 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGray-Box Optimization and the Vertex Coloring Problem
Jun 06, 2026Gray-box optimization is an approach for making some problem-specific information available to the algorithm while still relying on fitness information as the main guide to an optimum. This approach was shown to be beneficial in various combinatorial optimization tasks and neatly captures the continuum between fully black-box algorithms and tailored algorithms. In this work, we discuss different flavors of gray-box algorithms. We show that RLS can find a proper $2$-coloring in a bipartite graph starting from a random $2$-coloring, in an expected time of $\mathcal{O}(n \log n)$. In contrast, when starting from a proper $n$-coloring, the (1+1) EA cannot find such a coloring except when offered additional guiding on plateaus of the search space. Finally, we show the run time for this setting can be much improved by using gray-box operators.
Combinatorial Landscape Analysis for Dominating Set and Vertex Coloring
Jun 05, 2026We analyze the two combinatorial problems of Dominating Set and Vertex Coloring regarding what kind of local optima are present for various instances. For a variety of graph classes each, we determine whether the induced landscapes are unimodal, plateau-unimodal (all optima are just one plateau), equimodal (all local optima are global) or truly multimodal. We do this for two different neighborhood operators, one based on making only a single change and one also allowing swaps (interchanging two parts of the solution).
Analysis of Search Heuristics in the Multi-Armed Bandit Setting
Apr 09, 2026We consider the classic Multi-Armed Bandit setting to understand the exploration/exploitation tradeoffs made by different search heuristics. Since many search heuristics work by comparing different options (in evolutionary algorithms called "individuals"; in the Bandit literature called "arms"), we work with the "Dueling Bandits" setting. In each iteration, a comparison between different arms can be made; in the binary stochastic setting, each arm has a fixed winning probability against any other arm. A Condorcet winner is any arm that beats every other arm with a probability strictly higher than $1/2$. We show that evolutionary algorithms are rather bad at identifying the Condorcet winner: Even if the Condorcet winner beats every other arm with a probability $1-p$, the (1+1) EA, in its stationary distribution, chooses the Condorcet winner only with constant probability if $p=Ω(1/n)$. By contrast, we show that a simple EDA (based on the Max-Min Ant System with iteration-best update) will choose the Condorcet winner in its maintained distribution with probability $1-Θ(p)$. As a remedy for the (1+1) EA, we show how repeated duels can significantly boost the probability of the Condorcet winner in the stationary distribution.
Anytime Analysis on BinVal: Adaptive Parameters Help
Apr 08, 2026While most theoretical run time analyses of discrete randomized search heuristics provide bounds on the expected number of evaluations to find the global optimum, we consider the anytime performance of evolutionary and estimation-of-distribution algorithms. For this purpose, we analyze the fixed-target run time of various algorithms using BinVal as fitness function and bound the run time to optimize the most significant $k \in o(n)$ bits of a bit string with length $n$. We analyze the run times such that they hold not only for a fixed $k$, but simultaneously for all $k \in o(n)$. For the standard (1+1) EA with fixed mutation rate $1/n$, we show that the fixed-target run time for all $k \in o(n)$ is in $Θ(n \log k)$. Using an EDA instead, we get an expected number of evaluations of $Θ(k \log n)$ for the sig-cGA. Replacing in the standard (1+1) EA the fixed mutation rate with a self-adjusting rate, we show that the fixed-target run time for $k \in o(n)$ and a constant $\varepsilon >0$ arbitrarily close to zero is in $\mathcal{O}\left(k^{1+\varepsilon}\right)$ for this algorithm. In particular, this run time is independent of $n$, holds simultaneously for all $k \in o(n)$, and is close to the run time of $Θ(k \log k)$ for the (1+1) EA with the best fixed mutation rate if $k$ is known.
Run Time Bounds for Integer-Valued OneMax Functions
Jul 21, 2023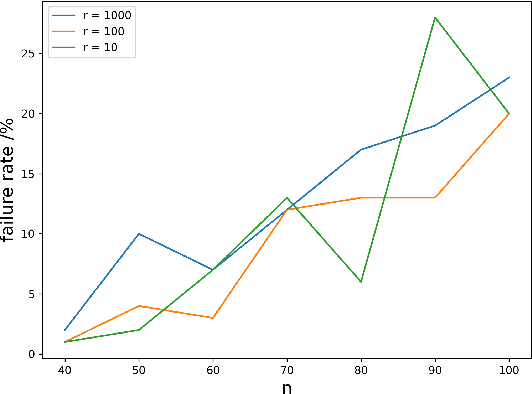
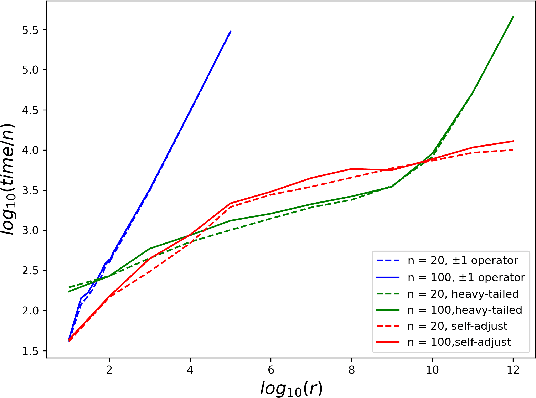
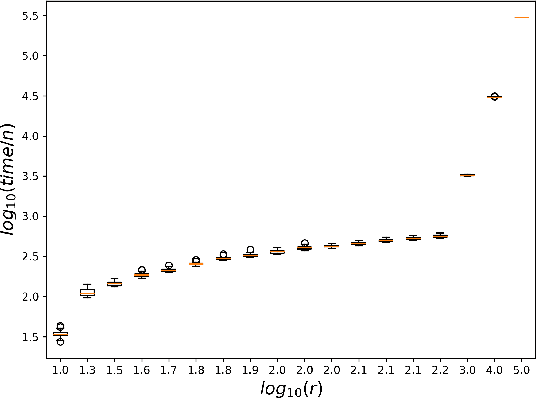
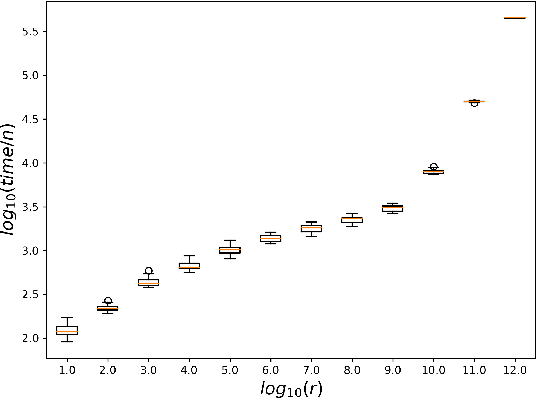
While most theoretical run time analyses of discrete randomized search heuristics focused on finite search spaces, we consider the search space $\mathbb{Z}^n$. This is a further generalization of the search space of multi-valued decision variables $\{0,\ldots,r-1\}^n$. We consider as fitness functions the distance to the (unique) non-zero optimum $a$ (based on the $L_1$-metric) and the \ooea which mutates by applying a step-operator on each component that is determined to be varied. For changing by $\pm 1$, we show that the expected optimization time is $\Theta(n \cdot (|a|_{\infty} + \log(|a|_H)))$. In particular, the time is linear in the maximum value of the optimum $a$. Employing a different step operator which chooses a step size from a distribution so heavy-tailed that the expectation is infinite, we get an optimization time of $O(n \cdot \log^2 (|a|_1) \cdot \left(\log (\log (|a|_1))\right)^{1 + \epsilon})$. Furthermore, we show that RLS with step size adaptation achieves an optimization time of $\Theta(n \cdot \log(|a|_1))$. We conclude with an empirical analysis, comparing the above algorithms also with a variant of CMA-ES for discrete search spaces.
Analysis of the EA on LeadingOnes with Constraints
May 29, 2023Understanding how evolutionary algorithms perform on constrained problems has gained increasing attention in recent years. In this paper, we study how evolutionary algorithms optimize constrained versions of the classical LeadingOnes problem. We first provide a run time analysis for the classical (1+1) EA on the LeadingOnes problem with a deterministic cardinality constraint, giving $\Theta(n (n-B)\log(B) + n^2)$ as the tight bound. Our results show that the behaviour of the algorithm is highly dependent on the constraint bound of the uniform constraint. Afterwards, we consider the problem in the context of stochastic constraints and provide insights using experimental studies on how the ($\mu$+1) EA is able to deal with these constraints in a sampling-based setting.
ELEA -- Build your own Evolutionary Algorithm in your Browser
Feb 13, 2023



We provide an open source framework to experiment with evolutionary algorithms which we call "Experimenting and Learning toolkit for Evolutionary Algorithms (ELEA)". ELEA is browser-based and allows to assemble evolutionary algorithms using drag-and-drop, starting from a number of simple pre-designed examples, making the startup costs for employing the toolkit minimal. The designed examples can be executed and collected data can be displayed graphically. Further features include export of algorithm designs and experimental results as well as multi-threading. With the very intuitive user interface and the short time to get initial experiments going, this tool is especially suitable for explorative analyses of algorithms as well as for the use in classrooms.
Theoretical Study of Optimizing Rugged Landscapes with the cGA
Nov 24, 2022Estimation of distribution algorithms (EDAs) provide a distribution - based approach for optimization which adapts its probability distribution during the run of the algorithm. We contribute to the theoretical understanding of EDAs and point out that their distribution approach makes them more suitable to deal with rugged fitness landscapes than classical local search algorithms. Concretely, we make the OneMax function rugged by adding noise to each fitness value. The cGA can nevertheless find solutions with n(1 - \epsilon) many 1s, even for high variance of noise. In contrast to this, RLS and the (1+1) EA, with high probability, only find solutions with n(1/2+o(1)) many 1s, even for noise with small variance.
Lower Bounds from Fitness Levels Made Easy
Apr 28, 2021One of the first and easy to use techniques for proving run time bounds for evolutionary algorithms is the so-called method of fitness levels by Wegener. It uses a partition of the search space into a sequence of levels which are traversed by the algorithm in increasing order, possibly skipping levels. An easy, but often strong upper bound for the run time can then be derived by adding the reciprocals of the probabilities to leave the levels (or upper bounds for these). Unfortunately, a similarly effective method for proving lower bounds has not yet been established. The strongest such method, proposed by Sudholt (2013), requires a careful choice of the viscosity parameters $\gamma_{i,j}$, $0 \le i < j \le n$. In this paper we present two new variants of the method, one for upper and one for lower bounds. Besides the level leaving probabilities, they only rely on the probabilities that levels are visited at all. We show that these can be computed or estimated without greater difficulties and apply our method to reprove the following known results in an easy and natural way. (i) The precise run time of the (1+1) EA on \textsc{LeadingOnes}. (ii) A lower bound for the run time of the (1+1) EA on \textsc{OneMax}, tight apart from an $O(n)$ term. (iii) A lower bound for the run time of the (1+1) EA on long $k$-paths. We also prove a tighter lower bound for the run time of the (1+1) EA on jump functions by showing that, regardless of the jump size, only with probability $O(2^{-n})$ the algorithm can avoid to jump over the valley of low fitness.
Maps for Learning Indexable Classes
Oct 15, 2020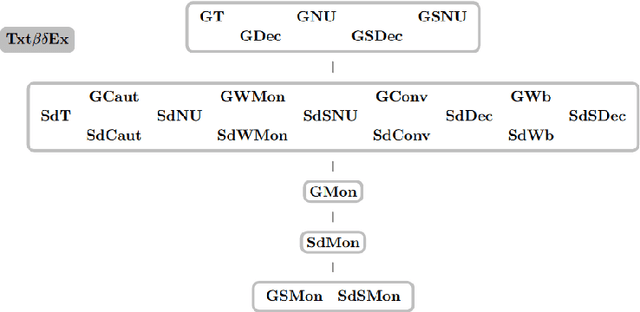
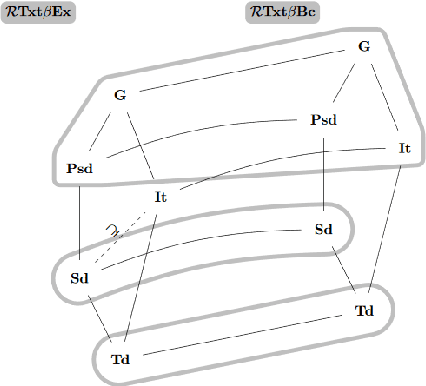
We study learning of indexed families from positive data where a learner can freely choose a hypothesis space (with uniformly decidable membership) comprising at least the languages to be learned. This abstracts a very universal learning task which can be found in many areas, for example learning of (subsets of) regular languages or learning of natural languages. We are interested in various restrictions on learning, such as consistency, conservativeness or set-drivenness, exemplifying various natural learning restrictions. Building on previous results from the literature, we provide several maps (depictions of all pairwise relations) of various groups of learning criteria, including a map for monotonicity restrictions and similar criteria and a map for restrictions on data presentation. Furthermore, we consider, for various learning criteria, whether learners can be assumed consistent.