 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA State Aggregation Approach for Solving Knapsack Problem with Deep Reinforcement Learning
Apr 25, 2020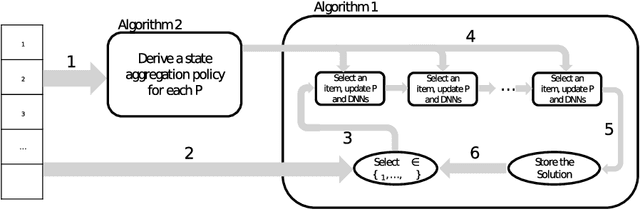

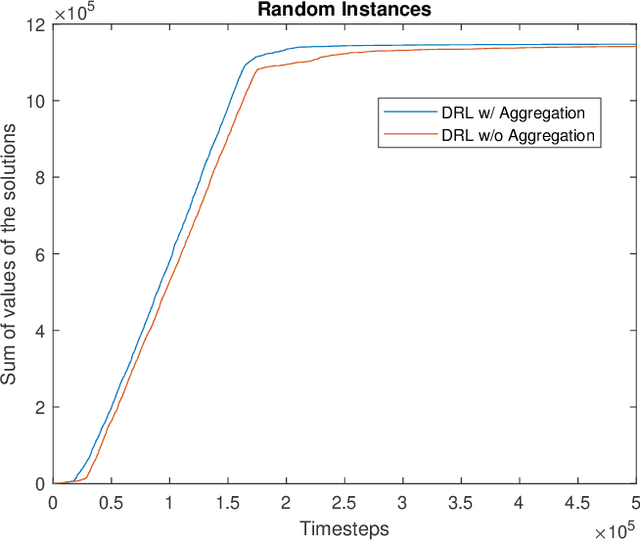
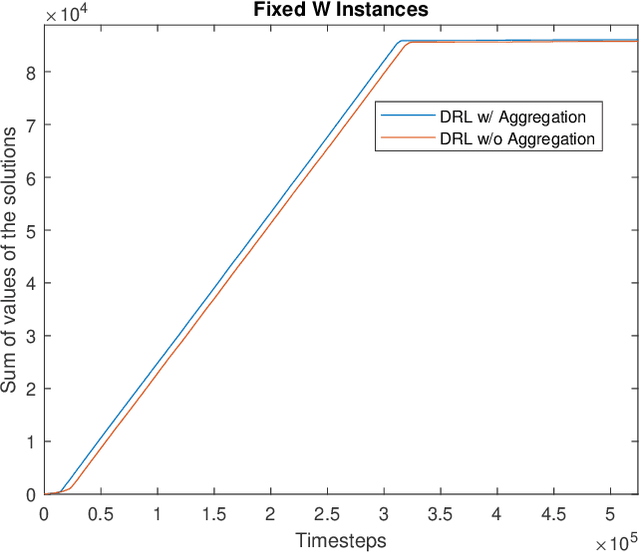
This paper proposes a Deep Reinforcement Learning (DRL) approach for solving knapsack problem. The proposed method consists of a state aggregation step based on tabular reinforcement learning to extract features and construct states. The state aggregation policy is applied to each problem instance of the knapsack problem, which is used with Advantage Actor Critic (A2C) algorithm to train a policy through which the items are sequentially selected at each time step. The method is a constructive solution approach and the process of selecting items is repeated until the final solution is obtained. The experiments show that our approach provides close to optimal solutions for all tested instances, outperforms the greedy algorithm, and is able to handle larger instances and more flexible than an existing DRL approach. In addition, the results demonstrate that the proposed model with the state aggregation strategy not only gives better solutions but also learns in less timesteps, than the one without state aggregation.
Constructing classification trees using column generation
Oct 15, 2018

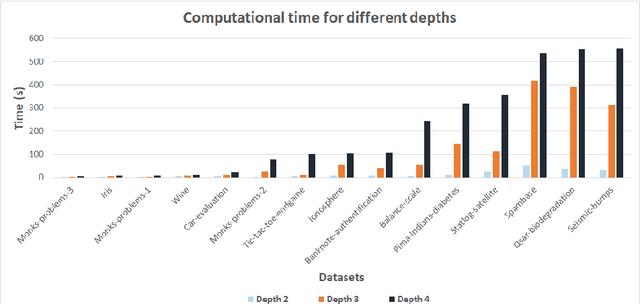

This paper explores the use of Column Generation (CG) techniques in constructing univariate binary decision trees for classification tasks. We propose a novel Integer Linear Programming (ILP) formulation, based on paths in decision trees. We show that the associated pricing problem is NP-hard and propose a random procedure for column selection. In addition, to speed up column generation, we use a restricted parameter set via a sampling procedure using the well-known CART algorithm. Extensive numerical experiments show that our approach outperforms the state-of-the-art ILP-based algorithms in the recent literature both in computation time and solution quality. We also find better solutions that have higher training and testing accuracy than an optimized version of CART. Furthermore, our approach is capable of handling big data sets with tens of thousands of data rows, unlike other ILP-based algorithms. In addition, our approach has the advantage of being able to easily incorporate different objectives.