 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Runtime Guarantees for the SPEA2 Multi-Objective Optimizer
Nov 10, 2025Together with the NSGA-II, the SPEA2 is one of the most widely used domination-based multi-objective evolutionary algorithms. For both algorithms, the known runtime guarantees are linear in the population size; for the NSGA-II, matching lower bounds exist. With a careful study of the more complex selection mechanism of the SPEA2, we show that it has very different population dynamics. From these, we prove runtime guarantees for the OneMinMax, LeadingOnesTrailingZeros, and OneJumpZeroJump benchmarks that depend less on the population size. For example, we show that the SPEA2 with parent population size $μ\ge n - 2k + 3$ and offspring population size $λ$ computes the Pareto front of the OneJumpZeroJump benchmark with gap size $k$ in an expected number of $O( (λ+μ)n + n^{k+1})$ function evaluations. This shows that the best runtime guarantee of $O(n^{k+1})$ is not only achieved for $μ= Θ(n)$ and $λ= O(n)$ but for arbitrary $μ, λ= O(n^k)$. Thus, choosing suitable parameters -- a key challenge in using heuristic algorithms -- is much easier for the SPEA2 than the NSGA-II.
Proven Approximation Guarantees in Multi-Objective Optimization: SPEA2 Beats NSGA-II
May 02, 2025Together with the NSGA-II and SMS-EMOA, the strength Pareto evolutionary algorithm 2 (SPEA2) is one of the most prominent dominance-based multi-objective evolutionary algorithms (MOEAs). Different from the NSGA-II, it does not employ the crowding distance (essentially the distance to neighboring solutions) to compare pairwise non-dominating solutions but a complex system of $\sigma$-distances that builds on the distances to all other solutions. In this work, we give a first mathematical proof showing that this more complex system of distances can be superior. More specifically, we prove that a simple steady-state SPEA2 can compute optimal approximations of the Pareto front of the OneMinMax benchmark in polynomial time. The best proven guarantee for a comparable variant of the NSGA-II only assures approximation ratios of roughly a factor of two, and both mathematical analyses and experiments indicate that optimal approximations are not found efficiently.
Runtime Analysis of the Compact Genetic Algorithm on the LeadingOnes Benchmark
Jan 27, 2025The compact genetic algorithm (cGA) is one of the simplest estimation-of-distribution algorithms (EDAs). Next to the univariate marginal distribution algorithm (UMDA) -- another simple EDA -- , the cGA has been subject to extensive mathematical runtime analyses, often showcasing a similar or even superior performance to competing approaches. Surprisingly though, up to date and in contrast to the UMDA and many other heuristics, we lack a rigorous runtime analysis of the cGA on the LeadingOnes benchmark -- one of the most studied theory benchmarks in the domain of evolutionary computation. We fill this gap in the literature by conducting a formal runtime analysis of the cGA on LeadingOnes. For the cGA's single parameter -- called the hypothetical population size -- at least polylogarithmically larger than the problem size, we prove that the cGA samples the optimum of LeadingOnes with high probability within a number of function evaluations quasi-linear in the problem size and linear in the hypothetical population size. For the best hypothetical population size, our result matches, up to polylogarithmic factors, the typical quadratic runtime that many randomized search heuristics exhibit on LeadingOnes. Our analysis exhibits some noteworthy differences in the working principles of the two algorithms which were not visible in previous works.
Speeding Up the NSGA-II With a Simple Tie-Breaking Rule
Dec 17, 2024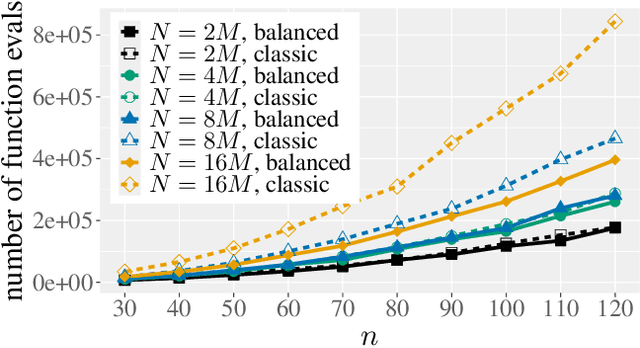
The non-dominated sorting genetic algorithm~II (NSGA-II) is the most popular multi-objective optimization heuristic. Recent mathematical runtime analyses have detected two shortcomings in discrete search spaces, namely, that the NSGA-II has difficulties with more than two objectives and that it is very sensitive to the choice of the population size. To overcome these difficulties, we analyze a simple tie-breaking rule in the selection of the next population. Similar rules have been proposed before, but have found only little acceptance. We prove the effectiveness of our tie-breaking rule via mathematical runtime analyses on the classic OneMinMax, LeadingOnesTrailingZeros, and OneJumpZeroJump benchmarks. We prove that this modified NSGA-II can optimize the three benchmarks efficiently also for many objectives, in contrast to the exponential lower runtime bound previously shown for OneMinMax with three or more objectives. For the bi-objective problems, we show runtime guarantees that do not increase when moderately increasing the population size over the minimum admissible size. For example, for the OneJumpZeroJump problem with representation length $n$ and gap parameter $k$, we show a runtime guarantee of $O(\max\{n^{k+1},Nn\})$ function evaluations when the population size is at least four times the size of the Pareto front. For population sizes larger than the minimal choice $N = \Theta(n)$, this result improves considerably over the $\Theta(Nn^k)$ runtime of the classic NSGA-II.
Runtime Analysis for Multi-Objective Evolutionary Algorithms in Unbounded Integer Spaces
Dec 17, 2024



Randomized search heuristics have been applied successfully to a plethora of problems. This success is complemented by a large body of theoretical results. Unfortunately, the vast majority of these results regard problems with binary or continuous decision variables -- the theoretical analysis of randomized search heuristics for unbounded integer domains is almost nonexistent. To resolve this shortcoming, we start the runtime analysis of multi-objective evolutionary algorithms, which are among the most successful randomized search heuristics, for unbounded integer search spaces. We analyze single- and full-dimensional mutation operators with three different mutation strengths, namely changes by plus/minus one (unit strength), random changes following a law with exponential tails, and random changes following a power-law. The performance guarantees we prove on a recently proposed natural benchmark problem suggest that unit mutation strengths can be slow when the initial solutions are far from the Pareto front. When setting the expected change right (depending on the benchmark parameter and the distance of the initial solutions), the mutation strength with exponential tails yields the best runtime guarantees in our results -- however, with a wrong choice of this expectation, the performance guarantees quickly become highly uninteresting. With power-law mutation, which is an essentially parameter-less mutation operator, we obtain good results uniformly over all problem parameters and starting points. We complement our mathematical findings with experimental results that suggest that our bounds are not always tight. Most prominently, our experiments indicate that power-law mutation outperforms the one with exponential tails even when the latter uses a near-optimal parametrization. Hence, we suggest to favor power-law mutation for unknown problems in integer spaces.
Difficulties of the NSGA-II with the Many-Objective LeadingOnes Problem
Nov 15, 2024



The NSGA-II is the most prominent multi-objective evolutionary algorithm (cited more than 50,000 times). Very recently, a mathematical runtime analysis has proven that this algorithm can have enormous difficulties when the number of objectives is larger than two (Zheng, Doerr. IEEE Transactions on Evolutionary Computation (2024)). However, this result was shown only for the OneMinMax benchmark problem, which has the particularity that all solutions are on the Pareto front, a fact heavily exploited in the proof of this result. In this work, we show a comparable result for the LeadingOnesTrailingZeroes benchmark. This popular benchmark problem appears more natural in that most of its solutions are not on the Pareto front. With a careful analysis of the population dynamics of the NGSA-II optimizing this benchmark, we manage to show that when the population grows on the Pareto front, then it does so much faster by creating known Pareto optima than by spreading out on the Pareto front. Consequently, already when still a constant fraction of the Pareto front is unexplored, the crowding distance becomes the crucial selection mechanism, and thus the same problems arise as in the optimization of OneMinMax. With these and some further arguments, we show that the NSGA-II, with a population size by at most a constant factor larger than the Pareto front, cannot compute the Pareto front in less than exponential time.
Proven Runtime Guarantees for How the \moead Computes the Pareto Front From the Subproblem Solutions
May 02, 2024The decomposition-based multi-objective evolutionary algorithm (MOEA/D) does not directly optimize a given multi-objective function $f$, but instead optimizes $N + 1$ single-objective subproblems of $f$ in a co-evolutionary manner. It maintains an archive of all non-dominated solutions found and outputs it as approximation to the Pareto front. Once the MOEA/D found all optima of the subproblems (the $g$-optima), it may still miss Pareto optima of $f$. The algorithm is then tasked to find the remaining Pareto optima directly by mutating the $g$-optima. In this work, we analyze for the first time how the MOEA/D with only standard mutation operators computes the whole Pareto front of the OneMinMax benchmark when the $g$-optima are a strict subset of the Pareto front. For standard bit mutation, we prove an expected runtime of $O(n N \log n + n^{n/(2N)} N \log n)$ function evaluations. Especially for the second, more interesting phase when the algorithm start with all $g$-optima, we prove an $\Omega(n^{(1/2)(n/N + 1)} \sqrt{N} 2^{-n/N})$ expected runtime. This runtime is super-polynomial if $N = o(n)$, since this leaves large gaps between the $g$-optima, which require costly mutations to cover. For power-law mutation with exponent $\beta \in (1, 2)$, we prove an expected runtime of $O\left(n N \log n + n^{\beta} \log n\right)$ function evaluations. The $O\left(n^{\beta} \log n\right)$ term stems from the second phase of starting with all $g$-optima, and it is independent of the number of subproblems $N$. This leads to a huge speedup compared to the lower bound for standard bit mutation. In general, our overall bound for power-law suggests that the MOEA/D performs best for $N = O(n^{\beta - 1})$, resulting in an $O(n^\beta \log n)$ bound. In contrast to standard bit mutation, smaller values of $N$ are better for power-law mutation, as it is capable of easily creating missing solutions.
A Flexible Evolutionary Algorithm With Dynamic Mutation Rate Archive
Apr 05, 2024We propose a new, flexible approach for dynamically maintaining successful mutation rates in evolutionary algorithms using $k$-bit flip mutations. The algorithm adds successful mutation rates to an archive of promising rates that are favored in subsequent steps. Rates expire when their number of unsuccessful trials has exceeded a threshold, while rates currently not present in the archive can enter it in two ways: (i) via user-defined minimum selection probabilities for rates combined with a successful step or (ii) via a stagnation detection mechanism increasing the value for a promising rate after the current bit-flip neighborhood has been explored with high probability. For the minimum selection probabilities, we suggest different options, including heavy-tailed distributions. We conduct rigorous runtime analysis of the flexible evolutionary algorithm on the OneMax and Jump functions, on general unimodal functions, on minimum spanning trees, and on a class of hurdle-like functions with varying hurdle width that benefit particularly from the archive of promising mutation rates. In all cases, the runtime bounds are close to or even outperform the best known results for both stagnation detection and heavy-tailed mutations.
Superior Genetic Algorithms for the Target Set Selection Problem Based on Power-Law Parameter Choices and Simple Greedy Heuristics
Apr 05, 2024



The target set selection problem (TSS) asks for a set of vertices such that an influence spreading process started in these vertices reaches the whole graph. The current state of the art for this NP-hard problem are three recently proposed randomized search heuristics, namely a biased random-key genetic algorithm (BRKGA) obtained from extensive parameter tuning, a max-min ant system (MMAS), and a MMAS using Q-learning with a graph convolutional network. We show that the BRKGA with two simple modifications and without the costly parameter tuning obtains significantly better results. Our first modification is to simply choose all parameters of the BRKGA in each iteration randomly from a power-law distribution. The resulting parameterless BRKGA is already competitive with the tuned BRKGA, as our experiments on the previously used benchmarks show. We then add a natural greedy heuristic, namely to repeatedly discard small-degree vertices that are not necessary for reaching the whole graph. The resulting algorithm consistently outperforms all of the state-of-the-art algorithms. Besides providing a superior algorithm for the TSS problem, this work shows that randomized parameter choices and elementary greedy heuristics can give better results than complex algorithms and costly parameter tuning.
Bivariate Estimation-of-Distribution Algorithms Can Find an Exponential Number of Optima
Oct 06, 2023


Finding a large set of optima in a multimodal optimization landscape is a challenging task. Classical population-based evolutionary algorithms typically converge only to a single solution. While this can be counteracted by applying niching strategies, the number of optima is nonetheless trivially bounded by the population size. Estimation-of-distribution algorithms (EDAs) are an alternative, maintaining a probabilistic model of the solution space instead of a population. Such a model is able to implicitly represent a solution set far larger than any realistic population size. To support the study of how optimization algorithms handle large sets of optima, we propose the test function EqualBlocksOneMax (EBOM). It has an easy fitness landscape with exponentially many optima. We show that the bivariate EDA mutual-information-maximizing input clustering, without any problem-specific modification, quickly generates a model that behaves very similarly to a theoretically ideal model for EBOM, which samples each of the exponentially many optima with the same maximal probability. We also prove via mathematical means that no univariate model can come close to having this property: If the probability to sample an optimum is at least inverse-polynomial, there is a Hamming ball of logarithmic radius such that, with high probability, each sample is in this ball.