 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbnormal Mutations: Evolution Strategies Don't Require Gaussianity
Feb 05, 2025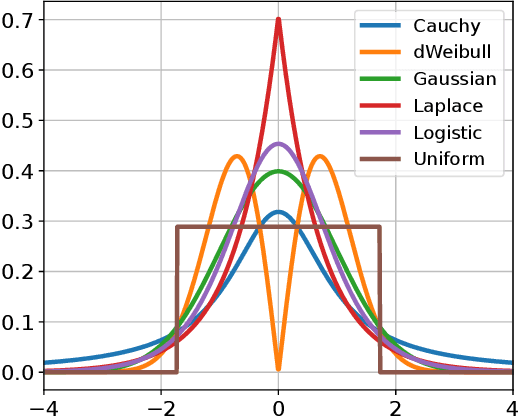

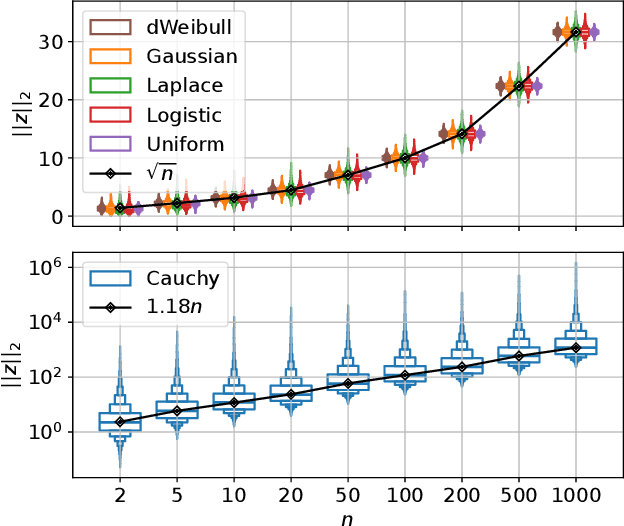

The mutation process in evolution strategies has been interlinked with the normal distribution since its inception. Many lines of reasoning have been given for this strong dependency, ranging from maximum entropy arguments to the need for isotropy. However, some theoretical results suggest that other distributions might lead to similar local convergence properties. This paper empirically shows that a wide range of evolutionary strategies, from the (1+1)-ES to CMA-ES, show comparable optimization performance when using a mutation distribution other than the standard Gaussian. Replacing it with, e.g., uniformly distributed mutations, does not deteriorate the performance of ES, when using the default adaptation mechanism for the strategy parameters. We observe that these results hold not only for the sphere model but also for a wider range of benchmark problems.
Runtime Analysis for Multi-Objective Evolutionary Algorithms in Unbounded Integer Spaces
Dec 17, 2024



Randomized search heuristics have been applied successfully to a plethora of problems. This success is complemented by a large body of theoretical results. Unfortunately, the vast majority of these results regard problems with binary or continuous decision variables -- the theoretical analysis of randomized search heuristics for unbounded integer domains is almost nonexistent. To resolve this shortcoming, we start the runtime analysis of multi-objective evolutionary algorithms, which are among the most successful randomized search heuristics, for unbounded integer search spaces. We analyze single- and full-dimensional mutation operators with three different mutation strengths, namely changes by plus/minus one (unit strength), random changes following a law with exponential tails, and random changes following a power-law. The performance guarantees we prove on a recently proposed natural benchmark problem suggest that unit mutation strengths can be slow when the initial solutions are far from the Pareto front. When setting the expected change right (depending on the benchmark parameter and the distance of the initial solutions), the mutation strength with exponential tails yields the best runtime guarantees in our results -- however, with a wrong choice of this expectation, the performance guarantees quickly become highly uninteresting. With power-law mutation, which is an essentially parameter-less mutation operator, we obtain good results uniformly over all problem parameters and starting points. We complement our mathematical findings with experimental results that suggest that our bounds are not always tight. Most prominently, our experiments indicate that power-law mutation outperforms the one with exponential tails even when the latter uses a near-optimal parametrization. Hence, we suggest to favor power-law mutation for unknown problems in integer spaces.
Archive-based Single-Objective Evolutionary Algorithms for Submodular Optimization
Jun 19, 2024

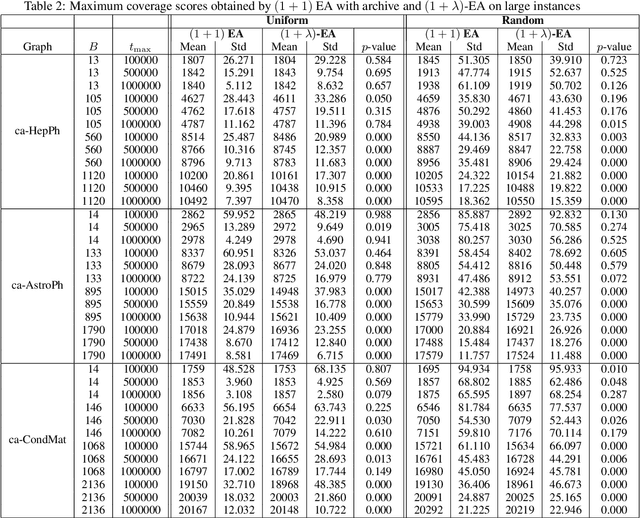
Constrained submodular optimization problems play a key role in the area of combinatorial optimization as they capture many NP-hard optimization problems. So far, Pareto optimization approaches using multi-objective formulations have been shown to be successful to tackle these problems while single-objective formulations lead to difficulties for algorithms such as the $(1+1)$-EA due to the presence of local optima. We introduce for the first time single-objective algorithms that are provably successful for different classes of constrained submodular maximization problems. Our algorithms are variants of the $(1+\lambda)$-EA and $(1+1)$-EA and increase the feasible region of the search space incrementally in order to deal with the considered submodular problems.
Towards Decision Support in Dynamic Bi-Objective Vehicle Routing
May 28, 2020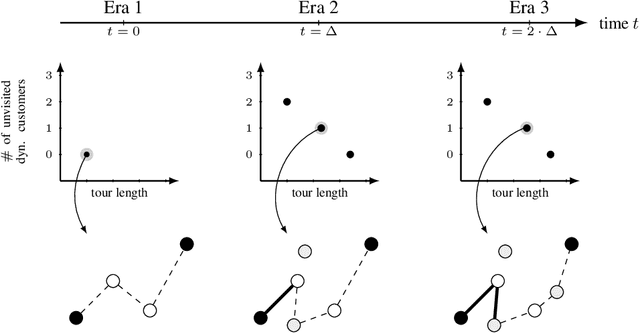

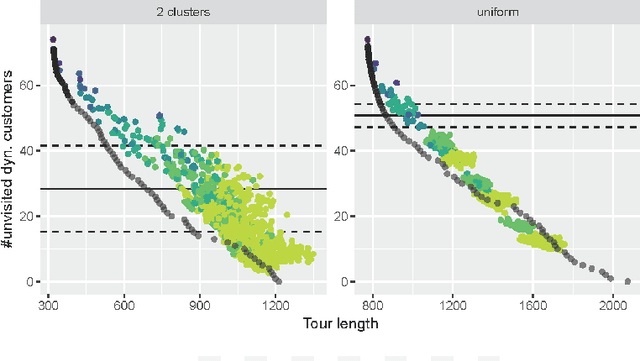
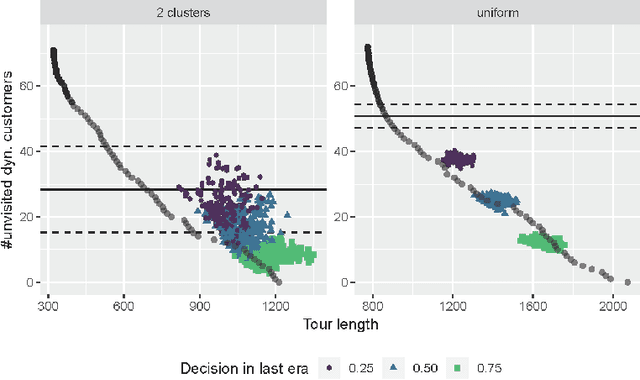
We consider a dynamic bi-objective vehicle routing problem, where a subset of customers ask for service over time. Therein, the distance traveled by a single vehicle and the number of unserved dynamic requests is minimized by a dynamic evolutionary multi-objective algorithm (DEMOA), which operates on discrete time windows (eras). A decision is made at each era by a decision-maker, thus any decision depends on irreversible decisions made in foregoing eras. To understand effects of sequences of decision-making and interactions/dependencies between decisions made, we conduct a series of experiments. More precisely, we fix a set of decision-maker preferences $D$ and the number of eras $n_t$ and analyze all $|D|^{n_t}$ combinations of decision-maker options. We find that for random uniform instances (a) the final selected solutions mainly depend on the final decision and not on the decision history, (b) solutions are quite robust with respect to the number of unvisited dynamic customers, and (c) solutions of the dynamic approach can even dominate solutions obtained by a clairvoyant EMOA. In contrast, for instances with clustered customers, we observe a strong dependency on decision-making history as well as more variance in solution diversity.
An Empirical Approach For Probing the Definiteness of Kernels
Jul 10, 2018

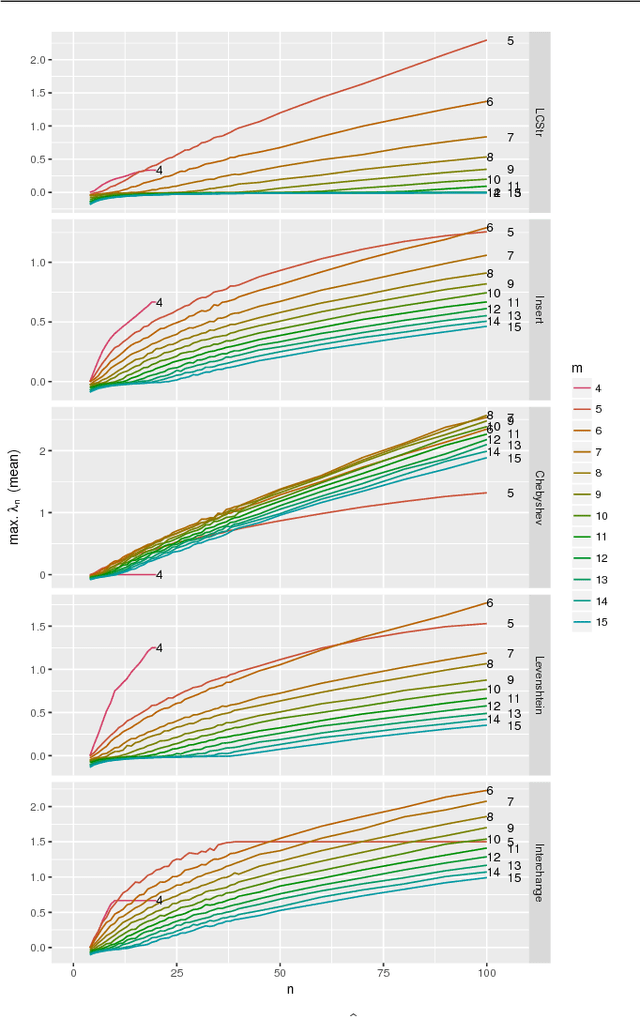
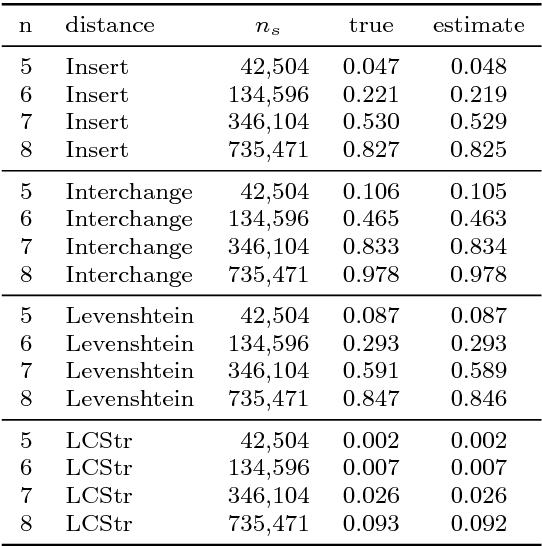
Models like support vector machines or Gaussian process regression often require positive semi-definite kernels. These kernels may be based on distance functions. While definiteness is proven for common distances and kernels, a proof for a new kernel may require too much time and effort for users who simply aim at practical usage. Furthermore, designing definite distances or kernels may be equally intricate. Finally, models can be enabled to use indefinite kernels. This may deteriorate the accuracy or computational cost of the model. Hence, an efficient method to determine definiteness is required. We propose an empirical approach. We show that sampling as well as optimization with an evolutionary algorithm may be employed to determine definiteness. We provide a proof-of-concept with 16 different distance measures for permutations. Our approach allows to disprove definiteness if a respective counter-example is found. It can also provide an estimate of how likely it is to obtain indefinite kernel matrices. This provides a simple, efficient tool to decide whether additional effort should be spent on designing/selecting a more suitable kernel or algorithm.
Surrogate-Assisted Partial Order-based Evolutionary Optimisation
Nov 01, 2016
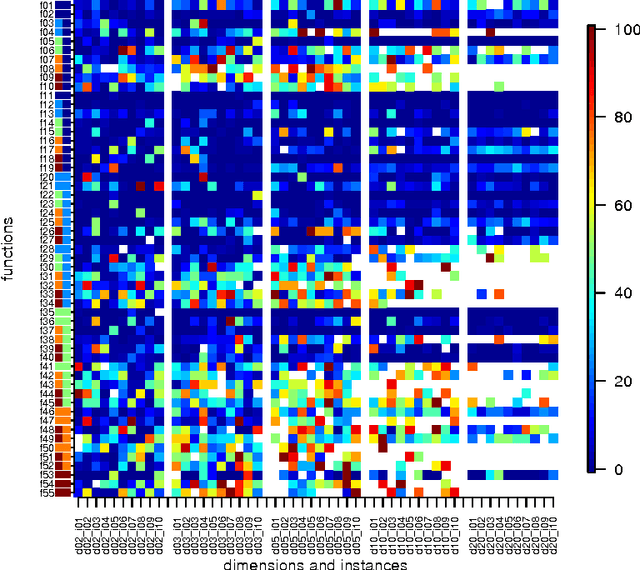
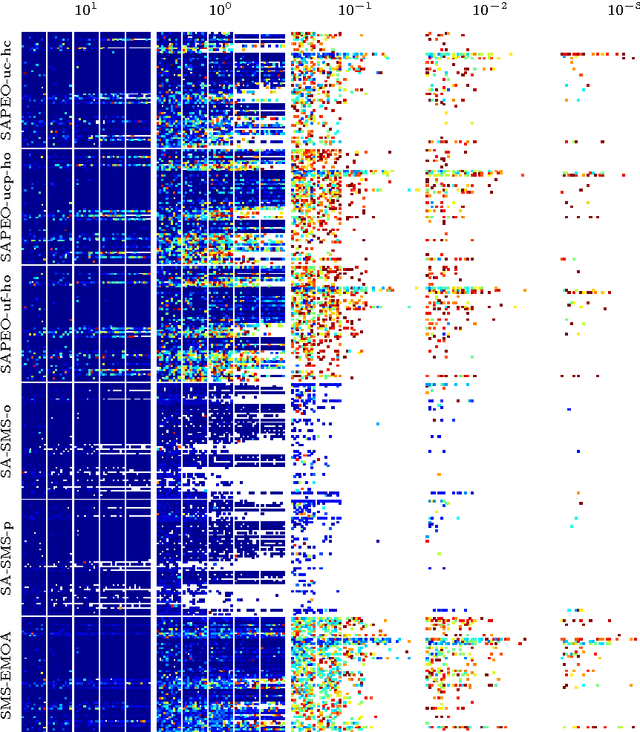
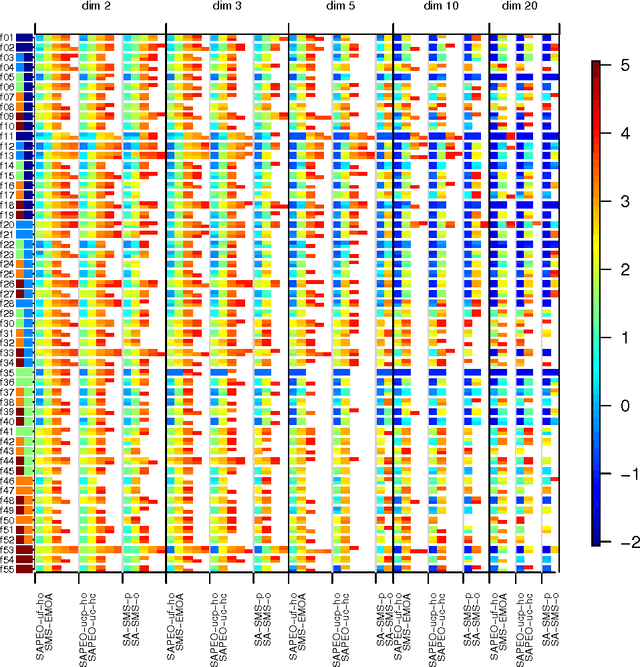
In this paper, we propose a novel approach (SAPEO) to support the survival selection process in multi-objective evolutionary algorithms with surrogate models - it dynamically chooses individuals to evaluate exactly based on the model uncertainty and the distinctness of the population. We introduce variants that differ in terms of the risk they allow when doing survival selection. Here, the anytime performance of different SAPEO variants is evaluated in conjunction with an SMS-EMOA using the BBOB bi-objective benchmark. We compare the obtained results with the performance of the regular SMS-EMOA, as well as another surrogate-assisted approach. The results open up general questions about the applicability and required conditions for surrogate-assisted multi-objective evolutionary algorithms to be tackled in the future.
Demonstrating the Feasibility of Automatic Game Balancing
Mar 11, 2016

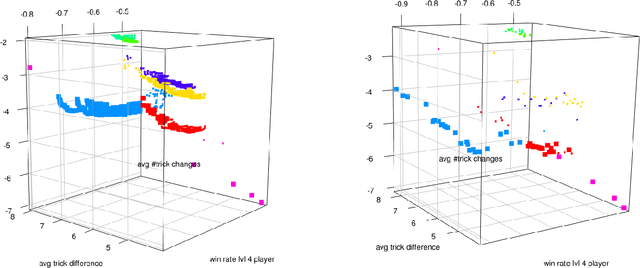
Game balancing is an important part of the (computer) game design process, in which designers adapt a game prototype so that the resulting gameplay is as entertaining as possible. In industry, the evaluation of a game is often based on costly playtests with human players. It suggests itself to automate this process using surrogate models for the prediction of gameplay and outcome. In this paper, the feasibility of automatic balancing using simulation- and deck-based objectives is investigated for the card game top trumps. Additionally, the necessity of a multi-objective approach is asserted by a comparison with the only known (single-objective) method. We apply a multi-objective evolutionary algorithm to obtain decks that optimise objectives, e.g. win rate and average number of tricks, developed to express the fairness and the excitement of a game of top trumps. The results are compared with decks from published top trumps decks using simulation-based objectives. The possibility to generate decks better or at least as good as decks from published top trumps decks in terms of these objectives is demonstrated. Our results indicate that automatic balancing with the presented approach is feasible even for more complex games such as real-time strategy games.
Averaged Hausdorff Approximations of Pareto Fronts based on Multiobjective Estimation of Distribution Algorithms
Mar 26, 2015

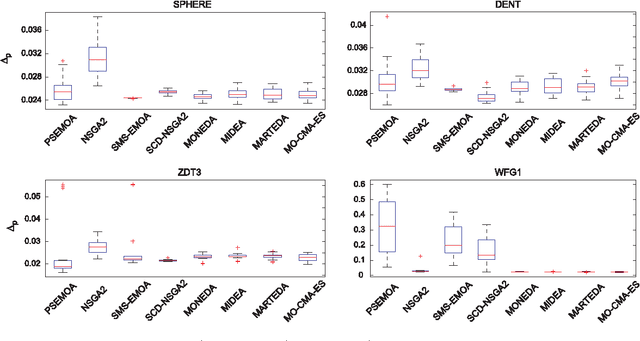

In the a posteriori approach of multiobjective optimization the Pareto front is approximated by a finite set of solutions in the objective space. The quality of the approximation can be measured by different indicators that take into account the approximation's closeness to the Pareto front and its distribution along the Pareto front. In particular, the averaged Hausdorff indicator prefers an almost uniform distribution. An observed drawback of multiobjective estimation of distribution algorithms (MEDAs) is that - as common for randomized metaheuristics - the final population usually is not uniformly distributed along the Pareto front. Therefore, we propose a postprocessing strategy which consists of applying the averaged Hausdorff indicator to the complete archive of generated solutions after optimization in order to select a uniformly distributed subset of nondominated solutions from the archive. In this paper, we put forward a strategy for extracting the above described subset. The effectiveness of the proposal is contrasted in a series of experiments that involve different MEDAs and filtering techniques.