 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reference Model and Patterns for Production Event Data Enrichment
Jun 16, 2025With the advent of digital transformation, organisations are increasingly generating large volumes of data through the execution of various processes across disparate systems. By integrating data from these heterogeneous sources, it becomes possible to derive new insights essential for tasks such as monitoring and analysing process performance. Typically, this information is extracted during a data pre-processing or engineering phase. However, this step is often performed in an ad-hoc manner and is time-consuming and labour-intensive. To streamline this process, we introduce a reference model and a collection of patterns designed to enrich production event data. The reference model provides a standard way for storing and extracting production event data. The patterns describe common information extraction tasks and how such tasks can be automated effectively. The reference model is developed by combining the ISA-95 industry standard with the Event Knowledge Graph formalism. The patterns are developed based on empirical observations from event data sets originating in manufacturing processes and are formalised using the reference model. We evaluate the relevance and applicability of these patterns by demonstrating their application to use cases.
A Rollout-Based Algorithm and Reward Function for Efficient Resource Allocation in Business Processes
Apr 15, 2025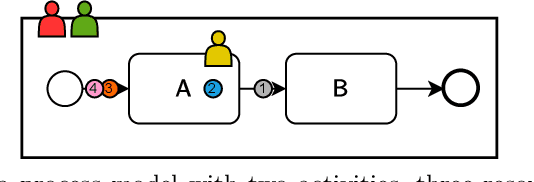
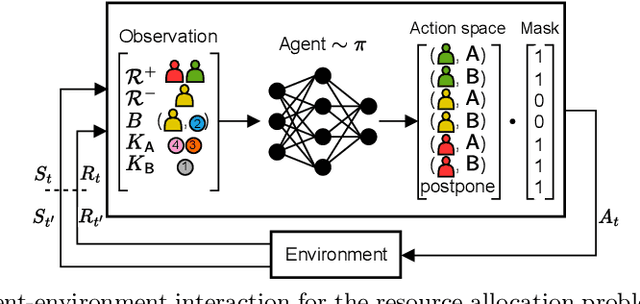

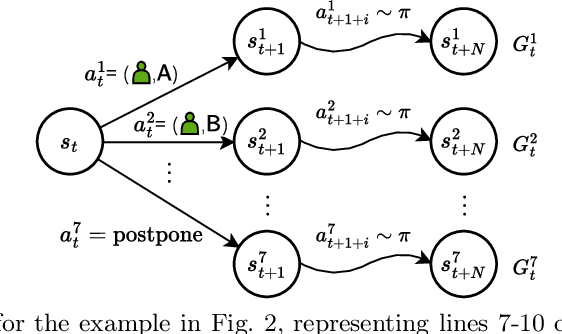
Resource allocation plays a critical role in minimizing cycle time and improving the efficiency of business processes. Recently, Deep Reinforcement Learning (DRL) has emerged as a powerful tool to optimize resource allocation policies in business processes. In the DRL framework, an agent learns a policy through interaction with the environment, guided solely by reward signals that indicate the quality of its decisions. However, existing algorithms are not suitable for dynamic environments such as business processes. Furthermore, existing DRL-based methods rely on engineered reward functions that approximate the desired objective, but a misalignment between reward and objective can lead to undesired decisions or suboptimal policies. To address these issues, we propose a rollout-based DRL algorithm and a reward function to optimize the objective directly. Our algorithm iteratively improves the policy by evaluating execution trajectories following different actions. Our reward function directly decomposes the objective function of minimizing the mean cycle time. Maximizing our reward function guarantees that the objective function is minimized without requiring extensive reward engineering. The results show that our method consistently learns the optimal policy in all six evaluated business processes, outperforming the state-of-the-art algorithm that can only learn the optimal policy in two of the evaluated processes.