 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe First AI4TSP Competition: Learning to Solve Stochastic Routing Problems
Jan 25, 2022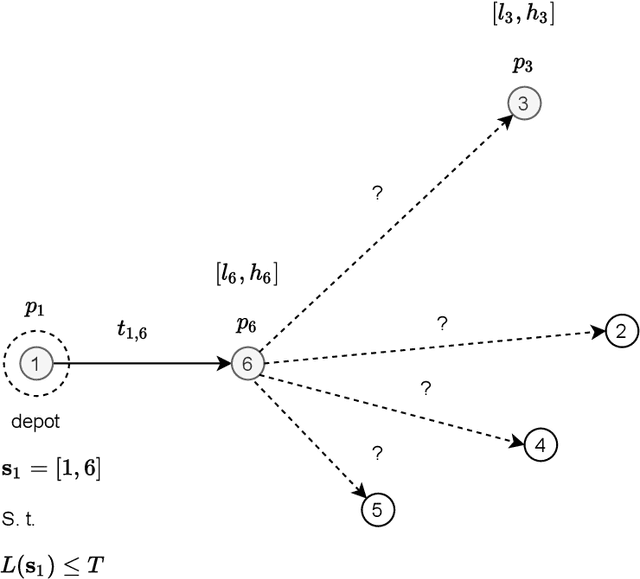
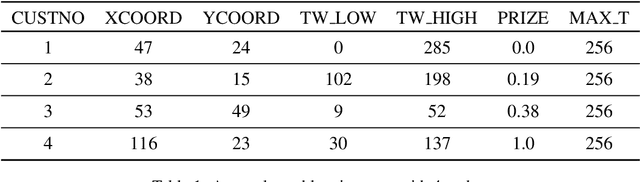

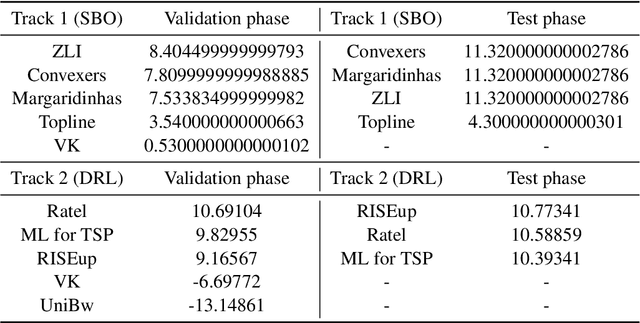
This paper reports on the first international competition on AI for the traveling salesman problem (TSP) at the International Joint Conference on Artificial Intelligence 2021 (IJCAI-21). The TSP is one of the classical combinatorial optimization problems, with many variants inspired by real-world applications. This first competition asked the participants to develop algorithms to solve a time-dependent orienteering problem with stochastic weights and time windows (TD-OPSWTW). It focused on two types of learning approaches: surrogate-based optimization and deep reinforcement learning. In this paper, we describe the problem, the setup of the competition, the winning methods, and give an overview of the results. The winning methods described in this work have advanced the state-of-the-art in using AI for stochastic routing problems. Overall, by organizing this competition we have introduced routing problems as an interesting problem setting for AI researchers. The simulator of the problem has been made open-source and can be used by other researchers as a benchmark for new AI methods.
Automated Reinforcement Learning: An Overview
Jan 13, 2022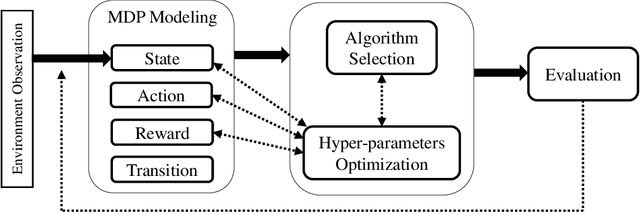

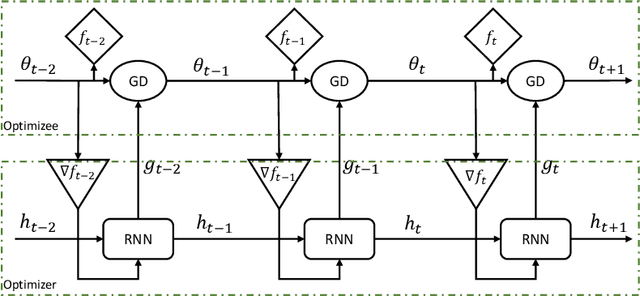
Reinforcement Learning and recently Deep Reinforcement Learning are popular methods for solving sequential decision making problems modeled as Markov Decision Processes. RL modeling of a problem and selecting algorithms and hyper-parameters require careful considerations as different configurations may entail completely different performances. These considerations are mainly the task of RL experts; however, RL is progressively becoming popular in other fields where the researchers and system designers are not RL experts. Besides, many modeling decisions, such as defining state and action space, size of batches and frequency of batch updating, and number of timesteps are typically made manually. For these reasons, automating different components of RL framework is of great importance and it has attracted much attention in recent years. Automated RL provides a framework in which different components of RL including MDP modeling, algorithm selection and hyper-parameter optimization are modeled and defined automatically. In this article, we explore the literature and present recent work that can be used in automated RL. Moreover, we discuss the challenges, open questions and research directions in AutoRL.
A State Aggregation Approach for Solving Knapsack Problem with Deep Reinforcement Learning
Apr 25, 2020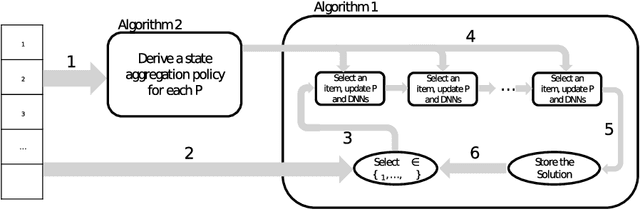

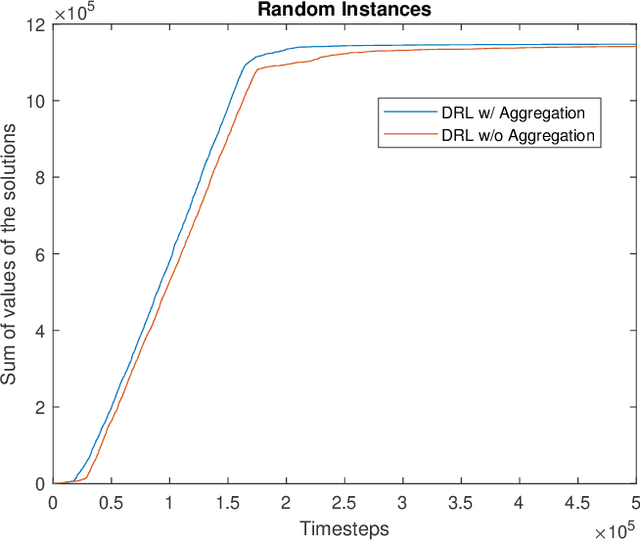
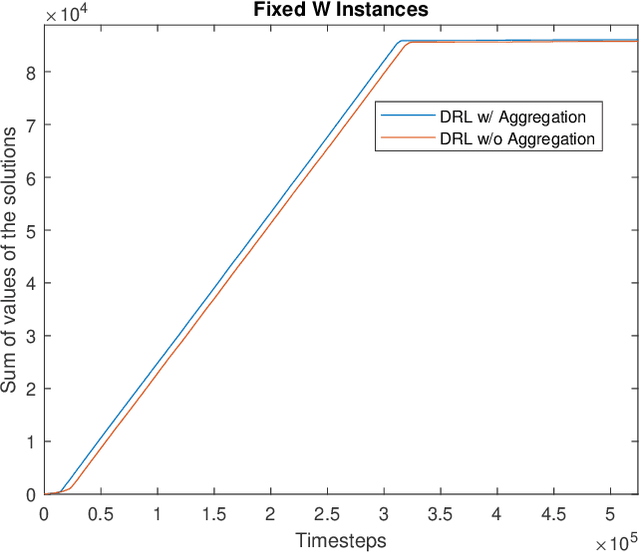
This paper proposes a Deep Reinforcement Learning (DRL) approach for solving knapsack problem. The proposed method consists of a state aggregation step based on tabular reinforcement learning to extract features and construct states. The state aggregation policy is applied to each problem instance of the knapsack problem, which is used with Advantage Actor Critic (A2C) algorithm to train a policy through which the items are sequentially selected at each time step. The method is a constructive solution approach and the process of selecting items is repeated until the final solution is obtained. The experiments show that our approach provides close to optimal solutions for all tested instances, outperforms the greedy algorithm, and is able to handle larger instances and more flexible than an existing DRL approach. In addition, the results demonstrate that the proposed model with the state aggregation strategy not only gives better solutions but also learns in less timesteps, than the one without state aggregation.