 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe First AI4TSP Competition: Learning to Solve Stochastic Routing Problems
Jan 25, 2022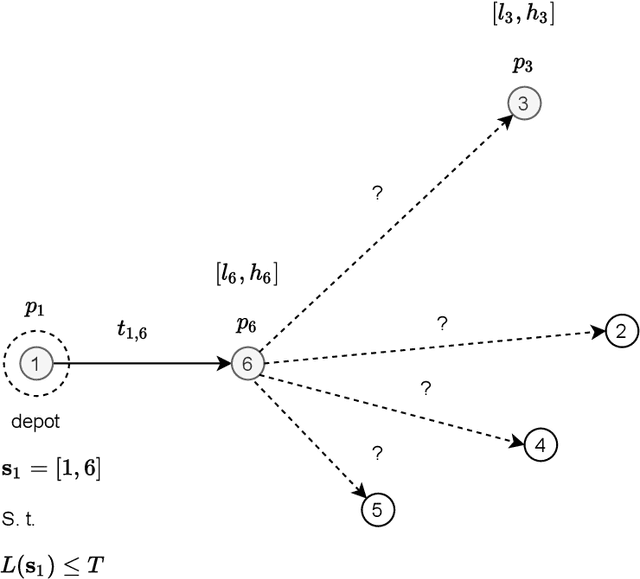
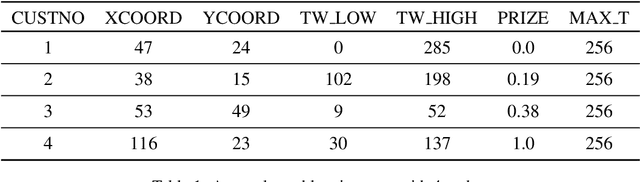

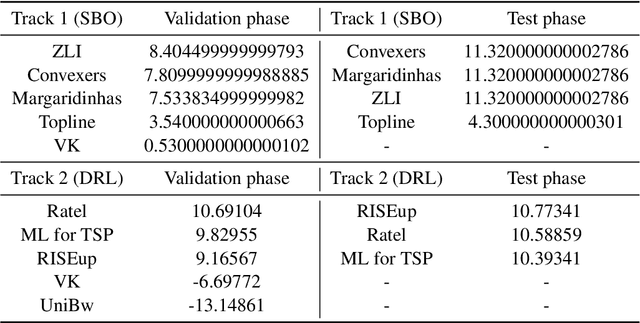
This paper reports on the first international competition on AI for the traveling salesman problem (TSP) at the International Joint Conference on Artificial Intelligence 2021 (IJCAI-21). The TSP is one of the classical combinatorial optimization problems, with many variants inspired by real-world applications. This first competition asked the participants to develop algorithms to solve a time-dependent orienteering problem with stochastic weights and time windows (TD-OPSWTW). It focused on two types of learning approaches: surrogate-based optimization and deep reinforcement learning. In this paper, we describe the problem, the setup of the competition, the winning methods, and give an overview of the results. The winning methods described in this work have advanced the state-of-the-art in using AI for stochastic routing problems. Overall, by organizing this competition we have introduced routing problems as an interesting problem setting for AI researchers. The simulator of the problem has been made open-source and can be used by other researchers as a benchmark for new AI methods.
Underwater Acoustic Networks for Security Risk Assessment in Public Drinking Water Reservoirs
Jul 29, 2021


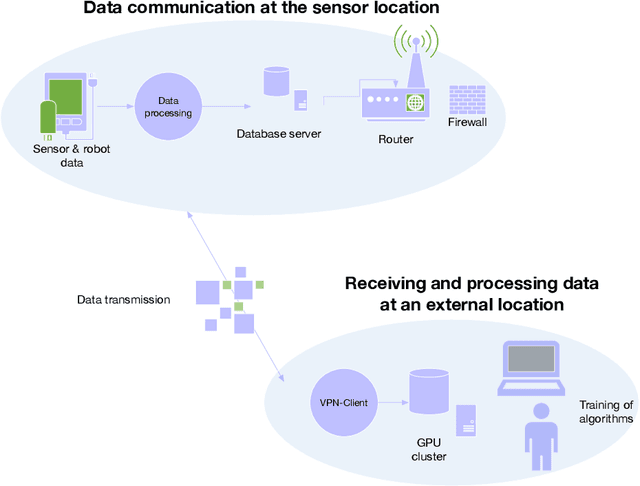
We have built a novel system for the surveillance of drinking water reservoirs using underwater sensor networks. We implement an innovative AI-based approach to detect, classify and localize underwater events. In this paper, we describe the technology and cognitive AI architecture of the system based on one of the sensor networks, the hydrophone network. We discuss the challenges of installing and using the hydrophone network in a water reservoir where traffic, visitors, and variable water conditions create a complex, varying environment. Our AI solution uses an autoencoder for unsupervised learning of latent encodings for classification and anomaly detection, and time delay estimates for sound localization. Finally, we present the results of experiments carried out in a laboratory pool and the water reservoir and discuss the system's potential.
Experimental Investigation and Evaluation of Model-based Hyperparameter Optimization
Jul 19, 2021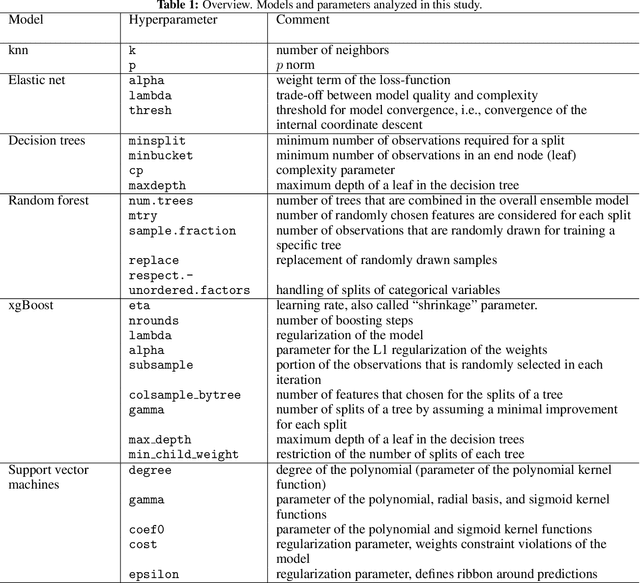
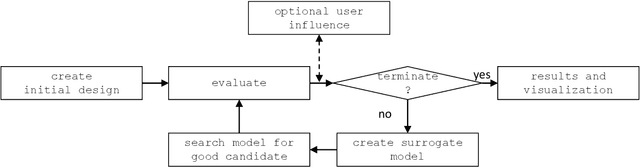

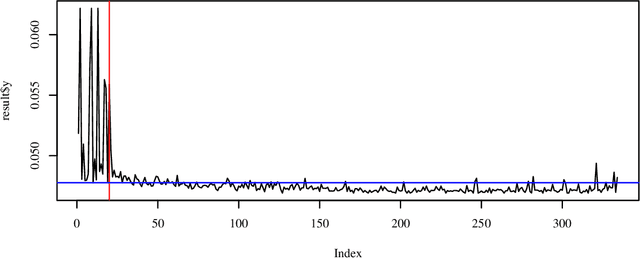
Machine learning algorithms such as random forests or xgboost are gaining more importance and are increasingly incorporated into production processes in order to enable comprehensive digitization and, if possible, automation of processes. Hyperparameters of these algorithms used have to be set appropriately, which can be referred to as hyperparameter tuning or optimization. Based on the concept of tunability, this article presents an overview of theoretical and practical results for popular machine learning algorithms. This overview is accompanied by an experimental analysis of 30 hyperparameters from six relevant machine learning algorithms. In particular, it provides (i) a survey of important hyperparameters, (ii) two parameter tuning studies, and (iii) one extensive global parameter tuning study, as well as (iv) a new way, based on consensus ranking, to analyze results from multiple algorithms. The R package mlr is used as a uniform interface to the machine learning models. The R package SPOT is used to perform the actual tuning (optimization). All additional code is provided together with this paper.
Behavior-based Neuroevolutionary Training in Reinforcement Learning
May 17, 2021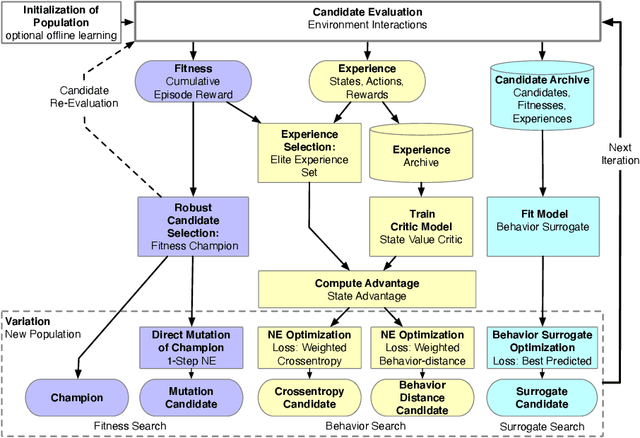
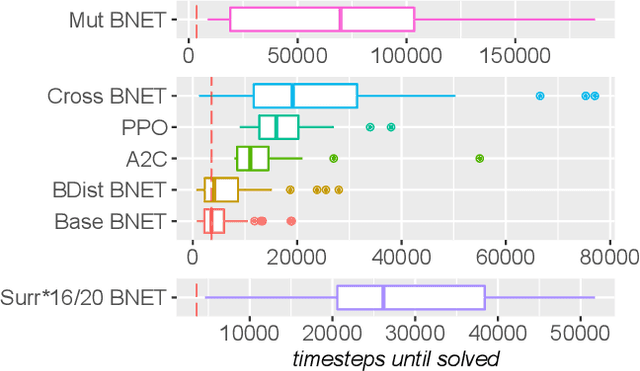
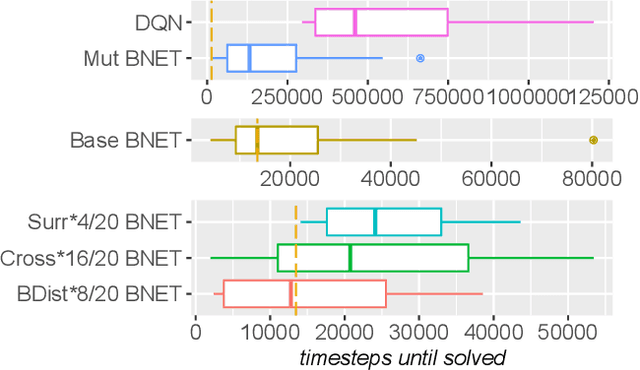
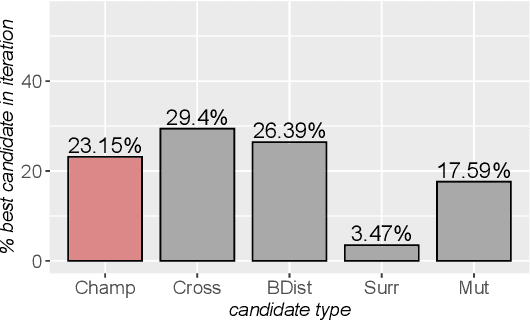
In addition to their undisputed success in solving classical optimization problems, neuroevolutionary and population-based algorithms have become an alternative to standard reinforcement learning methods. However, evolutionary methods often lack the sample efficiency of standard value-based methods that leverage gathered state and value experience. If reinforcement learning for real-world problems with significant resource cost is considered, sample efficiency is essential. The enhancement of evolutionary algorithms with experience exploiting methods is thus desired and promises valuable insights. This work presents a hybrid algorithm that combines topology-changing neuroevolutionary optimization with value-based reinforcement learning. We illustrate how the behavior of policies can be used to create distance and loss functions, which benefit from stored experiences and calculated state values. They allow us to model behavior and perform a directed search in the behavior space by gradient-free evolutionary algorithms and surrogate-based optimization. For this purpose, we consolidate different methods to generate and optimize agent policies, creating a diverse population. We exemplify the performance of our algorithm on standard benchmarks and a purpose-built real-world problem. Our results indicate that combining methods can enhance the sample efficiency and learning speed for evolutionary approaches.
Resource Planning for Hospitals Under Special Consideration of the COVID-19 Pandemic: Optimization and Sensitivity Analysis
May 16, 2021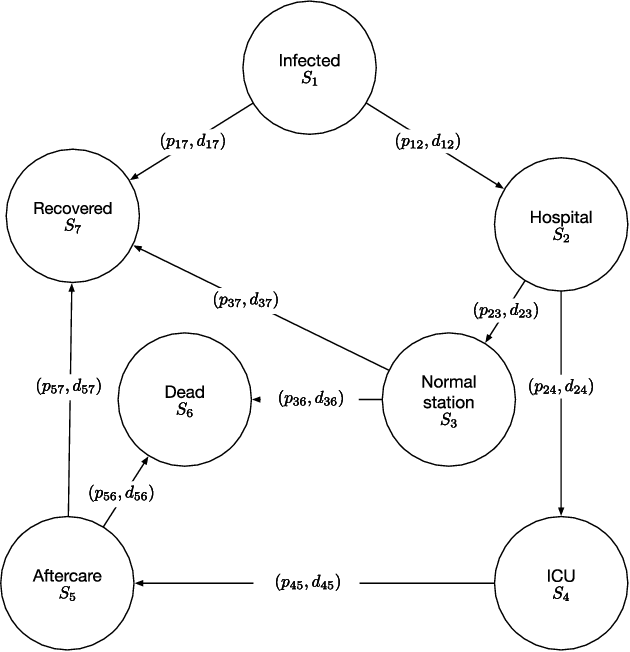
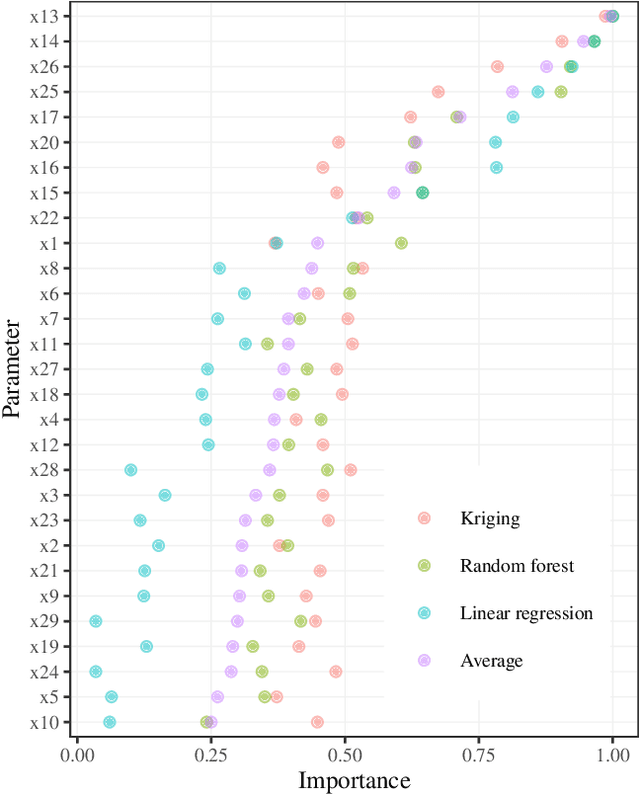
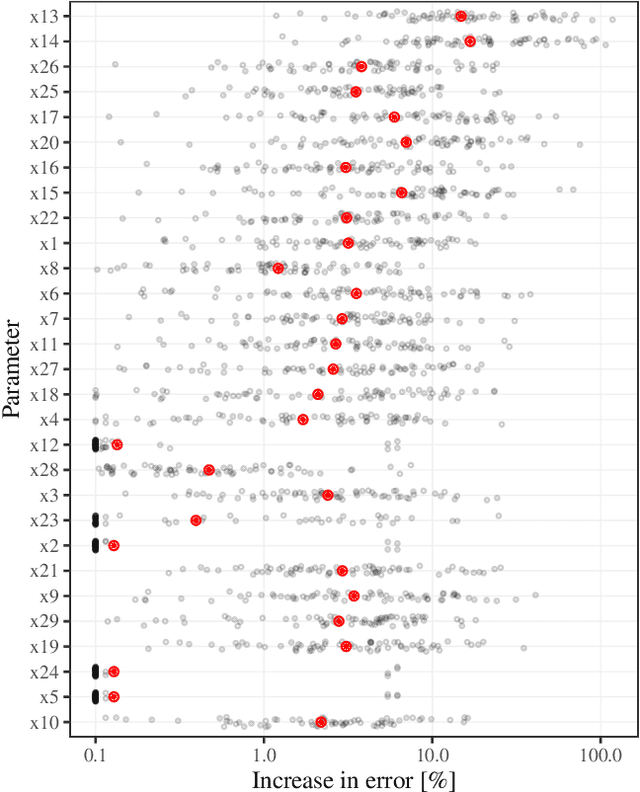
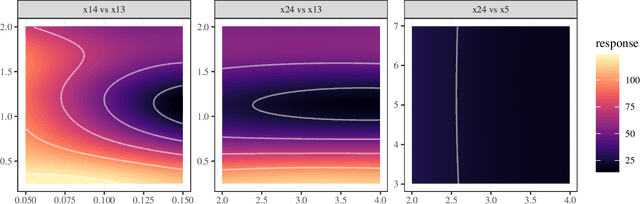
Crises like the COVID-19 pandemic pose a serious challenge to health-care institutions. They need to plan the resources required for handling the increased load, for instance, hospital beds and ventilators. To support the resource planning of local health authorities from the Cologne region, BaBSim.Hospital, a tool for capacity planning based on discrete event simulation, was created. The predictive quality of the simulation is determined by 29 parameters. Reasonable default values of these parameters were obtained in detailed discussions with medical professionals. We aim to investigate and optimize these parameters to improve BaBSim.Hospital. First approaches with "out-of-the-box" optimization algorithms failed. Implementing a surrogate-based optimization approach generated useful results in a reasonable time. To understand the behavior of the algorithm and to get valuable insights into the fitness landscape, an in-depth sensitivity analysis was performed. The sensitivity analysis is crucial for the optimization process because it allows focusing the optimization on the most important parameters. We illustrate how this reduces the problem dimension without compromising the resulting accuracy. The presented approach is applicable to many other real-world problems, e.g., the development of new elevator systems to cover the last mile or simulation of student flow in academic study periods.
Simulation of an Elevator Group Control Using Generative Adversarial Networks and Related AI Tools
Sep 03, 2020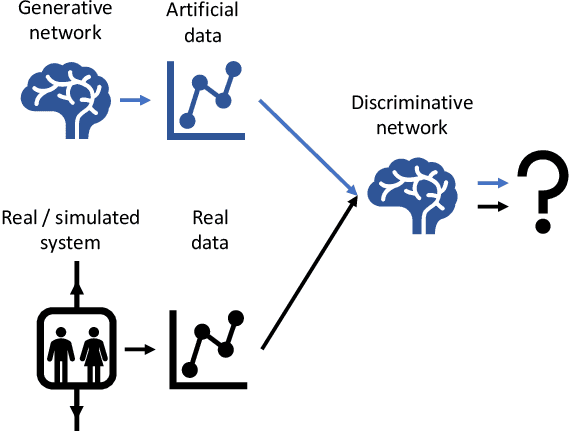

Testing new, innovative technologies is a crucial task for safety and acceptance. But how can new systems be tested if no historical real-world data exist? Simulation provides an answer to this important question. Classical simulation tools such as event-based simulation are well accepted. But most of these established simulation models require the specification of many parameters. Furthermore, simulation runs, e.g., CFD simulations, are very time consuming. Generative Adversarial Networks (GANs) are powerful tools for generating new data for a variety of tasks. Currently, their most frequent application domain is image generation. This article investigates the applicability of GANs for imitating simulations. We are comparing the simulation output of a technical system with the output of a GAN. To exemplify this approach, a well-known multi-car elevator system simulator was chosen. Our study demonstrates the feasibility of this approach. It also discusses pitfalls and technical problems that occurred during the implementation. Although we were able to show that in principle, GANs can be used as substitutes for expensive simulation runs, we also show that they cannot be used "out of the box". Fine tuning is needed. We present a proof-of-concept, which can serve as a starting point for further research.
Continuous Optimization Benchmarks by Simulation
Aug 14, 2020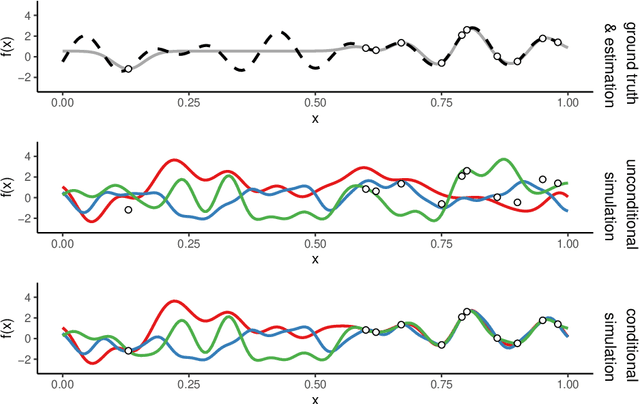
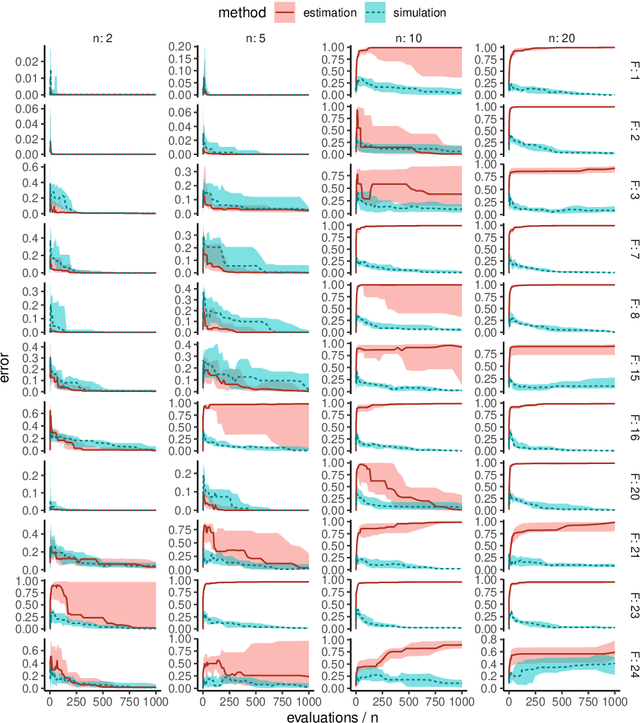
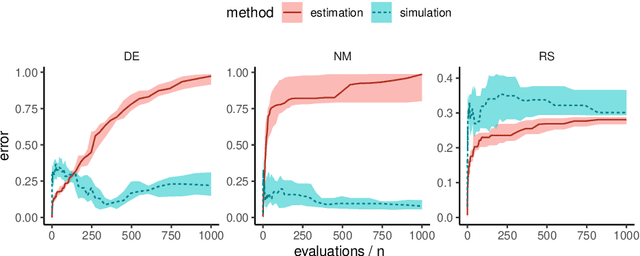
Benchmark experiments are required to test, compare, tune, and understand optimization algorithms. Ideally, benchmark problems closely reflect real-world problem behavior. Yet, real-world problems are not always readily available for benchmarking. For example, evaluation costs may be too high, or resources are unavailable (e.g., software or equipment). As a solution, data from previous evaluations can be used to train surrogate models which are then used for benchmarking. The goal is to generate test functions on which the performance of an algorithm is similar to that on the real-world objective function. However, predictions from data-driven models tend to be smoother than the ground-truth from which the training data is derived. This is especially problematic when the training data becomes sparse. The resulting benchmarks may not reflect the landscape features of the ground-truth, are too easy, and may lead to biased conclusions. To resolve this, we use simulation of Gaussian processes instead of estimation (or prediction). This retains the covariance properties estimated during model training. While previous research suggested a decomposition-based approach for a small-scale, discrete problem, we show that the spectral simulation method enables simulation for continuous optimization problems. In a set of experiments with an artificial ground-truth, we demonstrate that this yields more accurate benchmarks than simply predicting with the Gaussian process model.
Expected Improvement versus Predicted Value in Surrogate-Based Optimization
Feb 17, 2020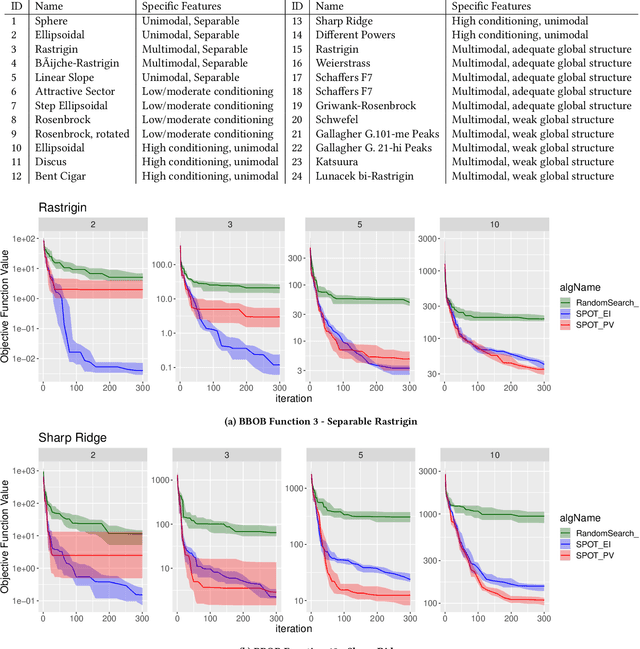
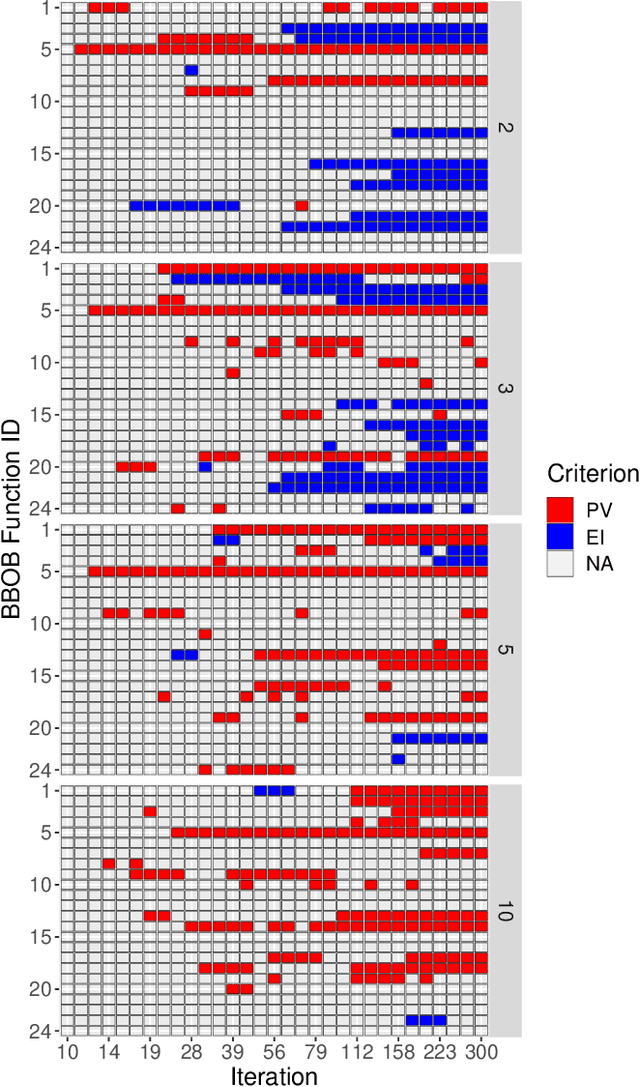
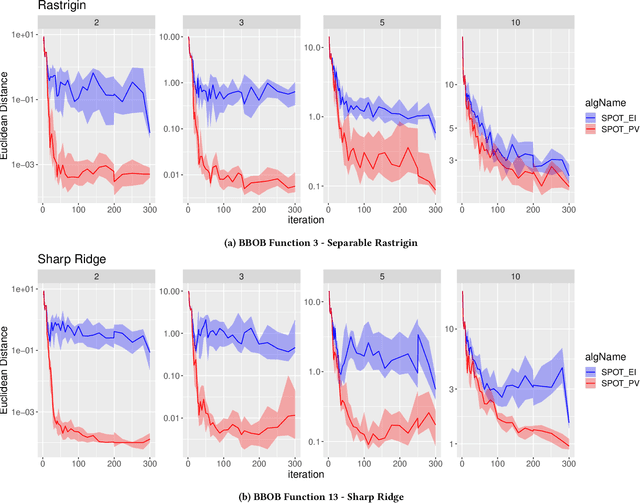
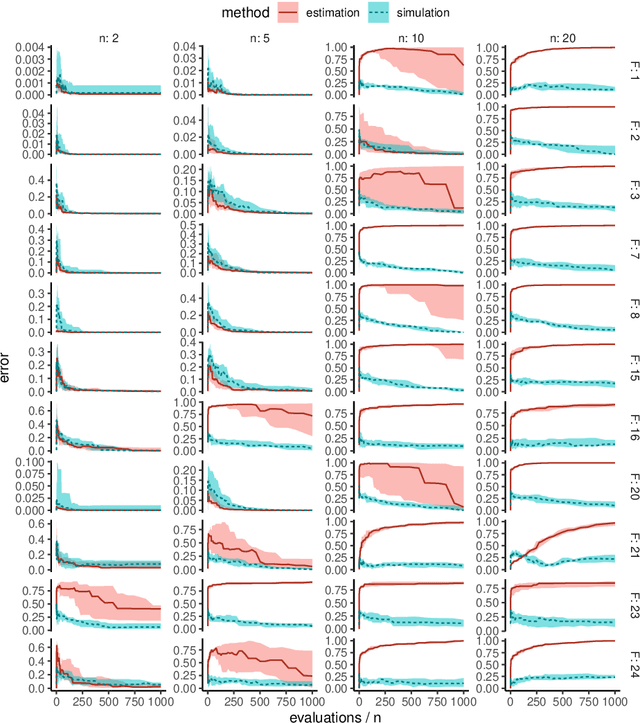
Surrogate-based optimization relies on so-called infill criteria (acquisition functions) to decide which point to evaluate next. When Kriging is used as the surrogate model of choice (also called Bayesian optimization), one of the most frequently chosen criteria is expected improvement. We argue that the popularity of expected improvement largely relies on its theoretical properties rather than empirically validated performance. Few results from the literature show evidence, that under certain conditions, expected improvement may perform worse than something as simple as the predicted value of the surrogate model. We benchmark both infill criteria in an extensive empirical study on the `BBOB' function set. This investigation includes a detailed study of the impact of problem dimensionality on algorithm performance. The results support the hypothesis that exploration loses importance with increasing problem dimensionality. A statistical analysis reveals that the purely exploitative search with the predicted value criterion performs better on most problems of five or higher dimensions. Possible reasons for these results are discussed. In addition, we give an in-depth guide for choosing the infill criteria based on prior knowledge about the problem at hand, its dimensionality, and the available budget.
Surrogate Models for Enhancing the Efficiency of Neuroevolution in Reinforcement Learning
Jul 22, 2019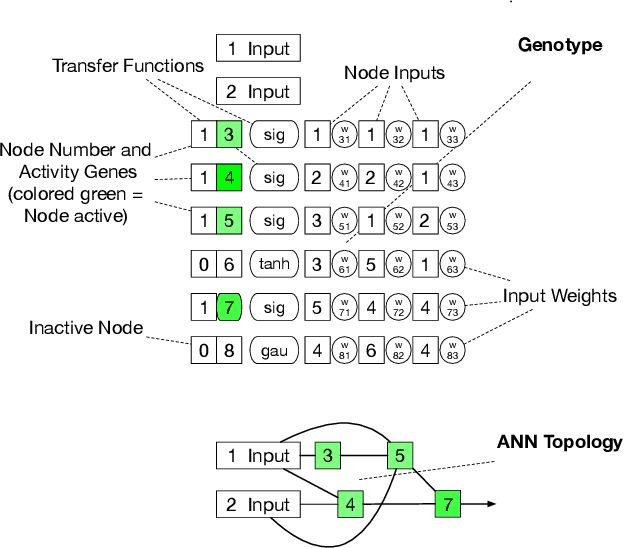
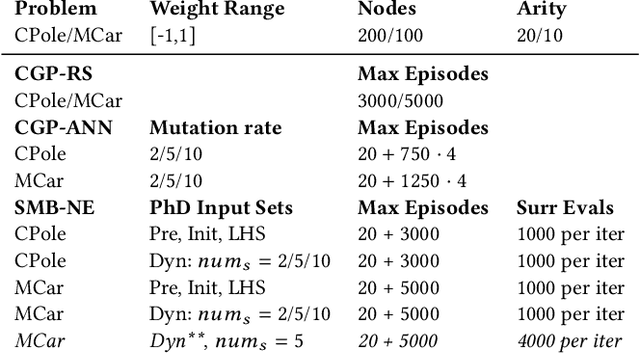
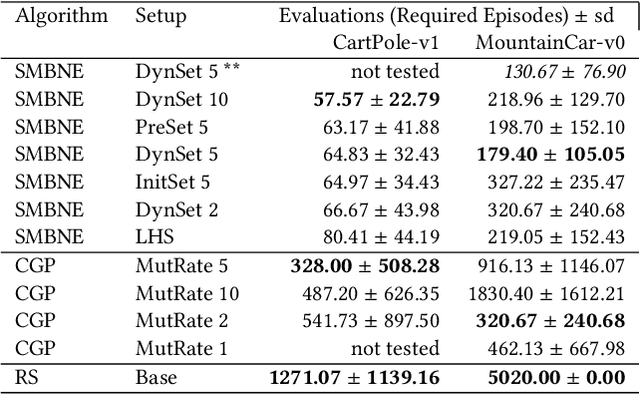
In the last years, reinforcement learning received a lot of attention. One method to solve reinforcement learning tasks is Neuroevolution, where neural networks are optimized by evolutionary algorithms. A disadvantage of Neuroevolution is that it can require numerous function evaluations, while not fully utilizing the available information from each fitness evaluation. This is especially problematic when fitness evaluations become expensive. To reduce the cost of fitness evaluations, surrogate models can be employed to partially replace the fitness function. The difficulty of surrogate modeling for Neuroevolution is the complex search space and how to compare different networks. To that end, recent studies showed that a kernel based approach, particular with phenotypic distance measures, works well. These kernels compare different networks via their behavior (phenotype) rather than their topology or encoding (genotype). In this work, we discuss the use of surrogate model-based Neuroevolution (SMB-NE) using a phenotypic distance for reinforcement learning. In detail, we investigate a) the potential of SMB-NE with respect to evaluation efficiency and b) how to select adequate input sets for the phenotypic distance measure in a reinforcement learning problem. The results indicate that we are able to considerably increase the evaluation efficiency using dynamic input sets.
* This is the authors version of the work. It is posted here for your personal use. Not for redistribution. The definitive Version of Record was published in Genetic and Evolutionary Computation Conference (GECCO 2019)
Prediction of neural network performance by phenotypic modeling
Jul 16, 2019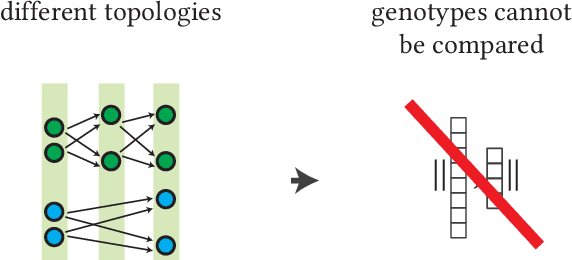
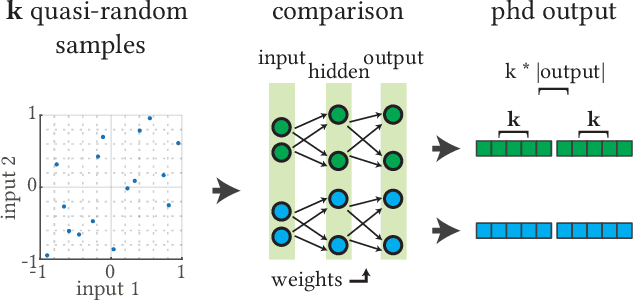
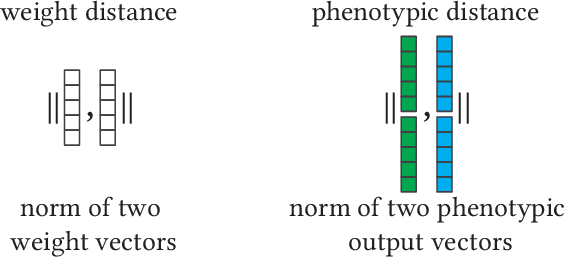
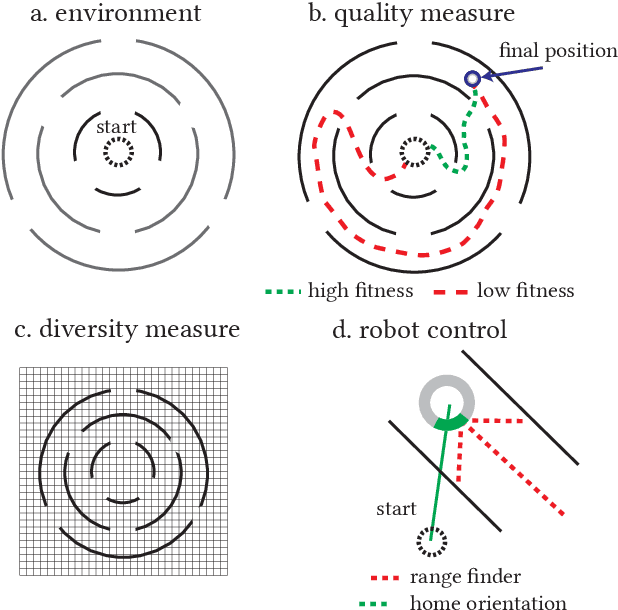
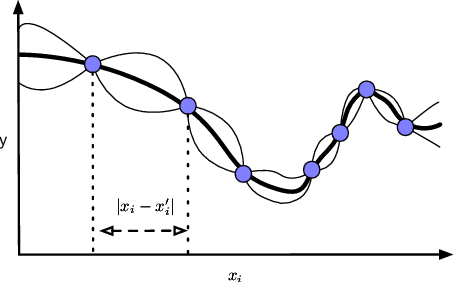
Surrogate models are used to reduce the burden of expensive-to-evaluate objective functions in optimization. By creating models which map genomes to objective values, these models can estimate the performance of unknown inputs, and so be used in place of expensive objective functions. Evolutionary techniques such as genetic programming or neuroevolution commonly alter the structure of the genome itself. A lack of consistency in the genotype is a fatal blow to data-driven modeling techniques: interpolation between points is impossible without a common input space. However, while the dimensionality of genotypes may differ across individuals, in many domains, such as controllers or classifiers, the dimensionality of the input and output remains constant. In this work we leverage this insight to embed differing neural networks into the same input space. To judge the difference between the behavior of two neural networks, we give them both the same input sequence, and examine the difference in output. This difference, the phenotypic distance, can then be used to situate these networks into a common input space, allowing us to produce surrogate models which can predict the performance of neural networks regardless of topology. In a robotic navigation task, we show that models trained using this phenotypic embedding perform as well or better as those trained on the weight values of a fixed topology neural network. We establish such phenotypic surrogate models as a promising and flexible approach which enables surrogate modeling even for representations that undergo structural changes.