 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorking My Way Back to You: Resource-Centric Next-Activity Prediction
Aug 26, 2025Predictive Process Monitoring (PPM) aims to train models that forecast upcoming events in process executions. These predictions support early bottleneck detection, improved scheduling, proactive interventions, and timely communication with stakeholders. While existing research adopts a control-flow perspective, we investigate next-activity prediction from a resource-centric viewpoint, which offers additional benefits such as improved work organization, workload balancing, and capacity forecasting. Although resource information has been shown to enhance tasks such as process performance analysis, its role in next-activity prediction remains unexplored. In this study, we evaluate four prediction models and three encoding strategies across four real-life datasets. Compared to the baseline, our results show that LightGBM and Transformer models perform best with an encoding based on 2-gram activity transitions, while Random Forest benefits most from an encoding that combines 2-gram transitions and activity repetition features. This combined encoding also achieves the highest average accuracy. This resource-centric approach could enable smarter resource allocation, strategic workforce planning, and personalized employee support by analyzing individual behavior rather than case-level progression. The findings underscore the potential of resource-centric next-activity prediction, opening up new venues for research on PPM.
From Chaos to Automation: Enabling the Use of Unstructured Data for Robotic Process Automation
Jul 15, 2025The growing volume of unstructured data within organizations poses significant challenges for data analysis and process automation. Unstructured data, which lacks a predefined format, encompasses various forms such as emails, reports, and scans. It is estimated to constitute approximately 80% of enterprise data. Despite the valuable insights it can offer, extracting meaningful information from unstructured data is more complex compared to structured data. Robotic Process Automation (RPA) has gained popularity for automating repetitive tasks, improving efficiency, and reducing errors. However, RPA is traditionally reliant on structured data, limiting its application to processes involving unstructured documents. This study addresses this limitation by developing the UNstructured Document REtrieval SyStem (UNDRESS), a system that uses fuzzy regular expressions, techniques for natural language processing, and large language models to enable RPA platforms to effectively retrieve information from unstructured documents. The research involved the design and development of a prototype system, and its subsequent evaluation based on text extraction and information retrieval performance. The results demonstrate the effectiveness of UNDRESS in enhancing RPA capabilities for unstructured data, providing a significant advancement in the field. The findings suggest that this system could facilitate broader RPA adoption across processes traditionally hindered by unstructured data, thereby improving overall business process efficiency.
FoldA: Computing Partial-Order Alignments Using Directed Net Unfoldings
Jun 10, 2025Conformance checking is a fundamental task of process mining, which quantifies the extent to which the observed process executions match a normative process model. The state-of-the-art approaches compute alignments by exploring the state space formed by the synchronous product of the process model and the trace. This often leads to state space explosion, particularly when the model exhibits a high degree of choice and concurrency. Moreover, as alignments inherently impose a sequential structure, they fail to fully represent the concurrent behavior present in many real-world processes. To address these limitations, this paper proposes a new technique for computing partial-order alignments {on the fly using directed Petri net unfoldings, named FoldA. We evaluate our technique on 485 synthetic model-log pairs and compare it against Astar- and Dijkstra-alignments on 13 real-life model-log pairs and 6 benchmark pairs. The results show that our unfolding alignment, although it requires more computation time, generally reduces the number of queued states and provides a more accurate representation of concurrency.
HOEG: A New Approach for Object-Centric Predictive Process Monitoring
Apr 08, 2024



Predictive Process Monitoring focuses on predicting future states of ongoing process executions, such as forecasting the remaining time. Recent developments in Object-Centric Process Mining have enriched event data with objects and their explicit relations between events. To leverage this enriched data, we propose the Heterogeneous Object Event Graph encoding (HOEG), which integrates events and objects into a graph structure with diverse node types. It does so without aggregating object features, thus creating a more nuanced and informative representation. We then adopt a heterogeneous Graph Neural Network architecture, which incorporates these diverse object features in prediction tasks. We evaluate the performance and scalability of HOEG in predicting remaining time, benchmarking it against two established graph-based encodings and two baseline models. Our evaluation uses three Object-Centric Event Logs (OCELs), including one from a real-life process at a major Dutch financial institution. The results indicate that HOEG competes well with existing models and surpasses them when OCELs contain informative object attributes and event-object interactions.
Measuring the Stability of Process Outcome Predictions in Online Settings
Oct 13, 2023Predictive Process Monitoring aims to forecast the future progress of process instances using historical event data. As predictive process monitoring is increasingly applied in online settings to enable timely interventions, evaluating the performance of the underlying models becomes crucial for ensuring their consistency and reliability over time. This is especially important in high risk business scenarios where incorrect predictions may have severe consequences. However, predictive models are currently usually evaluated using a single, aggregated value or a time-series visualization, which makes it challenging to assess their performance and, specifically, their stability over time. This paper proposes an evaluation framework for assessing the stability of models for online predictive process monitoring. The framework introduces four performance meta-measures: the frequency of significant performance drops, the magnitude of such drops, the recovery rate, and the volatility of performance. To validate this framework, we applied it to two artificial and two real-world event logs. The results demonstrate that these meta-measures facilitate the comparison and selection of predictive models for different risk-taking scenarios. Such insights are of particular value to enhance decision-making in dynamic business environments.
Using Reinforcement Learning to Optimize Responses in Care Processes: A Case Study on Aggression Incidents
Oct 02, 2023Previous studies have used prescriptive process monitoring to find actionable policies in business processes and conducted case studies in similar domains, such as the loan application process and the traffic fine process. However, care processes tend to be more dynamic and complex. For example, at any stage of a care process, a multitude of actions is possible. In this paper, we follow the reinforcement approach and train a Markov decision process using event data from a care process. The goal was to find optimal policies for staff members when clients are displaying any type of aggressive behavior. We used the reinforcement learning algorithms Q-learning and SARSA to find optimal policies. Results showed that the policies derived from these algorithms are similar to the most frequent actions currently used but provide the staff members with a few more options in certain situations.
Interactive Multi Interest Process Pattern Discovery
Aug 28, 2023Process pattern discovery methods (PPDMs) aim at identifying patterns of interest to users. Existing PPDMs typically are unsupervised and focus on a single dimension of interest, such as discovering frequent patterns. We present an interactive multi interest driven framework for process pattern discovery aimed at identifying patterns that are optimal according to a multi-dimensional analysis goal. The proposed approach is iterative and interactive, thus taking experts knowledge into account during the discovery process. The paper focuses on a concrete analysis goal, i.e., deriving process patterns that affect the process outcome. We evaluate the approach on real world event logs in both interactive and fully automated settings. The approach extracted meaningful patterns validated by expert knowledge in the interactive setting. Patterns extracted in the automated settings consistently led to prediction performance comparable to or better than patterns derived considering single interest dimensions without requiring user defined thresholds.
CREATED: Generating Viable Counterfactual Sequences for Predictive Process Analytics
Mar 28, 2023Predictive process analytics focuses on predicting future states, such as the outcome of running process instances. These techniques often use machine learning models or deep learning models (such as LSTM) to make such predictions. However, these deep models are complex and difficult for users to understand. Counterfactuals answer ``what-if'' questions, which are used to understand the reasoning behind the predictions. For example, what if instead of emailing customers, customers are being called? Would this alternative lead to a different outcome? Current methods to generate counterfactual sequences either do not take the process behavior into account, leading to generating invalid or infeasible counterfactual process instances, or heavily rely on domain knowledge. In this work, we propose a general framework that uses evolutionary methods to generate counterfactual sequences. Our framework does not require domain knowledge. Instead, we propose to train a Markov model to compute the feasibility of generated counterfactual sequences and adapt three other measures (delta in outcome prediction, similarity, and sparsity) to ensure their overall viability. The evaluation shows that we generate viable counterfactual sequences, outperform baseline methods in viability, and yield similar results when compared to the state-of-the-art method that requires domain knowledge.
The Analysis of Online Event Streams: Predicting the Next Activity for Anomaly Detection
Mar 17, 2022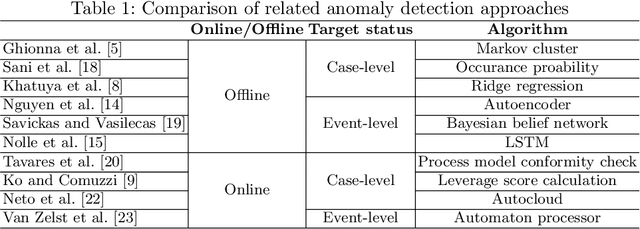

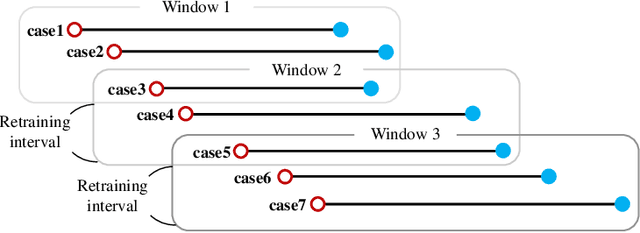

Anomaly detection in process mining focuses on identifying anomalous cases or events in process executions. The resulting diagnostics are used to provide measures to prevent fraudulent behavior, as well as to derive recommendations for improving process compliance and security. Most existing techniques focus on detecting anomalous cases in an offline setting. However, to identify potential anomalies in a timely manner and take immediate countermeasures, it is necessary to detect event-level anomalies online, in real-time. In this paper, we propose to tackle the online event anomaly detection problem using next-activity prediction methods. More specifically, we investigate the use of both ML models (such as RF and XGBoost) and deep models (such as LSTM) to predict the probabilities of next-activities and consider the events predicted unlikely as anomalies. We compare these predictive anomaly detection methods to four classical unsupervised anomaly detection approaches (such as Isolation forest and LOF) in the online setting. Our evaluation shows that the proposed method using ML models tends to outperform the one using a deep model, while both methods outperform the classical unsupervised approaches in detecting anomalous events.
Discovering Hierarchical Processes Using Flexible Activity Trees for Event Abstraction
Oct 16, 2020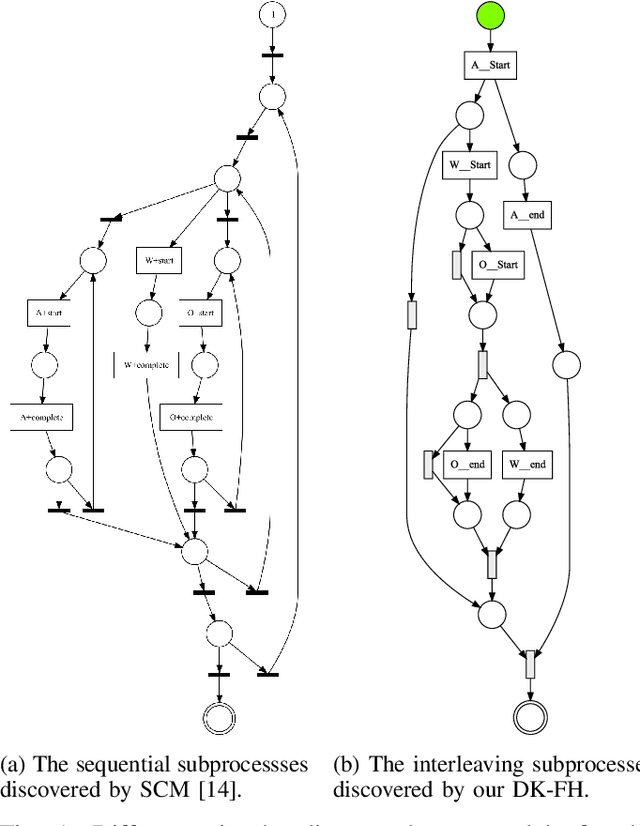
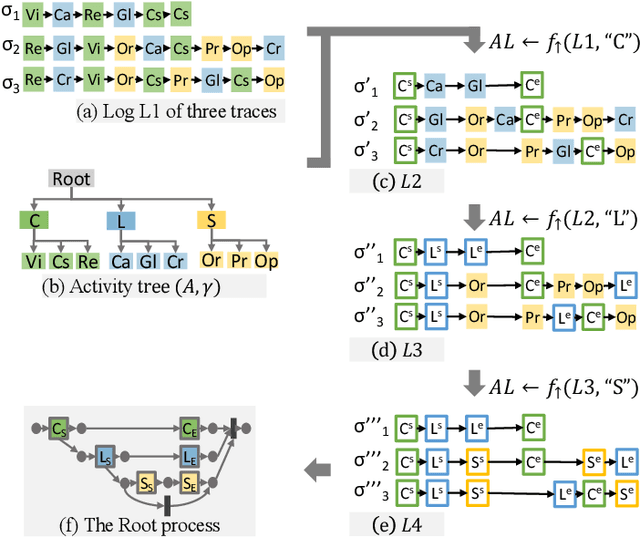


Processes, such as patient pathways, can be very complex, comprising of hundreds of activities and dozens of interleaved subprocesses. While existing process discovery algorithms have proven to construct models of high quality on clean logs of structured processes, it still remains a challenge when the algorithms are being applied to logs of complex processes. The creation of a multi-level, hierarchical representation of a process can help to manage this complexity. However, current approaches that pursue this idea suffer from a variety of weaknesses. In particular, they do not deal well with interleaving subprocesses. In this paper, we propose FlexHMiner, a three-step approach to discover processes with multi-level interleaved subprocesses. We implemented FlexHMiner in the open source Process Mining toolkit ProM. We used seven real-life logs to compare the qualities of hierarchical models discovered using domain knowledge, random clustering, and flat approaches. Our results indicate that the hierarchical process models that the FlexHMiner generates compare favorably to approaches that do not exploit hierarchy.