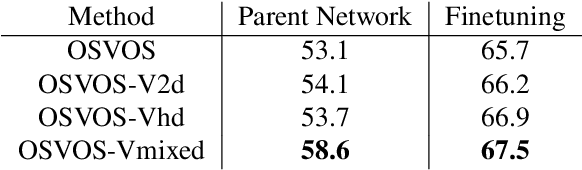
As a milestone for video object segmentation, one-shot video object segmentation (OSVOS) has achieved a large margin compared to the conventional optical-flow based methods regarding to the segmentation accuracy. Its excellent performance mainly benefit from the three-step training mechanism, that are: (1) acquiring object features on the base dataset (i.e. ImageNet), (2) training the parent network on the training set of the target dataset (i.e. DAVIS-2016) to be capable of differentiating the object of interest from the background. (3) online fine-tuning the interested object on the first frame of the target test set to overfit its appearance, then the model can be utilized to segment the same object in the rest frames of that video. In this paper, we argue that for the step (2), OSVOS has the limitation to 'overemphasize' the generic semantic object information while 'dilute' the instance cues of the object(s), which largely block the whole training process. Through adding a common module, video loss, which we formulate with various forms of constraints (including weighted BCE loss, high-dimensional triplet loss, as well as a novel mixed instance-aware video loss), to train the parent network in the step (2), the network is then better prepared for the step (3), i.e. online fine-tuning on the target instance. Through extensive experiments using different network structures as the backbone, we show that the proposed video loss module can improve the segmentation performance significantly, compared to that of OSVOS. Meanwhile, since video loss is a common module, it can be generalized to other fine-tuning based methods and similar vision tasks such as depth estimation and saliency detection.