 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Assistance Networks: Rediscovering Hyperbolic Tangents in RL
Jun 13, 2024Activation functions are one of the key components of a neural network. The most commonly used activation functions can be classed into the category of continuously differentiable (e.g. tanh) and linear-unit functions (e.g. ReLU), both having their own strengths and drawbacks with respect to downstream performance and representation capacity through learning (e.g. measured by the number of dead neurons and the effective rank). In reinforcement learning, the performance of continuously differentiable activations often falls short as compared to linear-unit functions. From the perspective of the activations in the last hidden layer, this paper provides insights regarding this sub-optimality and explores how activation functions influence the occurrence of dead neurons and the magnitude of the effective rank. Additionally, a novel neural architecture is proposed that leverages the product of independent activation values. In the Atari domain, we show faster learning, a reduction in dead neurons and increased effective rank.
A Machine Learning Approach for Simultaneous Demapping of QAM and APSK Constellations
May 16, 2024



As telecommunication systems evolve to meet increasing demands, integrating deep neural networks (DNNs) has shown promise in enhancing performance. However, the trade-off between accuracy and flexibility remains challenging when replacing traditional receivers with DNNs. This paper introduces a novel probabilistic framework that allows a single DNN demapper to demap multiple QAM and APSK constellations simultaneously. We also demonstrate that our framework allows exploiting hierarchical relationships in families of constellations. The consequence is that we need fewer neural network outputs to encode the same function without an increase in Bit Error Rate (BER). Our simulation results confirm that our approach approaches the optimal demodulation error bound under an Additive White Gaussian Noise (AWGN) channel for multiple constellations. Thereby, we address multiple important issues in making DNNs flexible enough for practical use as receivers.
Unveiling the Potential: Harnessing Deep Metric Learning to Circumvent Video Streaming Encryption
May 16, 2024Encryption on the internet with the shift to HTTPS has been an important step to improve the privacy of internet users. However, there is an increasing body of work about extracting information from encrypted internet traffic without having to decrypt it. Such attacks bypass security guarantees assumed to be given by HTTPS and thus need to be understood. Prior works showed that the variable bitrates of video streams are sufficient to identify which video someone is watching. These works generally have to make trade-offs in aspects such as accuracy, scalability, robustness, etc. These trade-offs complicate the practical use of these attacks. To that end, we propose a deep metric learning framework based on the triplet loss method. Through this framework, we achieve robust, generalisable, scalable and transferable encrypted video stream detection. First, the triplet loss is better able to deal with video streams not seen during training. Second, our approach can accurately classify videos not seen during training. Third, we show that our method scales well to a dataset of over 1000 videos. Finally, we show that a model trained on video streams over Chrome can also classify streams over Firefox. Our results suggest that this side-channel attack is more broadly applicable than originally thought. We provide our code alongside a diverse and up-to-date dataset for future research.
Revisiting the Robustness of the Minimum Error Entropy Criterion: A Transfer Learning Case Study
Jul 25, 2023Coping with distributional shifts is an important part of transfer learning methods in order to perform well in real-life tasks. However, most of the existing approaches in this area either focus on an ideal scenario in which the data does not contain noises or employ a complicated training paradigm or model design to deal with distributional shifts. In this paper, we revisit the robustness of the minimum error entropy (MEE) criterion, a widely used objective in statistical signal processing to deal with non-Gaussian noises, and investigate its feasibility and usefulness in real-life transfer learning regression tasks, where distributional shifts are common. Specifically, we put forward a new theoretical result showing the robustness of MEE against covariate shift. We also show that by simply replacing the mean squared error (MSE) loss with the MEE on basic transfer learning algorithms such as fine-tuning and linear probing, we can achieve competitive performance with respect to state-of-the-art transfer learning algorithms. We justify our arguments on both synthetic data and 5 real-world time-series data.
Multivariate Time Series Early Classification Across Channel and Time Dimensions
Jun 26, 2023Nowadays, the deployment of deep learning models on edge devices for addressing real-world classification problems is becoming more prevalent. Moreover, there is a growing popularity in the approach of early classification, a technique that involves classifying the input data after observing only an early portion of it, aiming to achieve reduced communication and computation requirements, which are crucial parameters in edge intelligence environments. While early classification in the field of time series analysis has been broadly researched, existing solutions for multivariate time series problems primarily focus on early classification along the temporal dimension, treating the multiple input channels in a collective manner. In this study, we propose a more flexible early classification pipeline that offers a more granular consideration of input channels and extends the early classification paradigm to the channel dimension. To implement this method, we utilize reinforcement learning techniques and introduce constraints to ensure the feasibility and practicality of our objective. To validate its effectiveness, we conduct experiments using synthetic data and we also evaluate its performance on real datasets. The comprehensive results from our experiments demonstrate that, for multiple datasets, our method can enhance the early classification paradigm by achieving improved accuracy for equal input utilization.
Modelling Long Range Dependencies in N-D: From Task-Specific to a General Purpose CNN
Jan 25, 2023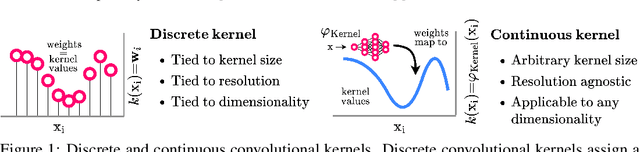
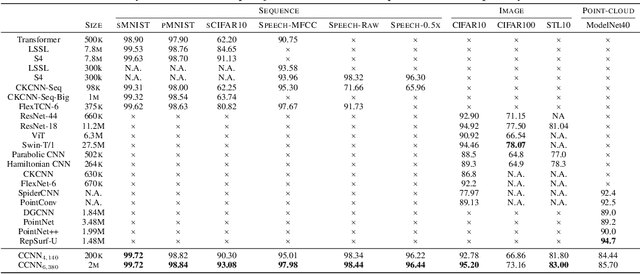
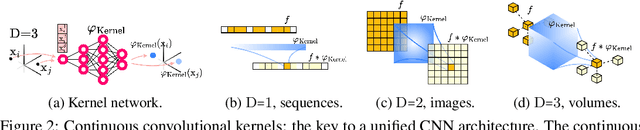
Performant Convolutional Neural Network (CNN) architectures must be tailored to specific tasks in order to consider the length, resolution, and dimensionality of the input data. In this work, we tackle the need for problem-specific CNN architectures. We present the Continuous Convolutional Neural Network (CCNN): a single CNN able to process data of arbitrary resolution, dimensionality and length without any structural changes. Its key component are its continuous convolutional kernels which model long-range dependencies at every layer, and thus remove the need of current CNN architectures for task-dependent downsampling and depths. We showcase the generality of our method by using the same architecture for tasks on sequential ($1{\rm D}$), visual ($2{\rm D}$) and point-cloud ($3{\rm D}$) data. Our CCNN matches and often outperforms the current state-of-the-art across all tasks considered.
Improving generalization in reinforcement learning through forked agents
Dec 14, 2022An eco-system of agents each having their own policy with some, but limited, generalizability has proven to be a reliable approach to increase generalization across procedurally generated environments. In such an approach, new agents are regularly added to the eco-system when encountering a new environment that is outside of the scope of the eco-system. The speed of adaptation and general effectiveness of the eco-system approach highly depends on the initialization of new agents. In this paper we propose different techniques for such initialization and study their impact.
Disentangled (Un)Controllable Features
Oct 31, 2022



In the context of MDPs with high-dimensional states, reinforcement learning can achieve better results when using a compressed, low-dimensional representation of the original input space. A variety of learning objectives have therefore been used to learn useful representations. However, these representations usually lack interpretability of the different features. We propose a representation learning algorithm that is able to disentangle latent features into a controllable and an uncontrollable part. The resulting representations are easily interpretable and can be used for learning and planning efficiently by leveraging the specific properties of the two parts. To highlight the benefits of the approach, the disentangling properties of the algorithm are illustrated in three different environments.
An Empirical Evaluation of Multivariate Time Series Classification with Input Transformation across Different Dimensions
Oct 14, 2022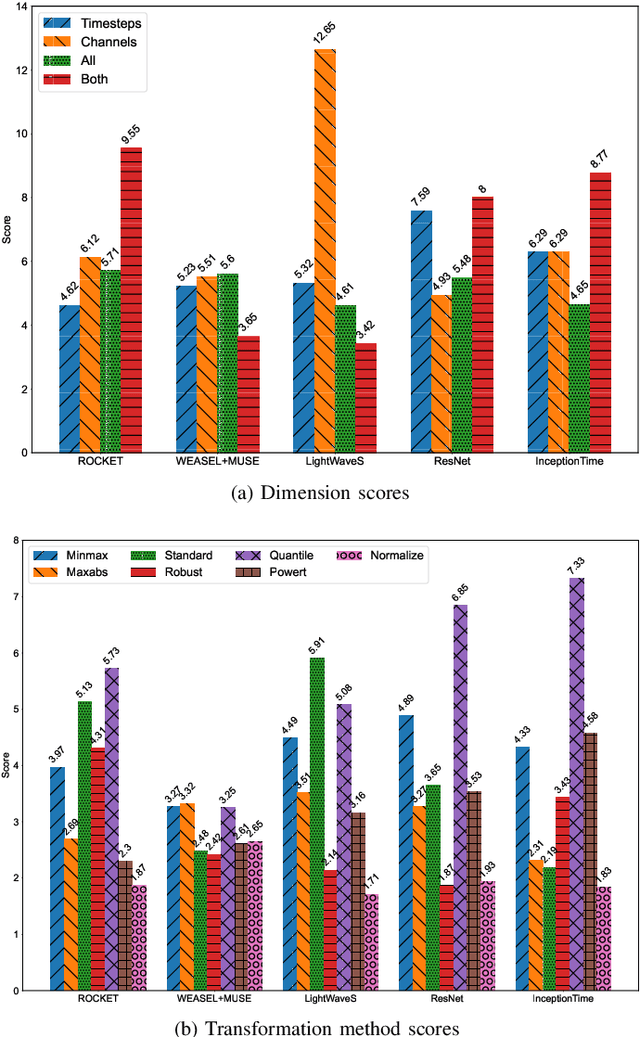

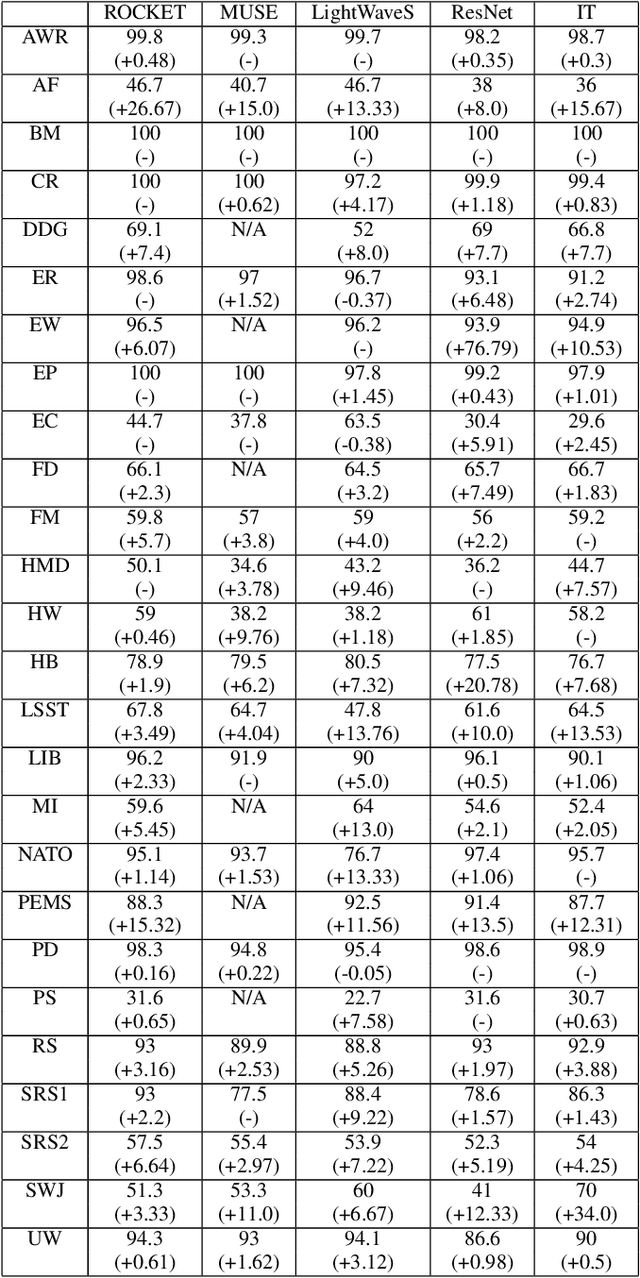
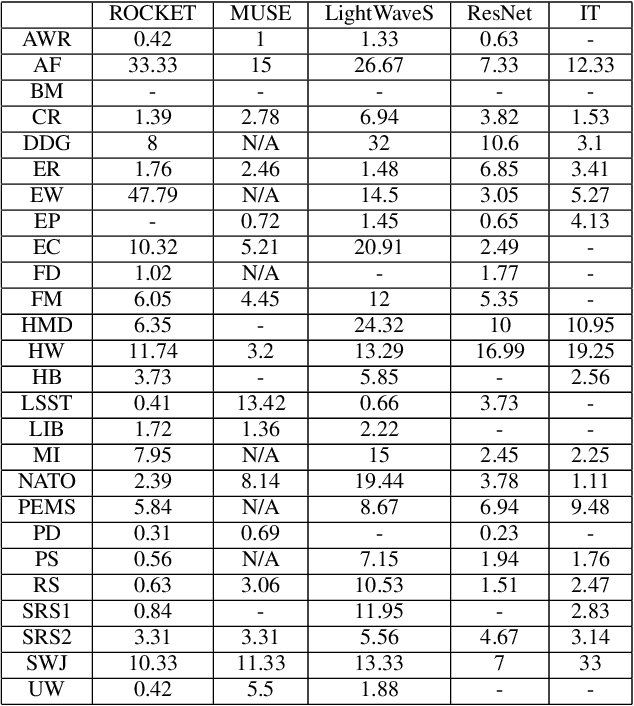
In current research, machine and deep learning solutions for the classification of temporal data are shifting from single-channel datasets (univariate) to problems with multiple channels of information (multivariate). The majority of these works are focused on the method novelty and architecture, and the format of the input data is often treated implicitly. Particularly, multivariate datasets are often treated as a stack of univariate time series in terms of input preprocessing, with scaling methods applied across each channel separately. In this evaluation, we aim to demonstrate that the additional channel dimension is far from trivial and different approaches to scaling can lead to significantly different results in the accuracy of a solution. To that end, we test seven different data transformation methods on four different temporal dimensions and study their effect on the classification accuracy of five recent methods. We show that, for the large majority of tested datasets, the best transformation-dimension configuration leads to an increase in the accuracy compared to the result of each model with the same hyperparameters and no scaling, ranging from 0.16 to 76.79 percentage points. We also show that if we keep the transformation method constant, there is a statistically significant difference in accuracy results when applying it across different dimensions, with accuracy differences ranging from 0.23 to 47.79 percentage points. Finally, we explore the relation of the transformation methods and dimensions to the classifiers, and we conclude that there is no prominent general trend, and the optimal configuration is dataset- and classifier-specific.
Towards a General Purpose CNN for Long Range Dependencies in $\mathrm{N}$D
Jun 07, 2022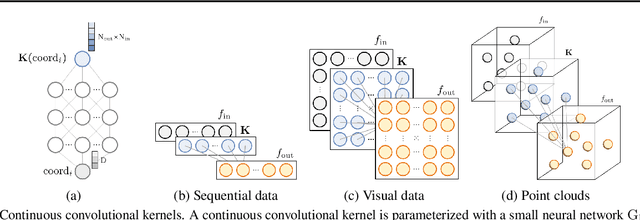
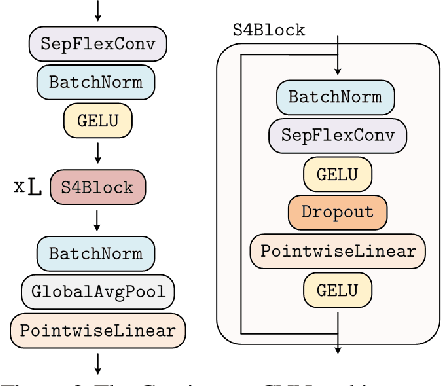
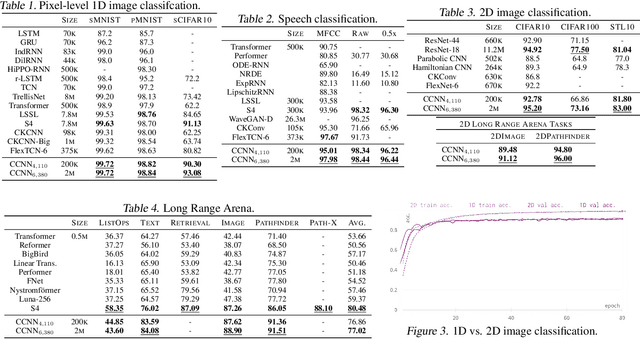
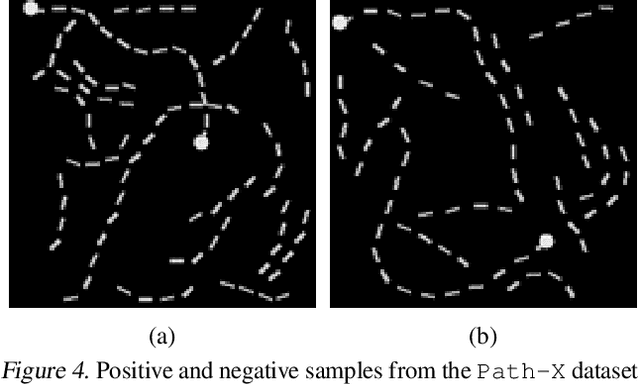
The use of Convolutional Neural Networks (CNNs) is widespread in Deep Learning due to a range of desirable model properties which result in an efficient and effective machine learning framework. However, performant CNN architectures must be tailored to specific tasks in order to incorporate considerations such as the input length, resolution, and dimentionality. In this work, we overcome the need for problem-specific CNN architectures with our Continuous Convolutional Neural Network (CCNN): a single CNN architecture equipped with continuous convolutional kernels that can be used for tasks on data of arbitrary resolution, dimensionality and length without structural changes. Continuous convolutional kernels model long range dependencies at every layer, and remove the need for downsampling layers and task-dependent depths needed in current CNN architectures. We show the generality of our approach by applying the same CCNN to a wide set of tasks on sequential (1$\mathrm{D}$) and visual data (2$\mathrm{D}$). Our CCNN performs competitively and often outperforms the current state-of-the-art across all tasks considered.