 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTC-PDM: Temporally Consistent Patch Diffusion Models for Infrared-to-Visible Video Translation
Aug 26, 2024



Infrared imaging offers resilience against changing lighting conditions by capturing object temperatures. Yet, in few scenarios, its lack of visual details compared to daytime visible images, poses a significant challenge for human and machine interpretation. This paper proposes a novel diffusion method, dubbed Temporally Consistent Patch Diffusion Models (TC-DPM), for infrared-to-visible video translation. Our method, extending the Patch Diffusion Model, consists of two key components. Firstly, we propose a semantic-guided denoising, leveraging the strong representations of foundational models. As such, our method faithfully preserves the semantic structure of generated visible images. Secondly, we propose a novel temporal blending module to guide the denoising trajectory, ensuring the temporal consistency between consecutive frames. Experiment shows that TC-PDM outperforms state-of-the-art methods by 35.3% in FVD for infrared-to-visible video translation and by 6.1% in AP50 for day-to-night object detection. Our code is publicly available at https://github.com/dzungdoan6/tc-pdm
Weakly Supervised Test-Time Domain Adaptation for Object Detection
Jul 08, 2024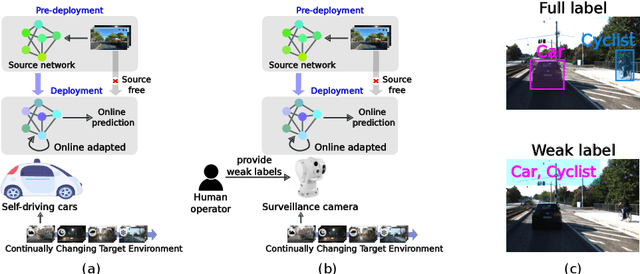

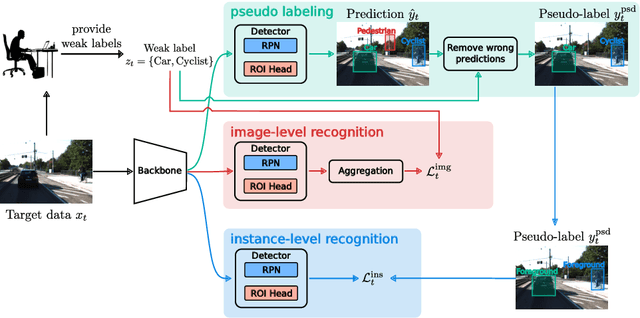

Prior to deployment, an object detector is trained on a dataset compiled from a previous data collection campaign. However, the environment in which the object detector is deployed will invariably evolve, particularly in outdoor settings where changes in lighting, weather and seasons will significantly affect the appearance of the scene and target objects. It is almost impossible for all potential scenarios that the object detector may come across to be present in a finite training dataset. This necessitates continuous updates to the object detector to maintain satisfactory performance. Test-time domain adaptation techniques enable machine learning models to self-adapt based on the distributions of the testing data. However, existing methods mainly focus on fully automated adaptation, which makes sense for applications such as self-driving cars. Despite the prevalence of fully automated approaches, in some applications such as surveillance, there is usually a human operator overseeing the system's operation. We propose to involve the operator in test-time domain adaptation to raise the performance of object detection beyond what is achievable by fully automated adaptation. To reduce manual effort, the proposed method only requires the operator to provide weak labels, which are then used to guide the adaptation process. Furthermore, the proposed method can be performed in a streaming setting, where each online sample is observed only once. We show that the proposed method outperforms existing works, demonstrating a great benefit of human-in-the-loop test-time domain adaptation. Our code is publicly available at https://github.com/dzungdoan6/WSTTA
Detecting Fallacies in Climate Misinformation: A Technocognitive Approach to Identifying Misleading Argumentation
May 14, 2024Misinformation about climate change is a complex societal issue requiring holistic, interdisciplinary solutions at the intersection between technology and psychology. One proposed solution is a "technocognitive" approach, involving the synthesis of psychological and computer science research. Psychological research has identified that interventions in response to misinformation require both fact-based (e.g., factual explanations) and technique-based (e.g., explanations of misleading techniques) content. However, little progress has been made on documenting and detecting fallacies in climate misinformation. In this study, we apply a previously developed critical thinking methodology for deconstructing climate misinformation, in order to develop a dataset mapping different types of climate misinformation to reasoning fallacies. This dataset is used to train a model to detect fallacies in climate misinformation. Our study shows F1 scores that are 2.5 to 3.5 better than previous works. The fallacies that are easiest to detect include fake experts and anecdotal arguments, while fallacies that require background knowledge, such as oversimplification, misrepresentation, and slothful induction, are relatively more difficult to detect. This research lays the groundwork for development of solutions where automatically detected climate misinformation can be countered with generative technique-based corrections.
CryptOpt: Automatic Optimization of Straightline Code
May 31, 2023



Manual engineering of high-performance implementations typically consumes many resources and requires in-depth knowledge of the hardware. Compilers try to address these problems; however, they are limited by design in what they can do. To address this, we present CryptOpt, an automatic optimizer for long stretches of straightline code. Experimental results across eight hardware platforms show that CryptOpt achieves a speed-up factor of up to 2.56 over current off-the-shelf compilers.
Assessing Domain Gap for Continual Domain Adaptation in Object Detection
Feb 21, 2023



To ensure reliable object detection in autonomous systems, the detector must be able to adapt to changes in appearance caused by environmental factors such as time of day, weather, and seasons. Continually adapting the detector to incorporate these changes is a promising solution, but it can be computationally costly. Our proposed approach is to selectively adapt the detector only when necessary, using new data that does not have the same distribution as the current training data. To this end, we investigate three popular metrics for domain gap evaluation and find that there is a correlation between the domain gap and detection accuracy. Therefore, we apply the domain gap as a criterion to decide when to adapt the detector. Our experiments show that our approach has the potential to improve the efficiency of the detector's operation in real-world scenarios, where environmental conditions change in a cyclical manner, without sacrificing the overall performance of the detector. Our code is publicly available at https://github.com/dadung/DGE-CDA.
Socialz: Multi-Feature Social Fuzz Testing
Feb 17, 2023

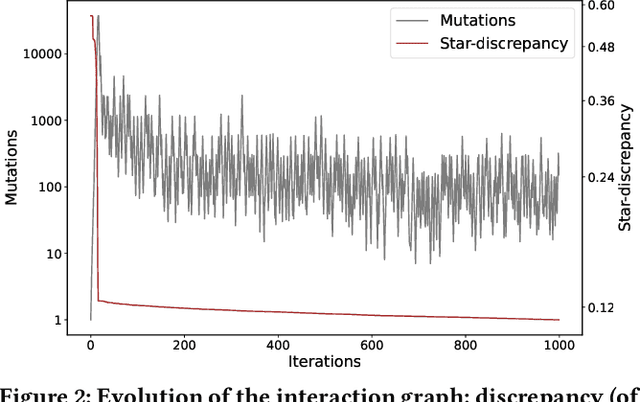
Online social networks have become an integral aspect of our daily lives and play a crucial role in shaping our relationships with others. However, bugs and glitches, even minor ones, can cause anything from frustrating problems to serious data leaks that can have far-reaching impacts on millions of users. To mitigate these risks, fuzz testing, a method of testing with randomised inputs, can provide increased confidence in the correct functioning of a social network. However, implementing traditional fuzz testing methods can be prohibitively difficult or impractical for programmers outside of the network's development team. To tackle this challenge, we present Socialz, a novel approach to social fuzz testing that (1) characterises real users of a social network, (2) diversifies their interaction using evolutionary computation across multiple, non-trivial features, and (3) collects performance data as these interactions are executed. With Socialz, we aim to provide anyone with the capability to perform comprehensive social testing, thereby improving the reliability and security of online social networks used around the world.
ELEA -- Build your own Evolutionary Algorithm in your Browser
Feb 13, 2023



We provide an open source framework to experiment with evolutionary algorithms which we call "Experimenting and Learning toolkit for Evolutionary Algorithms (ELEA)". ELEA is browser-based and allows to assemble evolutionary algorithms using drag-and-drop, starting from a number of simple pre-designed examples, making the startup costs for employing the toolkit minimal. The designed examples can be executed and collected data can be displayed graphically. Further features include export of algorithm designs and experimental results as well as multi-threading. With the very intuitive user interface and the short time to get initial experiments going, this tool is especially suitable for explorative analyses of algorithms as well as for the use in classrooms.
CryptOpt: Verified Compilation with Random Program Search for Cryptographic Primitives
Nov 19, 2022



Most software domains rely on compilers to translate high-level code to multiple different machine languages, with performance not too much worse than what developers would have the patience to write directly in assembly language. However, cryptography has been an exception, where many performance-critical routines have been written directly in assembly (sometimes through metaprogramming layers). Some past work has shown how to do formal verification of that assembly, and other work has shown how to generate C code automatically along with formal proof, but with consequent performance penalties vs. the best-known assembly. We present CryptOpt, the first compilation pipeline that specializes high-level cryptographic functional programs into assembly code significantly faster than what GCC or Clang produce, with mechanized proof (in Coq) whose final theorem statement mentions little beyond the input functional program and the operational semantics of x86-64 assembly. On the optimization side, we apply randomized search through the space of assembly programs, with repeated automatic benchmarking on target CPUs. On the formal-verification side, we connect to the Fiat Cryptography framework (which translates functional programs into C-like IR code) and extend it with a new formally verified program-equivalence checker, incorporating a modest subset of known features of SMT solvers and symbolic-execution engines. The overall prototype is quite practical, e.g. producing new fastest-known implementations for the relatively new Intel i9 12G, of finite-field arithmetic for both Curve25519 (part of the TLS standard) and the Bitcoin elliptic curve secp256k1.
Fairness in generative modeling
Oct 06, 2022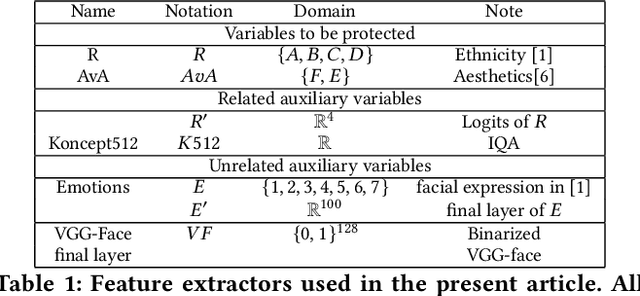
We design general-purpose algorithms for addressing fairness issues and mode collapse in generative modeling. More precisely, to design fair algorithms for as many sensitive variables as possible, including variables we might not be aware of, we assume no prior knowledge of sensitive variables: our algorithms use unsupervised fairness only, meaning no information related to the sensitive variables is used for our fairness-improving methods. All images of faces (even generated ones) have been removed to mitigate legal risks.
Automatically Categorising GitHub Repositories by Application Domain
Jul 30, 2022

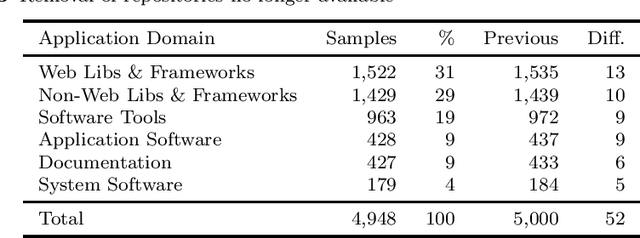

GitHub is the largest host of open source software on the Internet. This large, freely accessible database has attracted the attention of practitioners and researchers alike. But as GitHub's growth continues, it is becoming increasingly hard to navigate the plethora of repositories which span a wide range of domains. Past work has shown that taking the application domain into account is crucial for tasks such as predicting the popularity of a repository and reasoning about project quality. In this work, we build on a previously annotated dataset of 5,000 GitHub repositories to design an automated classifier for categorising repositories by their application domain. The classifier uses state-of-the-art natural language processing techniques and machine learning to learn from multiple data sources and catalogue repositories according to five application domains. We contribute with (1) an automated classifier that can assign popular repositories to each application domain with at least 70% precision, (2) an investigation of the approach's performance on less popular repositories, and (3) a practical application of this approach to answer how the adoption of software engineering practices differs across application domains. Our work aims to help the GitHub community identify repositories of interest and opens promising avenues for future work investigating differences between repositories from different application domains.