 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicies for the Dynamic Traveling Maintainer Problem with Alerts
May 31, 2021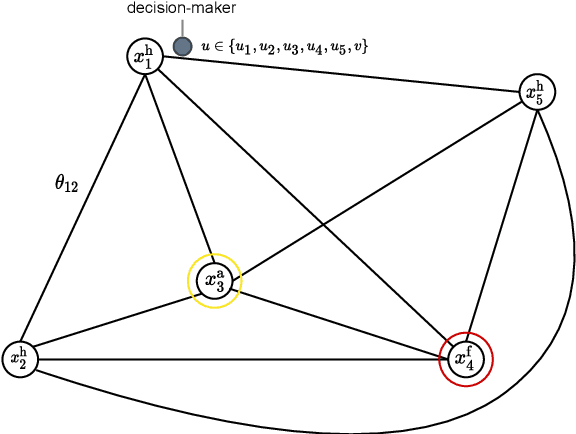
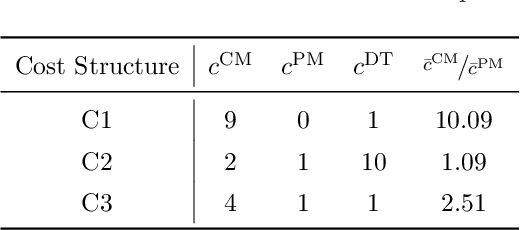
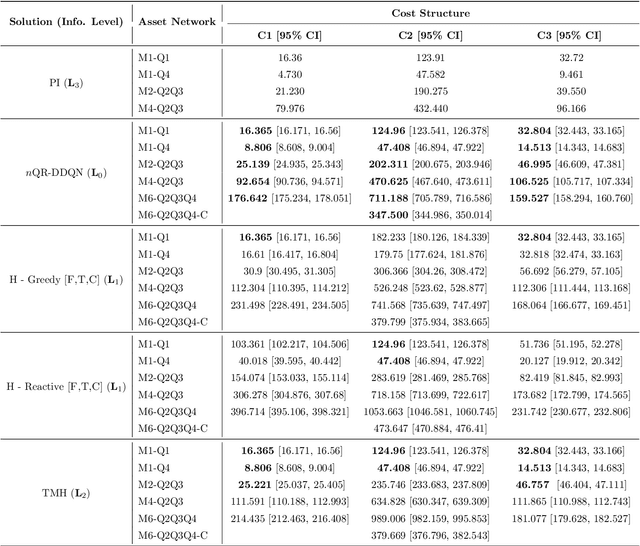
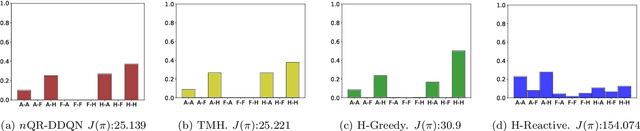
Companies require modern capital assets such as wind turbines, trains and hospital equipment to experience minimal downtime. Ideally, assets are maintained right before failure to ensure maximum availability at minimum maintenance costs. To this end, two challenges arise: failure times of assets are unknown a priori and assets can be part of a larger asset network. Nowadays, it is common for assets to be equipped with real-time monitoring that emits alerts, typically triggered by the first signs of degradation. Thus, it becomes crucial to plan maintenance considering information received via alerts, asset locations and maintenance costs. This problem is referred to as the Dynamic Traveling Maintainer Problem with Alerts (DTMPA). We propose a modeling framework for the DTMPA, where the alerts are early and imperfect indicators of failures. The objective is to minimize discounted maintenance costs accrued over an infinite time horizon. We propose three methods to solve this problem, leveraging different information levels from the alert signals. The proposed methods comprise various greedy heuristics that rank assets based on proximity, urgency and economic risk; a Traveling Maintainer Heuristic employing combinatorial optimization to optimize near-future costs; a Deep Reinforcement Learning (DRL) method trained to minimize the long-term costs using exclusively the history of alerts. In a simulated environment, all methods can approximate optimal policies with access to perfect condition information for small asset networks. For larger networks, where computing the optimal policy is intractable, the proposed methods yield competitive maintenance policies, with DRL consistently achieving the lowest costs.
Reinforcement Learning under Model Risk for Biomanufacturing Fermentation Control
Jan 11, 2021

In the biopharmaceutical manufacturing, fermentation process plays a critical role impacting on productivity and profit. Since biotherapeutics are manufactured in living cells whose biological mechanisms are complex and have highly variable outputs, in this paper, we introduce a model-based reinforcement learning framework accounting for model risk to support bioprocess online learning and guide the optimal and robust customized stopping policy for fermentation process. Specifically, built on the dynamic mechanisms of protein and impurity generation, we first construct a probabilistic model characterizing the impact of underlying bioprocess stochastic uncertainty on impurity and protein growth rates. Since biopharmaceutical manufacturing often has very limited data during the development and early stage of production, we derive the posterior distribution quantifying the process model risk, and further develop the Bayesian rule based knowledge update to support the online learning on underlying stochastic process. With the prediction risk accounting for both bioprocess stochastic uncertainty and model risk, the proposed reinforcement learning framework can proactively hedge all sources of uncertainties and support the optimal and robust customized decision making. We conduct the structural analysis of optimal policy and study the impact of model risk on the policy selection. We can show that it asymptotically converges to the optimal policy obtained under perfect information of underlying stochastic process. Our case studies demonstrate that the proposed framework can greatly improve the biomanufacturing industrial practice.
Algorithms for slate bandits with non-separable reward functions
Apr 21, 2020

In this paper, we study a slate bandit problem where the function that determines the slate-level reward is non-separable: the optimal value of the function cannot be determined by learning the optimal action for each slot. We are mainly concerned with cases where the number of slates is large relative to the time horizon, so that trying each slate as a separate arm in a traditional multi-armed bandit, would not be feasible. Our main contribution is the design of algorithms that still have sub-linear regret with respect to the time horizon, despite the large number of slates. Experimental results on simulated data and real-world data show that our proposed method outperforms popular benchmark bandit algorithms.
Learning 2-opt Heuristics for the Traveling Salesman Problem via Deep Reinforcement Learning
Apr 03, 2020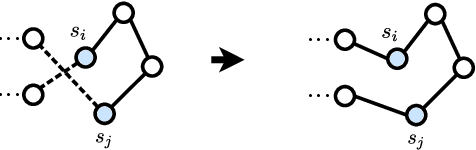

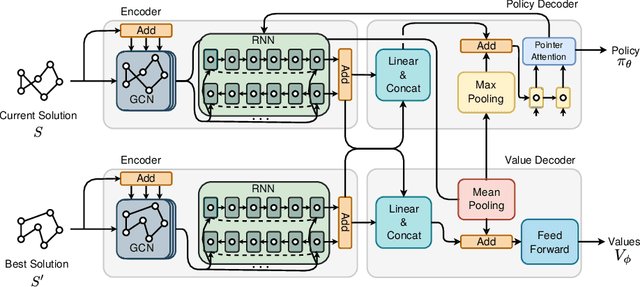

Recent works using deep learning to solve the Traveling Salesman Problem (TSP) have focused on learning construction heuristics. Such approaches find TSP solutions of good quality but require additional procedures such as beam search and sampling to improve solutions and achieve state-of-the-art performance. However, few studies have focused on improvement heuristics, where a given solution is improved until reaching a near-optimal one. In this work, we propose to learn a local search heuristic based on 2-opt operators via deep reinforcement learning. We propose a policy gradient algorithm to learn a stochastic policy that selects 2-opt operations given a current solution. Moreover, we introduce a policy neural network that leverages a pointing attention mechanism, which unlike previous works, can be easily extended to more general k-opt moves. Our results show that the learned policies can improve even over random initial solutions and approach near-optimal solutions at a faster rate than previous state-of-the-art deep learning methods.
Remaining Useful Lifetime Prediction via Deep Domain Adaptation
Jul 17, 2019

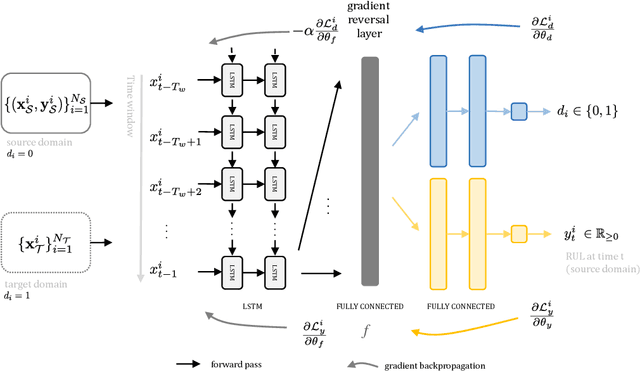
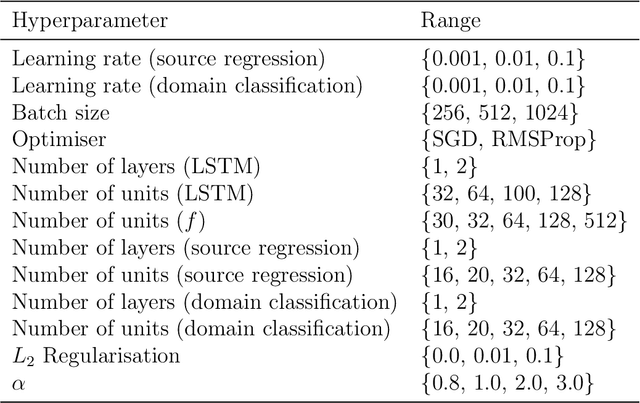
In Prognostics and Health Management (PHM) sufficient prior observed degradation data is usually critical for Remaining Useful Lifetime (RUL) prediction. Most previous data-driven prediction methods assume that training (source) and testing (target) condition monitoring data have similar distributions. However, due to different operating conditions, fault modes, noise and equipment updates distribution shift exists across different data domains. This shift reduces the performance of predictive models previously built to specific conditions when no observed run-to-failure data is available for retraining. To address this issue, this paper proposes a new data-driven approach for domain adaptation in prognostics using Long Short-Term Neural Networks (LSTM). We use a time window approach to extract temporal information from time-series data in a source domain with observed RUL values and a target domain containing only sensor information. We propose a Domain Adversarial Neural Network (DANN) approach to learn domain-invariant features that can be used to predict the RUL in the target domain. The experimental results show that the proposed method can provide more reliable RUL predictions under datasets with different operating conditions and fault modes. These results suggest that the proposed method offers a promising approach to performing domain adaptation in practical PHM applications.