 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated decision-making for dynamic task assignment at scale
Apr 28, 2025The Dynamic Task Assignment Problem (DTAP) concerns matching resources to tasks in real time while minimizing some objectives, like resource costs or task cycle time. In this work, we consider a DTAP variant where every task is a case composed of a stochastic sequence of activities. The DTAP, in this case, involves the decision of which employee to assign to which activity to process requests as quickly as possible. In recent years, Deep Reinforcement Learning (DRL) has emerged as a promising tool for tackling this DTAP variant, but most research is limited to solving small-scale, synthetic problems, neglecting the challenges posed by real-world use cases. To bridge this gap, this work proposes a DRL-based Decision Support System (DSS) for real-world scale DTAPS. To this end, we introduce a DRL agent with two novel elements: a graph structure for observations and actions that can effectively represent any DTAP and a reward function that is provably equivalent to the objective of minimizing the average cycle time of tasks. The combination of these two novelties allows the agent to learn effective and generalizable assignment policies for real-world scale DTAPs. The proposed DSS is evaluated on five DTAP instances whose parameters are extracted from real-world logs through process mining. The experimental evaluation shows how the proposed DRL agent matches or outperforms the best baseline in all DTAP instances and generalizes on different time horizons and across instances.
Classical and Deep Reinforcement Learning Inventory Control Policies for Pharmaceutical Supply Chains with Perishability and Non-Stationarity
Jan 18, 2025We study inventory control policies for pharmaceutical supply chains, addressing challenges such as perishability, yield uncertainty, and non-stationary demand, combined with batching constraints, lead times, and lost sales. Collaborating with Bristol-Myers Squibb (BMS), we develop a realistic case study incorporating these factors and benchmark three policies--order-up-to (OUT), projected inventory level (PIL), and deep reinforcement learning (DRL) using the proximal policy optimization (PPO) algorithm--against a BMS baseline based on human expertise. We derive and validate bounds-based procedures for optimizing OUT and PIL policy parameters and propose a methodology for estimating projected inventory levels, which are also integrated into the DRL policy with demand forecasts to improve decision-making under non-stationarity. Compared to a human-driven policy, which avoids lost sales through higher holding costs, all three implemented policies achieve lower average costs but exhibit greater cost variability. While PIL demonstrates robust and consistent performance, OUT struggles under high lost sales costs, and PPO excels in complex and variable scenarios but requires significant computational effort. The findings suggest that while DRL shows potential, it does not outperform classical policies in all numerical experiments, highlighting 1) the need to integrate diverse policies to manage pharmaceutical challenges effectively, based on the current state-of-the-art, and 2) that practical problems in this domain seem to lack a single policy class that yields universally acceptable performance.
Integrated trucks assignment and scheduling problem with mixed service mode docks: A Q-learning based adaptive large neighborhood search algorithm
Dec 12, 2024Mixed service mode docks enhance efficiency by flexibly handling both loading and unloading trucks in warehouses. However, existing research often predetermines the number and location of these docks prior to planning truck assignment and sequencing. This paper proposes a new model integrating dock mode decision, truck assignment, and scheduling, thus enabling adaptive dock mode arrangements. Specifically, we introduce a Q-learning-based adaptive large neighborhood search (Q-ALNS) algorithm to address the integrated problem. The algorithm adjusts dock modes via perturbation operators, while truck assignment and scheduling are solved using destroy and repair local search operators. Q-learning adaptively selects these operators based on their performance history and future gains, employing the epsilon-greedy strategy. Extensive experimental results and statistical analysis indicate that the Q-ALNS benefits from efficient operator combinations and its adaptive mechanism, consistently outperforming benchmark algorithms in terms of optimality gap and Pareto front discovery. In comparison to the predetermined service mode, our adaptive strategy results in lower average tardiness and makespan, highlighting its superior adaptability to varying demands.
Zero-shot Generalization in Inventory Management: Train, then Estimate and Decide
Nov 01, 2024Deploying deep reinforcement learning (DRL) in real-world inventory management presents challenges, including dynamic environments and uncertain problem parameters, e.g. demand and lead time distributions. These challenges highlight a research gap, suggesting a need for a unifying framework to model and solve sequential decision-making under parameter uncertainty. We address this by exploring an underexplored area of DRL for inventory management: training generally capable agents (GCAs) under zero-shot generalization (ZSG). Here, GCAs are advanced DRL policies designed to handle a broad range of sampled problem instances with diverse inventory challenges. ZSG refers to the ability to successfully apply learned policies to unseen instances with unknown parameters without retraining. We propose a unifying Super-Markov Decision Process formulation and the Train, then Estimate and Decide (TED) framework to train and deploy a GCA tailored to inventory management applications. The TED framework consists of three phases: training a GCA on varied problem instances, continuously estimating problem parameters during deployment, and making decisions based on these estimates. Applied to periodic review inventory problems with lost sales, cyclic demand patterns, and stochastic lead times, our trained agent, the Generally Capable Lost Sales Network (GC-LSN) consistently outperforms well-known traditional policies when problem parameters are known. Moreover, under conditions where demand and/or lead time distributions are initially unknown and must be estimated, we benchmark against online learning methods that provide worst-case performance guarantees. Our GC-LSN policy, paired with the Kaplan-Meier estimator, is demonstrated to complement these methods by providing superior empirical performance.
Action-Evolution Petri Nets: a Framework for Modeling and Solving Dynamic Task Assignment Problems
Jun 09, 2023



Dynamic task assignment involves assigning arriving tasks to a limited number of resources in order to minimize the overall cost of the assignments. To achieve optimal task assignment, it is necessary to model the assignment problem first. While there exist separate formalisms, specifically Markov Decision Processes and (Colored) Petri Nets, to model, execute, and solve different aspects of the problem, there is no integrated modeling technique. To address this gap, this paper proposes Action-Evolution Petri Nets (A-E PN) as a framework for modeling and solving dynamic task assignment problems. A-E PN provides a unified modeling technique that can represent all elements of dynamic task assignment problems. Moreover, A-E PN models are executable, which means they can be used to learn close-to-optimal assignment policies through Reinforcement Learning (RL) without additional modeling effort. To evaluate the framework, we define a taxonomy of archetypical assignment problems. We show for three cases that A-E PN can be used to learn close-to-optimal assignment policies. Our results suggest that A-E PN can be used to model and solve a broad range of dynamic task assignment problems.
Policies for the Dynamic Traveling Maintainer Problem with Alerts
May 31, 2021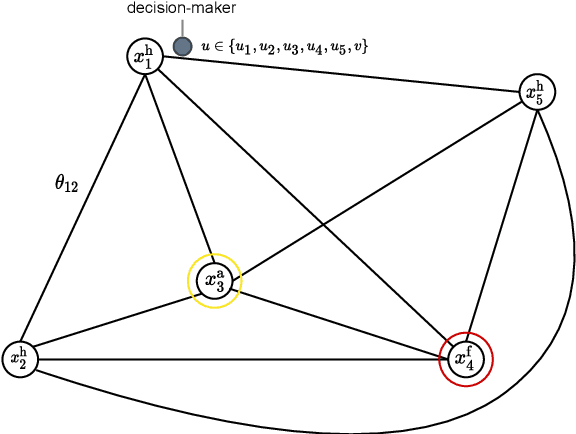
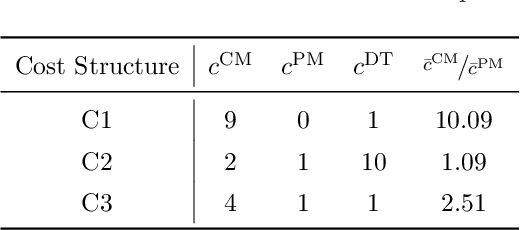
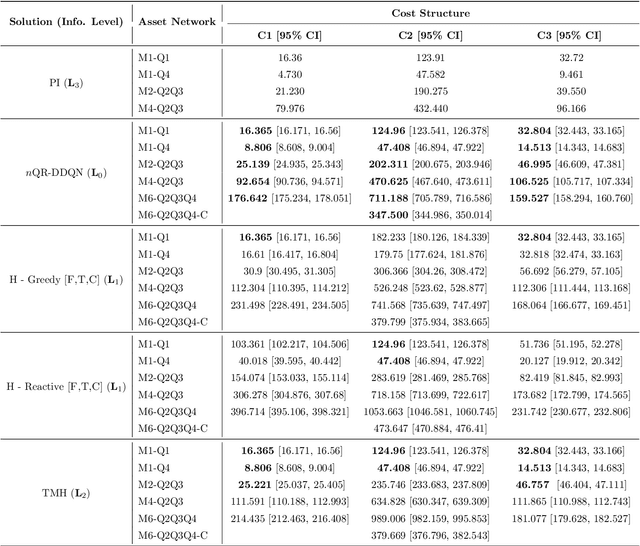
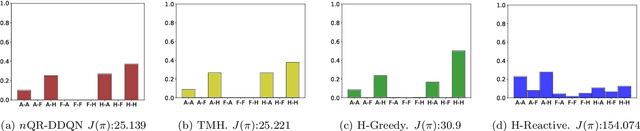
Companies require modern capital assets such as wind turbines, trains and hospital equipment to experience minimal downtime. Ideally, assets are maintained right before failure to ensure maximum availability at minimum maintenance costs. To this end, two challenges arise: failure times of assets are unknown a priori and assets can be part of a larger asset network. Nowadays, it is common for assets to be equipped with real-time monitoring that emits alerts, typically triggered by the first signs of degradation. Thus, it becomes crucial to plan maintenance considering information received via alerts, asset locations and maintenance costs. This problem is referred to as the Dynamic Traveling Maintainer Problem with Alerts (DTMPA). We propose a modeling framework for the DTMPA, where the alerts are early and imperfect indicators of failures. The objective is to minimize discounted maintenance costs accrued over an infinite time horizon. We propose three methods to solve this problem, leveraging different information levels from the alert signals. The proposed methods comprise various greedy heuristics that rank assets based on proximity, urgency and economic risk; a Traveling Maintainer Heuristic employing combinatorial optimization to optimize near-future costs; a Deep Reinforcement Learning (DRL) method trained to minimize the long-term costs using exclusively the history of alerts. In a simulated environment, all methods can approximate optimal policies with access to perfect condition information for small asset networks. For larger networks, where computing the optimal policy is intractable, the proposed methods yield competitive maintenance policies, with DRL consistently achieving the lowest costs.
Model-based controlled learning of MDP policies with an application to lost-sales inventory control
Nov 30, 2020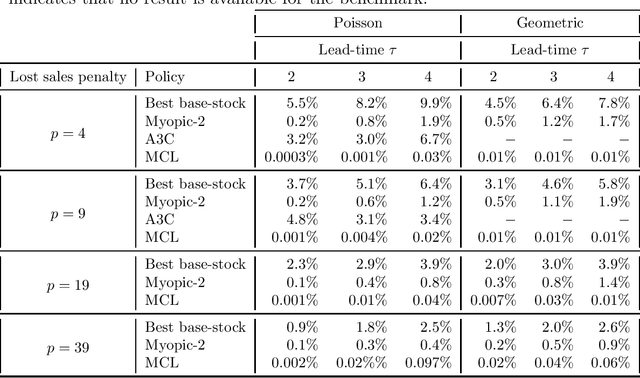
Recent literature established that neural networks can represent good MDP policies across a range of stochastic dynamic models in supply chain and logistics. To overcome limitations of the model-free algorithms typically employed to learn/find such neural network policies, a model-based algorithm is proposed that incorporates variance reduction techniques. For the classical lost sales inventory model, the algorithm learns neural network policies that are superior to those learned using model-free algorithms, while also outperforming heuristic benchmarks. The algorithm may be an interesting candidate to apply to other stochastic dynamic problems in supply chain and logistics.