 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovery of Decision Synchronization Patterns from Event Logs
Mar 20, 2026Synchronizing decisions between running cases in business processes facilitates fair and efficient use of resources, helps prioritize the most valuable cases, and prevents unnecessary waiting. Consequently, decision synchronization patterns are regularly built into processes, in the form of mechanisms that temporarily delay one case to favor another. These decision mechanisms therefore consider properties of multiple cases at once, rather than just the properties of a single case; an aspect that is rarely addressed by current process discovery techniques. To address this gap, this paper proposes an approach for discovering decision synchronization patterns inspired by supply chain processes. These decision synchronization patterns take the form of specific process constructs combined with a constraint that determines which particular case to execute. We describe, formalize and demonstrate how the constraint for four such patterns can be discovered. We evaluate our approach in two artificial scenarios. First, with four separate process models each containing a single decision synchronization pattern, i.e., we demonstrate that our approach can discover every type of pattern when only this one type is present. Second, we consider a process model containing all four decision synchronization patterns to show generalizability of the approach to more complex problems. For both scenarios, we could reliably retrieve the expected patterns.
A Reference Model and Patterns for Production Event Data Enrichment
Jun 16, 2025With the advent of digital transformation, organisations are increasingly generating large volumes of data through the execution of various processes across disparate systems. By integrating data from these heterogeneous sources, it becomes possible to derive new insights essential for tasks such as monitoring and analysing process performance. Typically, this information is extracted during a data pre-processing or engineering phase. However, this step is often performed in an ad-hoc manner and is time-consuming and labour-intensive. To streamline this process, we introduce a reference model and a collection of patterns designed to enrich production event data. The reference model provides a standard way for storing and extracting production event data. The patterns describe common information extraction tasks and how such tasks can be automated effectively. The reference model is developed by combining the ISA-95 industry standard with the Event Knowledge Graph formalism. The patterns are developed based on empirical observations from event data sets originating in manufacturing processes and are formalised using the reference model. We evaluate the relevance and applicability of these patterns by demonstrating their application to use cases.
Automated decision-making for dynamic task assignment at scale
Apr 28, 2025The Dynamic Task Assignment Problem (DTAP) concerns matching resources to tasks in real time while minimizing some objectives, like resource costs or task cycle time. In this work, we consider a DTAP variant where every task is a case composed of a stochastic sequence of activities. The DTAP, in this case, involves the decision of which employee to assign to which activity to process requests as quickly as possible. In recent years, Deep Reinforcement Learning (DRL) has emerged as a promising tool for tackling this DTAP variant, but most research is limited to solving small-scale, synthetic problems, neglecting the challenges posed by real-world use cases. To bridge this gap, this work proposes a DRL-based Decision Support System (DSS) for real-world scale DTAPS. To this end, we introduce a DRL agent with two novel elements: a graph structure for observations and actions that can effectively represent any DTAP and a reward function that is provably equivalent to the objective of minimizing the average cycle time of tasks. The combination of these two novelties allows the agent to learn effective and generalizable assignment policies for real-world scale DTAPs. The proposed DSS is evaluated on five DTAP instances whose parameters are extracted from real-world logs through process mining. The experimental evaluation shows how the proposed DRL agent matches or outperforms the best baseline in all DTAP instances and generalizes on different time horizons and across instances.
A Rollout-Based Algorithm and Reward Function for Efficient Resource Allocation in Business Processes
Apr 15, 2025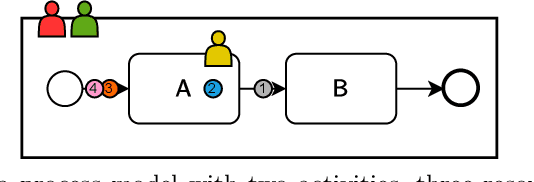
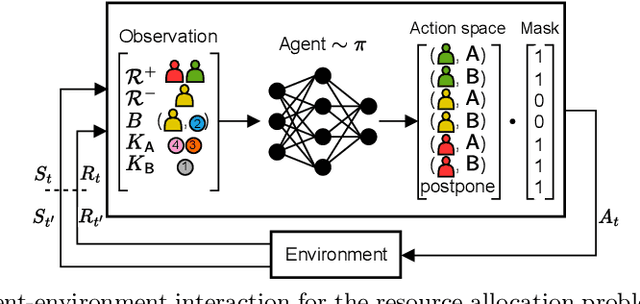

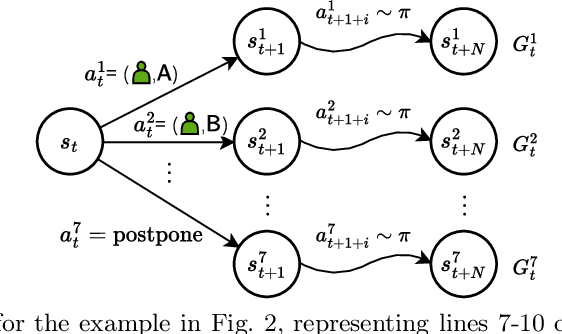
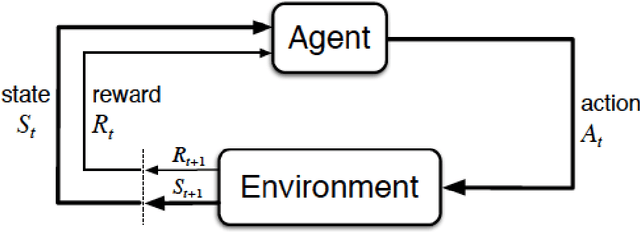
Resource allocation plays a critical role in minimizing cycle time and improving the efficiency of business processes. Recently, Deep Reinforcement Learning (DRL) has emerged as a powerful tool to optimize resource allocation policies in business processes. In the DRL framework, an agent learns a policy through interaction with the environment, guided solely by reward signals that indicate the quality of its decisions. However, existing algorithms are not suitable for dynamic environments such as business processes. Furthermore, existing DRL-based methods rely on engineered reward functions that approximate the desired objective, but a misalignment between reward and objective can lead to undesired decisions or suboptimal policies. To address these issues, we propose a rollout-based DRL algorithm and a reward function to optimize the objective directly. Our algorithm iteratively improves the policy by evaluating execution trajectories following different actions. Our reward function directly decomposes the objective function of minimizing the mean cycle time. Maximizing our reward function guarantees that the objective function is minimized without requiring extensive reward engineering. The results show that our method consistently learns the optimal policy in all six evaluated business processes, outperforming the state-of-the-art algorithm that can only learn the optimal policy in two of the evaluated processes.
Zero-shot Generalization in Inventory Management: Train, then Estimate and Decide
Nov 01, 2024Deploying deep reinforcement learning (DRL) in real-world inventory management presents challenges, including dynamic environments and uncertain problem parameters, e.g. demand and lead time distributions. These challenges highlight a research gap, suggesting a need for a unifying framework to model and solve sequential decision-making under parameter uncertainty. We address this by exploring an underexplored area of DRL for inventory management: training generally capable agents (GCAs) under zero-shot generalization (ZSG). Here, GCAs are advanced DRL policies designed to handle a broad range of sampled problem instances with diverse inventory challenges. ZSG refers to the ability to successfully apply learned policies to unseen instances with unknown parameters without retraining. We propose a unifying Super-Markov Decision Process formulation and the Train, then Estimate and Decide (TED) framework to train and deploy a GCA tailored to inventory management applications. The TED framework consists of three phases: training a GCA on varied problem instances, continuously estimating problem parameters during deployment, and making decisions based on these estimates. Applied to periodic review inventory problems with lost sales, cyclic demand patterns, and stochastic lead times, our trained agent, the Generally Capable Lost Sales Network (GC-LSN) consistently outperforms well-known traditional policies when problem parameters are known. Moreover, under conditions where demand and/or lead time distributions are initially unknown and must be estimated, we benchmark against online learning methods that provide worst-case performance guarantees. Our GC-LSN policy, paired with the Kaplan-Meier estimator, is demonstrated to complement these methods by providing superior empirical performance.
Interactive Multi Interest Process Pattern Discovery
Aug 28, 2023Process pattern discovery methods (PPDMs) aim at identifying patterns of interest to users. Existing PPDMs typically are unsupervised and focus on a single dimension of interest, such as discovering frequent patterns. We present an interactive multi interest driven framework for process pattern discovery aimed at identifying patterns that are optimal according to a multi-dimensional analysis goal. The proposed approach is iterative and interactive, thus taking experts knowledge into account during the discovery process. The paper focuses on a concrete analysis goal, i.e., deriving process patterns that affect the process outcome. We evaluate the approach on real world event logs in both interactive and fully automated settings. The approach extracted meaningful patterns validated by expert knowledge in the interactive setting. Patterns extracted in the automated settings consistently led to prediction performance comparable to or better than patterns derived considering single interest dimensions without requiring user defined thresholds.
Action-Evolution Petri Nets: a Framework for Modeling and Solving Dynamic Task Assignment Problems
Jun 09, 2023



Dynamic task assignment involves assigning arriving tasks to a limited number of resources in order to minimize the overall cost of the assignments. To achieve optimal task assignment, it is necessary to model the assignment problem first. While there exist separate formalisms, specifically Markov Decision Processes and (Colored) Petri Nets, to model, execute, and solve different aspects of the problem, there is no integrated modeling technique. To address this gap, this paper proposes Action-Evolution Petri Nets (A-E PN) as a framework for modeling and solving dynamic task assignment problems. A-E PN provides a unified modeling technique that can represent all elements of dynamic task assignment problems. Moreover, A-E PN models are executable, which means they can be used to learn close-to-optimal assignment policies through Reinforcement Learning (RL) without additional modeling effort. To evaluate the framework, we define a taxonomy of archetypical assignment problems. We show for three cases that A-E PN can be used to learn close-to-optimal assignment policies. Our results suggest that A-E PN can be used to model and solve a broad range of dynamic task assignment problems.
Online Multimodal Transportation Planning using Deep Reinforcement Learning
May 18, 2021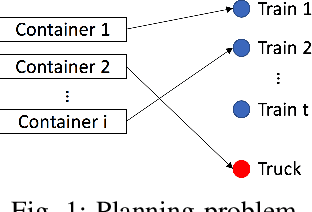
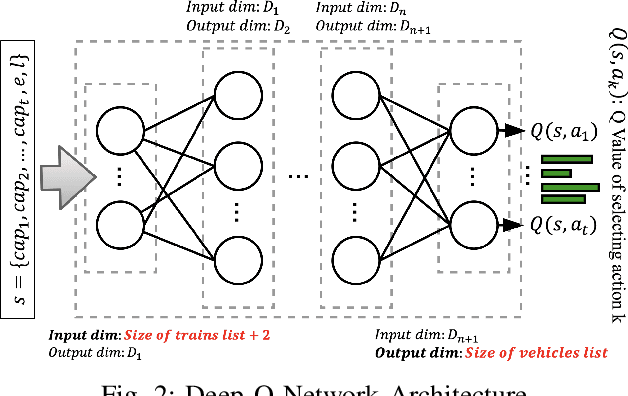
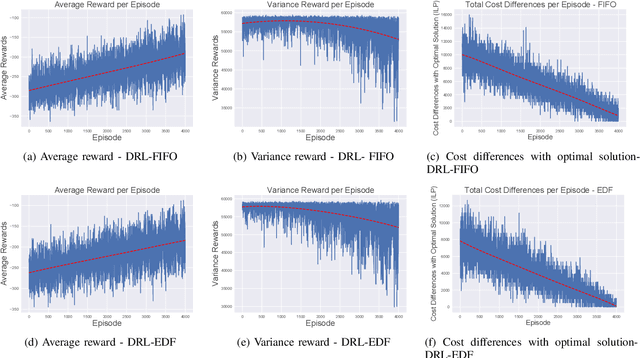
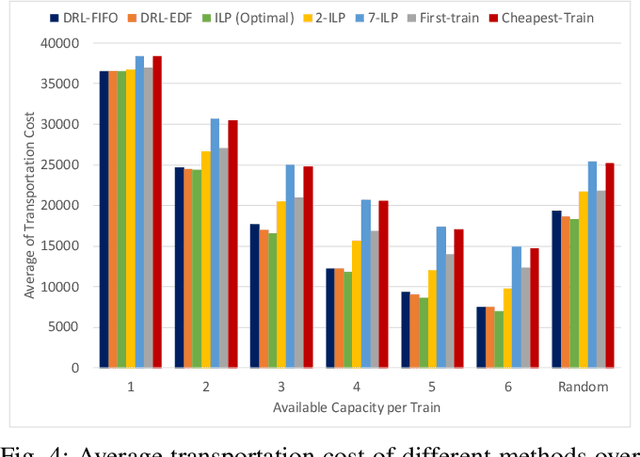
In this paper we propose a Deep Reinforcement Learning approach to solve a multimodal transportation planning problem, in which containers must be assigned to a truck or to trains that will transport them to their destination. While traditional planning methods work "offline" (i.e., they take decisions for a batch of containers before the transportation starts), the proposed approach is "online", in that it can take decisions for individual containers, while transportation is being executed. Planning transportation online helps to effectively respond to unforeseen events that may affect the original transportation plan, thus supporting companies in lowering transportation costs. We implemented different container selection heuristics within the proposed Deep Reinforcement Learning algorithm and we evaluated its performance for each heuristic using data that simulate a realistic scenario, designed on the basis of a real case study at a logistics company. The experimental results revealed that the proposed method was able to learn effective patterns of container assignment. It outperformed tested competitors in terms of total transportation costs and utilization of train capacity by 20.48% to 55.32% for the cost and by 7.51% to 20.54% for the capacity. Furthermore, it obtained results within 2.7% for the cost and 0.72% for the capacity of the optimal solution generated by an Integer Linear Programming solver in an offline setting.
Solving the Order Batching and Sequencing Problem using Deep Reinforcement Learning
Jun 16, 2020
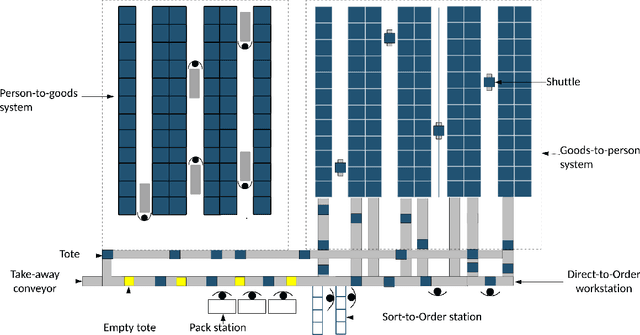
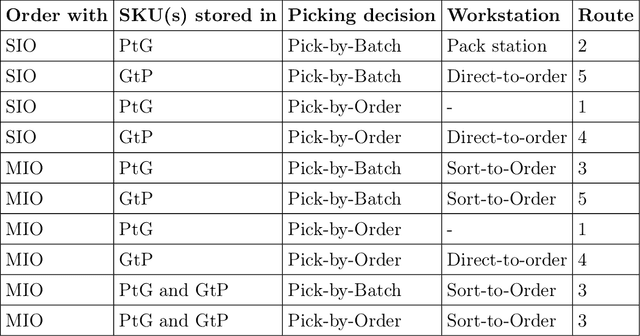
In e-commerce markets, on time delivery is of great importance to customer satisfaction. In this paper, we present a Deep Reinforcement Learning (DRL) approach for deciding how and when orders should be batched and picked in a warehouse to minimize the number of tardy orders. In particular, the technique facilitates making decisions on whether an order should be picked individually (pick-by-order) or picked in a batch with other orders (pick-by-batch), and if so with which other orders. We approach the problem by formulating it as a semi-Markov decision process and develop a vector-based state representation that includes the characteristics of the warehouse system. This allows us to create a deep reinforcement learning solution that learns a strategy by interacting with the environment and solve the problem with a proximal policy optimization algorithm. We evaluate the performance of the proposed DRL approach by comparing it with several batching and sequencing heuristics in different problem settings. The results show that the DRL approach is able to develop a strategy that produces consistent, good solutions and performs better than the proposed heuristics.