 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Don't be Afraid of Over-Smoothing And Over-Squashing
Jan 12, 2026Over-smoothing and over-squashing have been extensively studied in the literature on Graph Neural Networks (GNNs) over the past years. We challenge this prevailing focus in GNN research, arguing that these phenomena are less critical for practical applications than assumed. We suggest that performance decreases often stem from uninformative receptive fields rather than over-smoothing. We support this position with extensive experiments on several standard benchmark datasets, demonstrating that accuracy and over-smoothing are mostly uncorrelated and that optimal model depths remain small even with mitigation techniques, thus highlighting the negligible role of over-smoothing. Similarly, we challenge that over-squashing is always detrimental in practical applications. Instead, we posit that the distribution of relevant information over the graph frequently factorises and is often localised within a small k-hop neighbourhood, questioning the necessity of jointly observing entire receptive fields or engaging in an extensive search for long-range interactions. The results of our experiments show that architectural interventions designed to mitigate over-squashing fail to yield significant performance gains. This position paper advocates for a paradigm shift in theoretical research, urging a diligent analysis of learning tasks and datasets using statistics that measure the underlying distribution of label-relevant information to better understand their localisation and factorisation.
Improved Runtime Guarantees for the SPEA2 Multi-Objective Optimizer
Nov 10, 2025Together with the NSGA-II, the SPEA2 is one of the most widely used domination-based multi-objective evolutionary algorithms. For both algorithms, the known runtime guarantees are linear in the population size; for the NSGA-II, matching lower bounds exist. With a careful study of the more complex selection mechanism of the SPEA2, we show that it has very different population dynamics. From these, we prove runtime guarantees for the OneMinMax, LeadingOnesTrailingZeros, and OneJumpZeroJump benchmarks that depend less on the population size. For example, we show that the SPEA2 with parent population size $μ\ge n - 2k + 3$ and offspring population size $λ$ computes the Pareto front of the OneJumpZeroJump benchmark with gap size $k$ in an expected number of $O( (λ+μ)n + n^{k+1})$ function evaluations. This shows that the best runtime guarantee of $O(n^{k+1})$ is not only achieved for $μ= Θ(n)$ and $λ= O(n)$ but for arbitrary $μ, λ= O(n^k)$. Thus, choosing suitable parameters -- a key challenge in using heuristic algorithms -- is much easier for the SPEA2 than the NSGA-II.
Scalable Speed-ups for the SMS-EMOA from a Simple Aging Strategy
May 03, 2025Different from single-objective evolutionary algorithms, where non-elitism is an established concept, multi-objective evolutionary algorithms almost always select the next population in a greedy fashion. In the only notable exception, Bian, Zhou, Li, and Qian (IJCAI 2023) proposed a stochastic selection mechanism for the SMS-EMOA and proved that it can speed up computing the Pareto front of the bi-objective jump benchmark with problem size $n$ and gap parameter $k$ by a factor of $\max\{1,2^{k/4}/n\}$. While this constitutes the first proven speed-up from non-elitist selection, suggesting a very interesting research direction, it has to be noted that a true speed-up only occurs for $k \ge 4\log_2(n)$, where the runtime is super-polynomial, and that the advantage reduces for larger numbers of objectives as shown in a later work. In this work, we propose a different non-elitist selection mechanism based on aging, which exempts individuals younger than a certain age from a possible removal. This remedies the two shortcomings of stochastic selection: We prove a speed-up by a factor of $\max\{1,\Theta(k)^{k-1}\}$, regardless of the number of objectives. In particular, a positive speed-up can already be observed for constant $k$, the only setting for which polynomial runtimes can be witnessed. Overall, this result supports the use of non-elitist selection schemes, but suggests that aging-based mechanisms can be considerably more powerful than stochastic selection mechanisms.
Proven Approximation Guarantees in Multi-Objective Optimization: SPEA2 Beats NSGA-II
May 02, 2025Together with the NSGA-II and SMS-EMOA, the strength Pareto evolutionary algorithm 2 (SPEA2) is one of the most prominent dominance-based multi-objective evolutionary algorithms (MOEAs). Different from the NSGA-II, it does not employ the crowding distance (essentially the distance to neighboring solutions) to compare pairwise non-dominating solutions but a complex system of $\sigma$-distances that builds on the distances to all other solutions. In this work, we give a first mathematical proof showing that this more complex system of distances can be superior. More specifically, we prove that a simple steady-state SPEA2 can compute optimal approximations of the Pareto front of the OneMinMax benchmark in polynomial time. The best proven guarantee for a comparable variant of the NSGA-II only assures approximation ratios of roughly a factor of two, and both mathematical analyses and experiments indicate that optimal approximations are not found efficiently.
Tight Runtime Guarantees From Understanding the Population Dynamics of the GSEMO Multi-Objective Evolutionary Algorithm
May 02, 2025The global simple evolutionary multi-objective optimizer (GSEMO) is a simple, yet often effective multi-objective evolutionary algorithm (MOEA). By only maintaining non-dominated solutions, it has a variable population size that automatically adjusts to the needs of the optimization process. The downside of the dynamic population size is that the population dynamics of this algorithm are harder to understand, resulting, e.g., in the fact that only sporadic tight runtime analyses exist. In this work, we significantly enhance our understanding of the dynamics of the GSEMO, in particular, for the classic CountingOnesCountingZeros (COCZ) benchmark. From this, we prove a lower bound of order $\Omega(n^2 \log n)$, for the first time matching the seminal upper bounds known for over twenty years. We also show that the GSEMO finds any constant fraction of the Pareto front in time $O(n^2)$, improving over the previous estimate of $O(n^2 \log n)$ for the time to find the first Pareto optimum. Our methods extend to other classic benchmarks and yield, e.g., the first $\Omega(n^{k+1})$ lower bound for the OJZJ benchmark in the case that the gap parameter is $k \in \{2,3\}$. We are therefore optimistic that our new methods will be useful in future mathematical analyses of MOEAs.
The First Theoretical Approximation Guarantees for the Non-Dominated Sorting Genetic Algorithm III (NSGA-III)
Apr 30, 2025

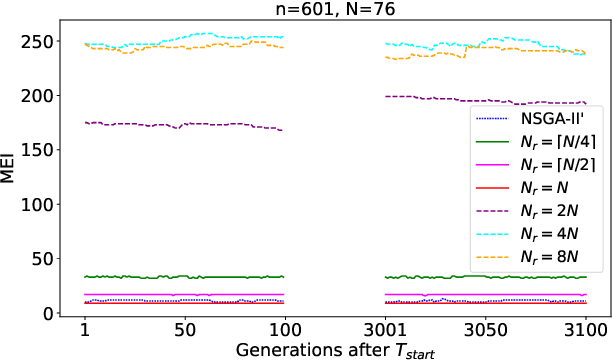

This work conducts a first theoretical analysis studying how well the NSGA-III approximates the Pareto front when the population size $N$ is less than the Pareto front size. We show that when $N$ is at least the number $N_r$ of reference points, then the approximation quality, measured by the maximum empty interval (MEI) indicator, on the OneMinMax benchmark is such that there is no empty interval longer than $\lceil\frac{(5-2\sqrt2)n}{N_r-1}\rceil$. This bound is independent of $N$, which suggests that further increasing the population size does not increase the quality of approximation when $N_r$ is fixed. This is a notable difference to the NSGA-II with sequential survival selection, where increasing the population size improves the quality of the approximations. We also prove two results indicating approximation difficulties when $N<N_r$. These theoretical results suggest that the best setting to approximate the Pareto front is $N_r=N$. In our experiments, we observe that with this setting the NSGA-III computes optimal approximations, very different from the NSGA-II, for which optimal approximations have not been observed so far.
Runtime Analysis of the Compact Genetic Algorithm on the LeadingOnes Benchmark
Jan 27, 2025The compact genetic algorithm (cGA) is one of the simplest estimation-of-distribution algorithms (EDAs). Next to the univariate marginal distribution algorithm (UMDA) -- another simple EDA -- , the cGA has been subject to extensive mathematical runtime analyses, often showcasing a similar or even superior performance to competing approaches. Surprisingly though, up to date and in contrast to the UMDA and many other heuristics, we lack a rigorous runtime analysis of the cGA on the LeadingOnes benchmark -- one of the most studied theory benchmarks in the domain of evolutionary computation. We fill this gap in the literature by conducting a formal runtime analysis of the cGA on LeadingOnes. For the cGA's single parameter -- called the hypothetical population size -- at least polylogarithmically larger than the problem size, we prove that the cGA samples the optimum of LeadingOnes with high probability within a number of function evaluations quasi-linear in the problem size and linear in the hypothetical population size. For the best hypothetical population size, our result matches, up to polylogarithmic factors, the typical quadratic runtime that many randomized search heuristics exhibit on LeadingOnes. Our analysis exhibits some noteworthy differences in the working principles of the two algorithms which were not visible in previous works.
Speeding Up the NSGA-II With a Simple Tie-Breaking Rule
Dec 17, 2024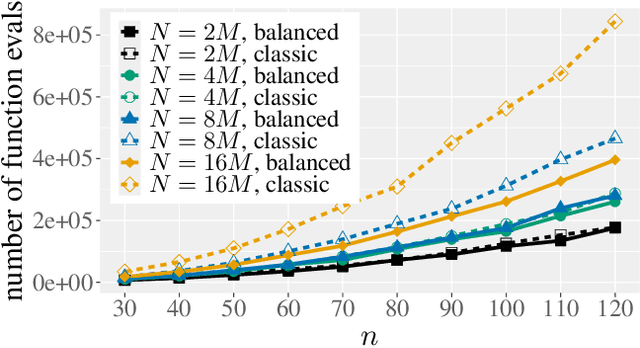
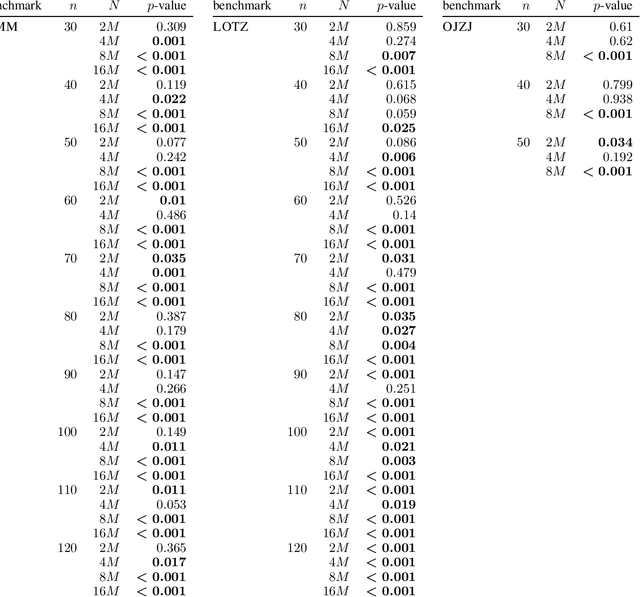
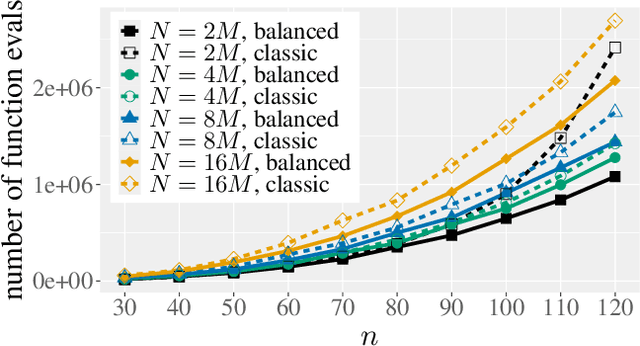
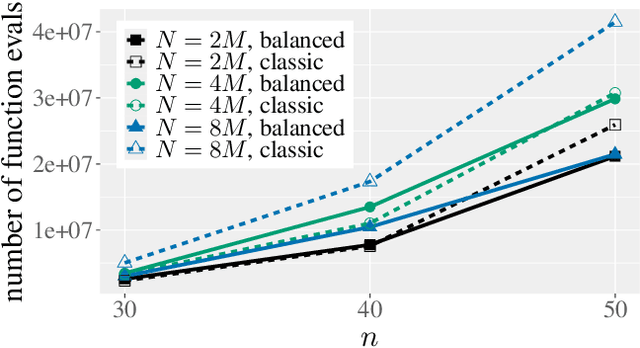
The non-dominated sorting genetic algorithm~II (NSGA-II) is the most popular multi-objective optimization heuristic. Recent mathematical runtime analyses have detected two shortcomings in discrete search spaces, namely, that the NSGA-II has difficulties with more than two objectives and that it is very sensitive to the choice of the population size. To overcome these difficulties, we analyze a simple tie-breaking rule in the selection of the next population. Similar rules have been proposed before, but have found only little acceptance. We prove the effectiveness of our tie-breaking rule via mathematical runtime analyses on the classic OneMinMax, LeadingOnesTrailingZeros, and OneJumpZeroJump benchmarks. We prove that this modified NSGA-II can optimize the three benchmarks efficiently also for many objectives, in contrast to the exponential lower runtime bound previously shown for OneMinMax with three or more objectives. For the bi-objective problems, we show runtime guarantees that do not increase when moderately increasing the population size over the minimum admissible size. For example, for the OneJumpZeroJump problem with representation length $n$ and gap parameter $k$, we show a runtime guarantee of $O(\max\{n^{k+1},Nn\})$ function evaluations when the population size is at least four times the size of the Pareto front. For population sizes larger than the minimal choice $N = \Theta(n)$, this result improves considerably over the $\Theta(Nn^k)$ runtime of the classic NSGA-II.
Runtime Analysis for Multi-Objective Evolutionary Algorithms in Unbounded Integer Spaces
Dec 17, 2024



Randomized search heuristics have been applied successfully to a plethora of problems. This success is complemented by a large body of theoretical results. Unfortunately, the vast majority of these results regard problems with binary or continuous decision variables -- the theoretical analysis of randomized search heuristics for unbounded integer domains is almost nonexistent. To resolve this shortcoming, we start the runtime analysis of multi-objective evolutionary algorithms, which are among the most successful randomized search heuristics, for unbounded integer search spaces. We analyze single- and full-dimensional mutation operators with three different mutation strengths, namely changes by plus/minus one (unit strength), random changes following a law with exponential tails, and random changes following a power-law. The performance guarantees we prove on a recently proposed natural benchmark problem suggest that unit mutation strengths can be slow when the initial solutions are far from the Pareto front. When setting the expected change right (depending on the benchmark parameter and the distance of the initial solutions), the mutation strength with exponential tails yields the best runtime guarantees in our results -- however, with a wrong choice of this expectation, the performance guarantees quickly become highly uninteresting. With power-law mutation, which is an essentially parameter-less mutation operator, we obtain good results uniformly over all problem parameters and starting points. We complement our mathematical findings with experimental results that suggest that our bounds are not always tight. Most prominently, our experiments indicate that power-law mutation outperforms the one with exponential tails even when the latter uses a near-optimal parametrization. Hence, we suggest to favor power-law mutation for unknown problems in integer spaces.
Difficulties of the NSGA-II with the Many-Objective LeadingOnes Problem
Nov 15, 2024



The NSGA-II is the most prominent multi-objective evolutionary algorithm (cited more than 50,000 times). Very recently, a mathematical runtime analysis has proven that this algorithm can have enormous difficulties when the number of objectives is larger than two (Zheng, Doerr. IEEE Transactions on Evolutionary Computation (2024)). However, this result was shown only for the OneMinMax benchmark problem, which has the particularity that all solutions are on the Pareto front, a fact heavily exploited in the proof of this result. In this work, we show a comparable result for the LeadingOnesTrailingZeroes benchmark. This popular benchmark problem appears more natural in that most of its solutions are not on the Pareto front. With a careful analysis of the population dynamics of the NGSA-II optimizing this benchmark, we manage to show that when the population grows on the Pareto front, then it does so much faster by creating known Pareto optima than by spreading out on the Pareto front. Consequently, already when still a constant fraction of the Pareto front is unexplored, the crowding distance becomes the crucial selection mechanism, and thus the same problems arise as in the optimization of OneMinMax. With these and some further arguments, we show that the NSGA-II, with a population size by at most a constant factor larger than the Pareto front, cannot compute the Pareto front in less than exponential time.