 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithms for slate bandits with non-separable reward functions
Apr 21, 2020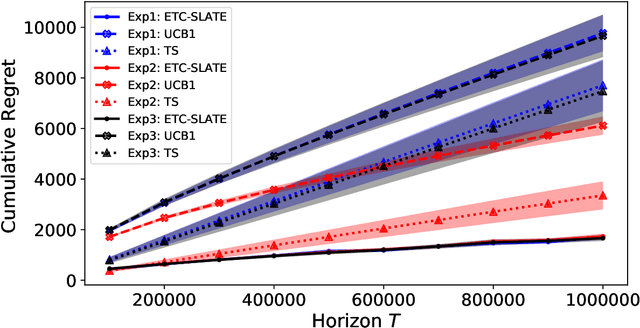

In this paper, we study a slate bandit problem where the function that determines the slate-level reward is non-separable: the optimal value of the function cannot be determined by learning the optimal action for each slot. We are mainly concerned with cases where the number of slates is large relative to the time horizon, so that trying each slate as a separate arm in a traditional multi-armed bandit, would not be feasible. Our main contribution is the design of algorithms that still have sub-linear regret with respect to the time horizon, despite the large number of slates. Experimental results on simulated data and real-world data show that our proposed method outperforms popular benchmark bandit algorithms.
Learning 2-opt Heuristics for the Traveling Salesman Problem via Deep Reinforcement Learning
Apr 03, 2020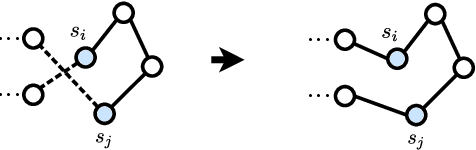

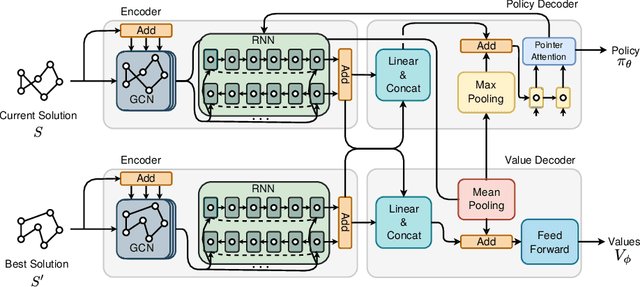

Recent works using deep learning to solve the Traveling Salesman Problem (TSP) have focused on learning construction heuristics. Such approaches find TSP solutions of good quality but require additional procedures such as beam search and sampling to improve solutions and achieve state-of-the-art performance. However, few studies have focused on improvement heuristics, where a given solution is improved until reaching a near-optimal one. In this work, we propose to learn a local search heuristic based on 2-opt operators via deep reinforcement learning. We propose a policy gradient algorithm to learn a stochastic policy that selects 2-opt operations given a current solution. Moreover, we introduce a policy neural network that leverages a pointing attention mechanism, which unlike previous works, can be easily extended to more general k-opt moves. Our results show that the learned policies can improve even over random initial solutions and approach near-optimal solutions at a faster rate than previous state-of-the-art deep learning methods.
Machine Learning based Simulation Optimisation for Trailer Management
Jul 17, 2019



In many situations, simulation models are developed to handle complex real-world business optimisation problems. For example, a discrete-event simulation model is used to simulate the trailer management process in a big Fast-Moving Consumer Goods company. To address the problem of finding suitable inputs to this simulator for optimising fleet configuration, we propose a simulation optimisation approach in this paper. The simulation optimisation model combines a metaheuristic search (genetic algorithm), with an approximation model filter (feed-forward neural network) to optimise the parameter configuration of the simulation model. We introduce an ensure probability that overrules the rejection of potential solutions by the approximation model and we demonstrate its effectiveness. In addition, we evaluate the impact of the parameters of the optimisation model on its effectiveness and show the parameters such as population size, filter threshold, and mutation probability can have a significant impact on the overall optimisation performance. Moreover, we compare the proposed method with a single global approximation model approach and a random-based approach. The results show the effectiveness of our method in terms of computation time and solution quality.