 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlternating Bi-Objective Optimization for Explainable Neuro-Fuzzy Systems
Feb 22, 2026Fuzzy systems show strong potential in explainable AI due to their rule-based architecture and linguistic variables. Existing approaches navigate the accuracy-explainability trade-off either through evolutionary multi-objective optimization (MOO), which is computationally expensive, or gradient-based scalarization, which cannot recover non-convex Pareto regions. We propose X-ANFIS, an alternating bi-objective gradient-based optimization scheme for explainable adaptive neuro-fuzzy inference systems. Cauchy membership functions are used for stable training under semantically controlled initializations, and a differentiable explainability objective is introduced and decoupled from the performance objective through alternating gradient passes. Validated in approximately 5,000 experiments on nine UCI regression datasets, X-ANFIS consistently achieves target distinguishability while maintaining competitive predictive accuracy, recovering solutions beyond the convex hull of the MOO Pareto front.
Interpretable Fuzzy Systems For Forward Osmosis Desalination
Feb 08, 2026Preserving interpretability in fuzzy rule-based systems (FRBS) is vital for water treatment, where decisions impact public health. While structural interpretability has been addressed using multi-objective algorithms, semantic interpretability often suffers due to fuzzy sets with low distinguishability. We propose a human-in-the-loop approach for developing interpretable FRBS to predict forward osmosis desalination productivity. Our method integrates expert-driven grid partitioning for distinguishable membership functions, domain-guided feature engineering to reduce redundancy, and rule pruning based on firing strength. This approach achieved comparable predictive performance to cluster-based FRBS while maintaining semantic interpretability and meeting structural complexity constraints, providing an explainable solution for water treatment applications.
* 7 pages, 4 figures, FUZZ-IEEE 2025
Predictive Maintenance for Ultrafiltration Membranes Using Explainable Similarity-Based Prognostics
Jan 31, 2026In reverse osmosis desalination, ultrafiltration (UF) membranes degrade due to fouling, leading to performance loss and costly downtime. Most plants rely on scheduled preventive maintenance, since existing predictive maintenance models, often based on opaque machine learning methods, lack interpretability and operator trust. This study proposes an explainable prognostic framework for UF membrane remaining useful life (RUL) estimation using fuzzy similarity reasoning. A physics-informed Health Index, derived from transmembrane pressure, flux, and resistance, captures degradation dynamics, which are then fuzzified via Gaussian membership functions. Using a similarity measure, the model identifies historical degradation trajectories resembling the current state and formulates RUL predictions as Takagi-Sugeno fuzzy rules. Each rule corresponds to a historical exemplar and contributes to a transparent, similarity-weighted RUL estimate. Tested on 12,528 operational cycles from an industrial-scale UF system, the framework achieved a mean absolute error of 4.50 cycles, while generating interpretable rule bases consistent with expert understanding.
Explainable Uncertainty Quantification for Wastewater Treatment Energy Prediction via Interval Type-2 Neuro-Fuzzy System
Jan 26, 2026Wastewater treatment plants consume 1-3% of global electricity, making accurate energy forecasting critical for operational optimization and sustainability. While machine learning models provide point predictions, they lack explainable uncertainty quantification essential for risk-aware decision-making in safety-critical infrastructure. This study develops an Interval Type-2 Adaptive Neuro-Fuzzy Inference System (IT2-ANFIS) that generates interpretable prediction intervals through fuzzy rule structures. Unlike black-box probabilistic methods, the proposed framework decomposes uncertainty across three levels: feature-level, footprint of uncertainty identify which variables introduce ambiguity, rule-level analysis reveals confidence in local models, and instance-level intervals quantify overall prediction uncertainty. Validated on Melbourne Water's Eastern Treatment Plant dataset, IT2-ANFIS achieves comparable predictive performance to first order ANFIS with substantially reduced variance across training runs, while providing explainable uncertainty estimates that link prediction confidence directly to operational conditions and input variables.
Explainable Fuzzy GNNs for Leak Detection in Water Distribution Networks
Jan 06, 2026Timely leak detection in water distribution networks is critical for conserving resources and maintaining operational efficiency. Although Graph Neural Networks (GNNs) excel at capturing spatial-temporal dependencies in sensor data, their black-box nature and the limited work on graph-based explainable models for water networks hinder practical adoption. We propose an explainable GNN framework that integrates mutual information to identify critical network regions and fuzzy logic to provide clear, rule-based explanations for node classification tasks. After benchmarking several GNN architectures, we selected the generalized graph convolution network (GENConv) for its superior performance and developed a fuzzy-enhanced variant that offers intuitive explanations for classified leak locations. Our fuzzy graph neural network (FGENConv) achieved Graph F1 scores of 0.889 for detection and 0.814 for localization, slightly below the crisp GENConv 0.938 and 0.858, respectively. Yet it compensates by providing spatially localized, fuzzy rule-based explanations. By striking the right balance between precision and explainability, the proposed fuzzy network could enable hydraulic engineers to validate predicted leak locations, conserve human resources, and optimize maintenance strategies. The code is available at github.com/pasqualedem/GNNLeakDetection.
Making sense of violence risk predictions using clinical notes
Apr 29, 2022
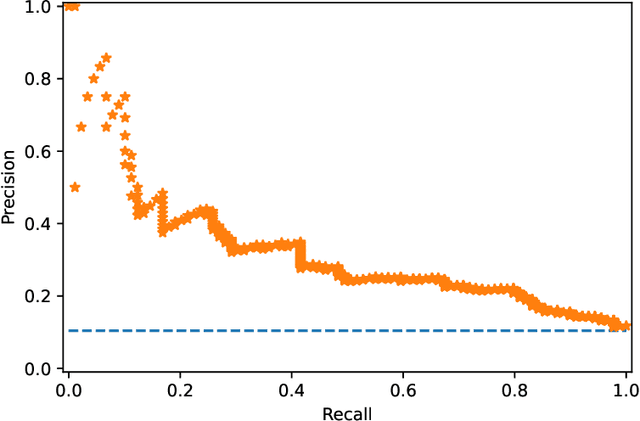
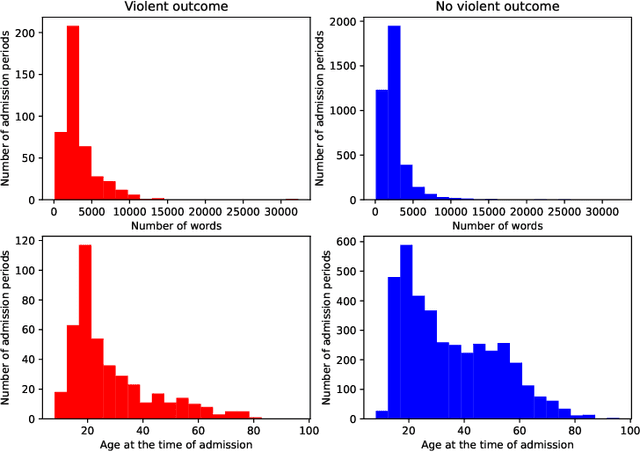
Violence risk assessment in psychiatric institutions enables interventions to avoid violence incidents. Clinical notes written by practitioners and available in electronic health records (EHR) are valuable resources that are seldom used to their full potential. Previous studies have attempted to assess violence risk in psychiatric patients using such notes, with acceptable performance. However, they do not explain why classification works and how it can be improved. We explore two methods to better understand the quality of a classifier in the context of clinical note analysis: random forests using topic models, and choice of evaluation metric. These methods allow us to understand both our data and our methodology more profoundly, setting up the groundwork to work on improved models that build upon this understanding. This is particularly important when it comes to the generalizability of evaluated classifiers to new data, a trustworthiness problem that is of great interest due to the increased availability of new data in electronic format.
* arXiv admin note: substantial text overlap with arXiv:2204.13535
Machine Learning for Violence Risk Assessment Using Dutch Clinical Notes
Apr 28, 2022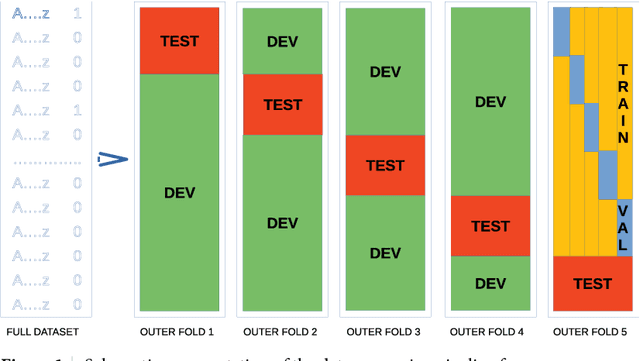

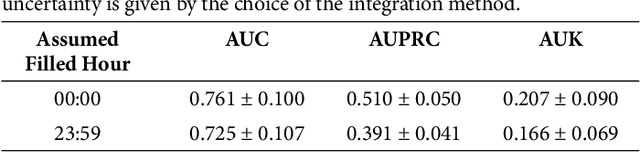
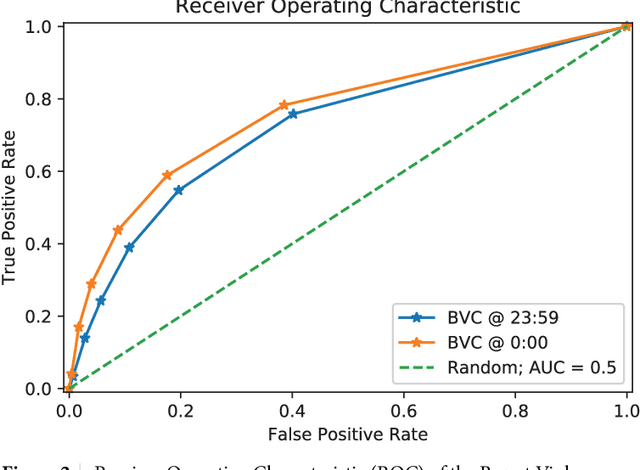
Violence risk assessment in psychiatric institutions enables interventions to avoid violence incidents. Clinical notes written by practitioners and available in electronic health records are valuable resources capturing unique information, but are seldom used to their full potential. We explore conventional and deep machine learning methods to assess violence risk in psychiatric patients using practitioner notes. The performance of our best models is comparable to the currently used questionnaire-based method, with an area under the Receiver Operating Characteristic curve of approximately 0.8. We find that the deep-learning model BERTje performs worse than conventional machine learning methods. We also evaluate our data and our classifiers to understand the performance of our models better. This is particularly important for the applicability of evaluated classifiers to new data, and is also of great interest to practitioners, due to the increased availability of new data in electronic format.
Automated Reinforcement Learning: An Overview
Jan 13, 2022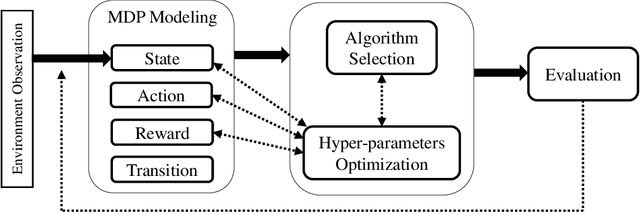

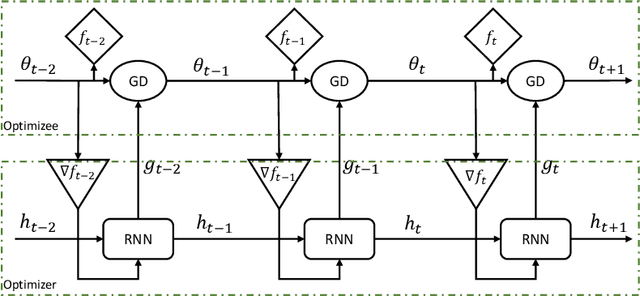
Reinforcement Learning and recently Deep Reinforcement Learning are popular methods for solving sequential decision making problems modeled as Markov Decision Processes. RL modeling of a problem and selecting algorithms and hyper-parameters require careful considerations as different configurations may entail completely different performances. These considerations are mainly the task of RL experts; however, RL is progressively becoming popular in other fields where the researchers and system designers are not RL experts. Besides, many modeling decisions, such as defining state and action space, size of batches and frequency of batch updating, and number of timesteps are typically made manually. For these reasons, automating different components of RL framework is of great importance and it has attracted much attention in recent years. Automated RL provides a framework in which different components of RL including MDP modeling, algorithm selection and hyper-parameter optimization are modeled and defined automatically. In this article, we explore the literature and present recent work that can be used in automated RL. Moreover, we discuss the challenges, open questions and research directions in AutoRL.
A State Aggregation Approach for Solving Knapsack Problem with Deep Reinforcement Learning
Apr 25, 2020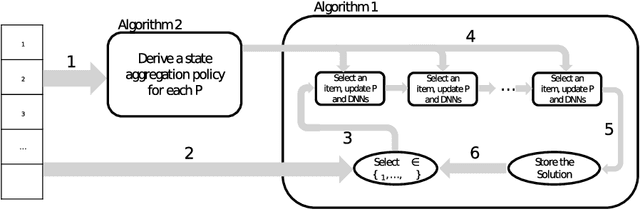

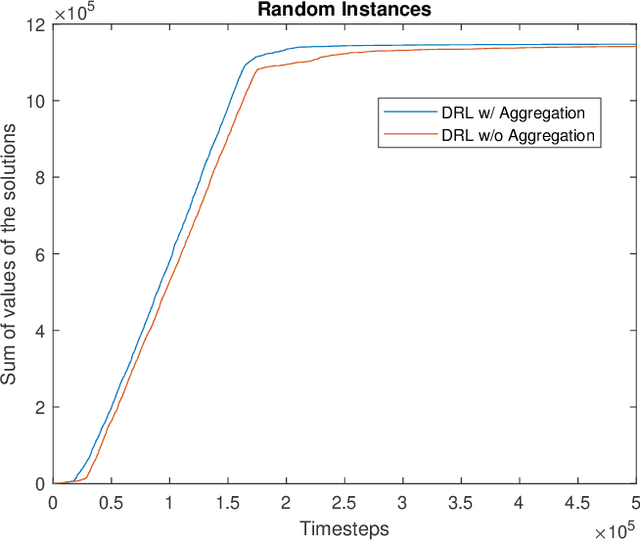
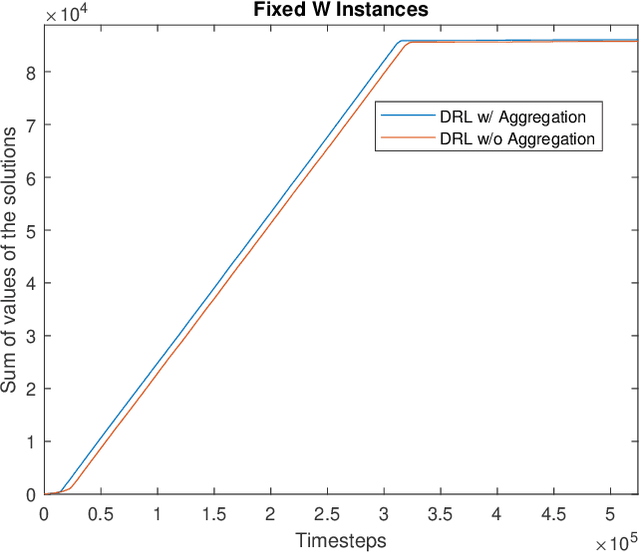
This paper proposes a Deep Reinforcement Learning (DRL) approach for solving knapsack problem. The proposed method consists of a state aggregation step based on tabular reinforcement learning to extract features and construct states. The state aggregation policy is applied to each problem instance of the knapsack problem, which is used with Advantage Actor Critic (A2C) algorithm to train a policy through which the items are sequentially selected at each time step. The method is a constructive solution approach and the process of selecting items is repeated until the final solution is obtained. The experiments show that our approach provides close to optimal solutions for all tested instances, outperforms the greedy algorithm, and is able to handle larger instances and more flexible than an existing DRL approach. In addition, the results demonstrate that the proposed model with the state aggregation strategy not only gives better solutions but also learns in less timesteps, than the one without state aggregation.
Algorithms for slate bandits with non-separable reward functions
Apr 21, 2020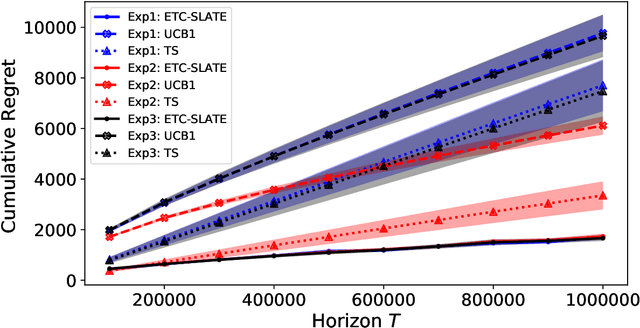

In this paper, we study a slate bandit problem where the function that determines the slate-level reward is non-separable: the optimal value of the function cannot be determined by learning the optimal action for each slot. We are mainly concerned with cases where the number of slates is large relative to the time horizon, so that trying each slate as a separate arm in a traditional multi-armed bandit, would not be feasible. Our main contribution is the design of algorithms that still have sub-linear regret with respect to the time horizon, despite the large number of slates. Experimental results on simulated data and real-world data show that our proposed method outperforms popular benchmark bandit algorithms.