 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-Term-to-Long-Term Memory Transfer for Knowledge Graphs under Partial Observability
May 21, 2026Reinforcement learning under partial observability requires deciding what information to retain, yet most memory-based approaches do not explicitly model short-term-to-long-term transfer of symbolic observations. We study this transfer process in a temporal knowledge-graph memory setting and cast it as a neuro-symbolic value-based decision problem: for each observed triple, the agent chooses whether to keep or drop it before long-term insertion. To handle variable-sized short-term buffers, we use a per-item Q-learning design with shared parameters and a practical temporal-difference update over matched items across consecutive steps. On the RoomKG benchmark at long-term memory capacity 128, learned transfer decisions outperform symbolic and neural baselines, including symbolic baselines with temporal annotations and history-based LSTM/Transformer baselines. Across transfer-policy ablations, a lightweight local short-term-only variant performs best, and step-level behavior shows that the policy keeps navigation- and query-relevant facts while discarding lower-value candidate facts, supporting explicit and interpretable memory decisions under memory constraints.
Multi-layer Abstraction for Nested Generation of Options (MANGO) in Hierarchical Reinforcement Learning
Aug 25, 2025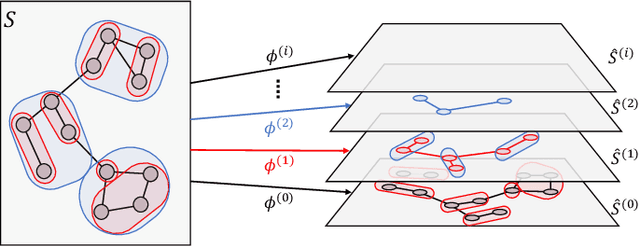
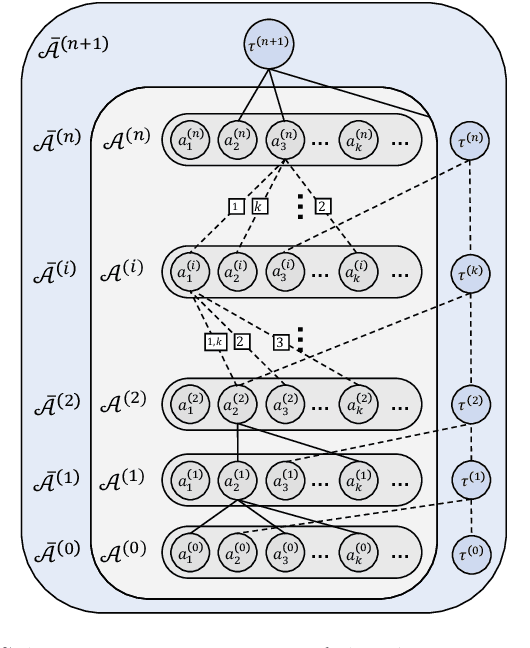

This paper introduces MANGO (Multilayer Abstraction for Nested Generation of Options), a novel hierarchical reinforcement learning framework designed to address the challenges of long-term sparse reward environments. MANGO decomposes complex tasks into multiple layers of abstraction, where each layer defines an abstract state space and employs options to modularize trajectories into macro-actions. These options are nested across layers, allowing for efficient reuse of learned movements and improved sample efficiency. The framework introduces intra-layer policies that guide the agent's transitions within the abstract state space, and task actions that integrate task-specific components such as reward functions. Experiments conducted in procedurally-generated grid environments demonstrate substantial improvements in both sample efficiency and generalization capabilities compared to standard RL methods. MANGO also enhances interpretability by making the agent's decision-making process transparent across layers, which is particularly valuable in safety-critical and industrial applications. Future work will explore automated discovery of abstractions and abstract actions, adaptation to continuous or fuzzy environments, and more robust multi-layer training strategies.
Hadamax Encoding: Elevating Performance in Model-Free Atari
May 21, 2025Neural network architectures have a large impact in machine learning. In reinforcement learning, network architectures have remained notably simple, as changes often lead to small gains in performance. This work introduces a novel encoder architecture for pixel-based model-free reinforcement learning. The Hadamax (\textbf{Hada}mard \textbf{max}-pooling) encoder achieves state-of-the-art performance by max-pooling Hadamard products between GELU-activated parallel hidden layers. Based on the recent PQN algorithm, the Hadamax encoder achieves state-of-the-art model-free performance in the Atari-57 benchmark. Specifically, without applying any algorithmic hyperparameter modifications, Hadamax-PQN achieves an 80\% performance gain over vanilla PQN and significantly surpasses Rainbow-DQN. For reproducibility, the full code is available on \href{https://github.com/Jacobkooi/Hadamax}{GitHub}.
Leveraging Knowledge Graph-Based Human-Like Memory Systems to Solve Partially Observable Markov Decision Processes
Aug 11, 2024Humans observe only part of their environment at any moment but can still make complex, long-term decisions thanks to our long-term memory system. To test how an AI can learn and utilize its long-term memory system, we have developed a partially observable Markov decision processes (POMDP) environment, where the agent has to answer questions while navigating a maze. The environment is completely knowledge graph (KG) based, where the hidden states are dynamic KGs. A KG is both human- and machine-readable, making it easy to see what the agents remember and forget. We train and compare agents with different memory systems, to shed light on how human brains work when it comes to managing its own memory systems. By repurposing the given learning objective as learning a memory management policy, we were able to capture the most likely belief state, which is not only interpretable but also reusable.
Latent Assistance Networks: Rediscovering Hyperbolic Tangents in RL
Jun 13, 2024Activation functions are one of the key components of a neural network. The most commonly used activation functions can be classed into the category of continuously differentiable (e.g. tanh) and linear-unit functions (e.g. ReLU), both having their own strengths and drawbacks with respect to downstream performance and representation capacity through learning (e.g. measured by the number of dead neurons and the effective rank). In reinforcement learning, the performance of continuously differentiable activations often falls short as compared to linear-unit functions. From the perspective of the activations in the last hidden layer, this paper provides insights regarding this sub-optimality and explores how activation functions influence the occurrence of dead neurons and the magnitude of the effective rank. Additionally, a novel neural architecture is proposed that leverages the product of independent activation values. In the Atari domain, we show faster learning, a reduction in dead neurons and increased effective rank.
A Machine with Short-Term, Episodic, and Semantic Memory Systems
Dec 05, 2022Inspired by the cognitive science theory of the explicit human memory systems, we have modeled an agent with short-term, episodic, and semantic memory systems, each of which is modeled with a knowledge graph. To evaluate this system and analyze the behavior of this agent, we designed and released our own reinforcement learning agent environment, "the Room", where an agent has to learn how to encode, store, and retrieve memories to maximize its return by answering questions. We show that our deep Q-learning based agent successfully learns whether a short-term memory should be forgotten, or rather be stored in the episodic or semantic memory systems. Our experiments indicate that an agent with human-like memory systems can outperform an agent without this memory structure in the environment.
Disentangled (Un)Controllable Features
Oct 31, 2022



In the context of MDPs with high-dimensional states, reinforcement learning can achieve better results when using a compressed, low-dimensional representation of the original input space. A variety of learning objectives have therefore been used to learn useful representations. However, these representations usually lack interpretability of the different features. We propose a representation learning algorithm that is able to disentangle latent features into a controllable and an uncontrollable part. The resulting representations are easily interpretable and can be used for learning and planning efficiently by leveraging the specific properties of the two parts. To highlight the benefits of the approach, the disentangling properties of the algorithm are illustrated in three different environments.
A Meta-Reinforcement Learning Algorithm for Causal Discovery
Jul 18, 2022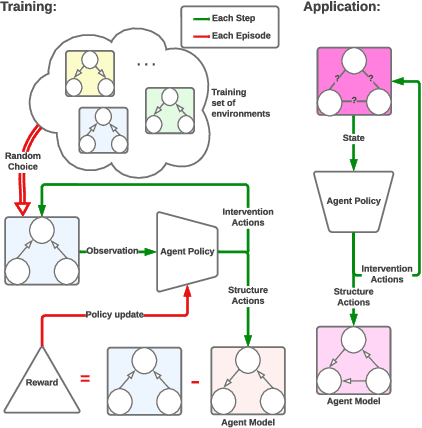
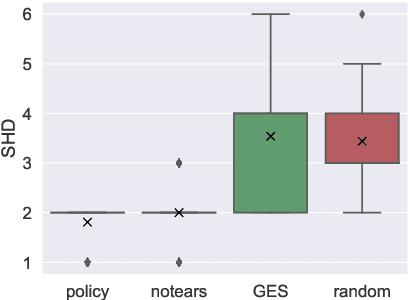
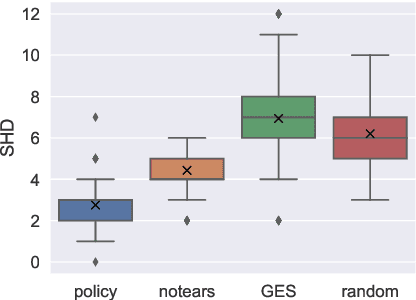
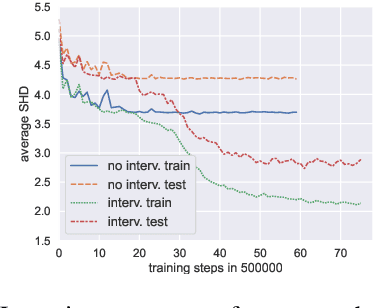
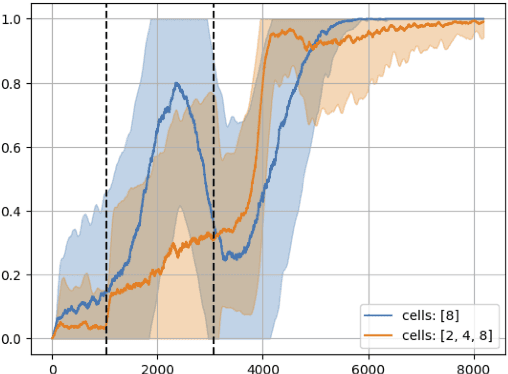
Causal discovery is a major task with the utmost importance for machine learning since causal structures can enable models to go beyond pure correlation-based inference and significantly boost their performance. However, finding causal structures from data poses a significant challenge both in computational effort and accuracy, let alone its impossibility without interventions in general. In this paper, we develop a meta-reinforcement learning algorithm that performs causal discovery by learning to perform interventions such that it can construct an explicit causal graph. Apart from being useful for possible downstream applications, the estimated causal graph also provides an explanation for the data-generating process. In this article, we show that our algorithm estimates a good graph compared to the SOTA approaches, even in environments whose underlying causal structure is previously unseen. Further, we make an ablation study that shows how learning interventions contribute to the overall performance of our approach. We conclude that interventions indeed help boost the performance, efficiently yielding an accurate estimate of the causal structure of a possibly unseen environment.
Domain Adversarial Reinforcement Learning
Feb 14, 2021

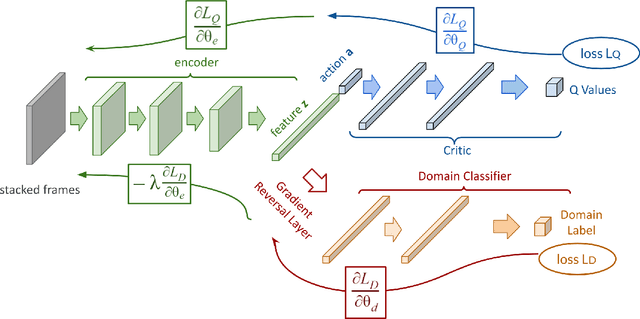
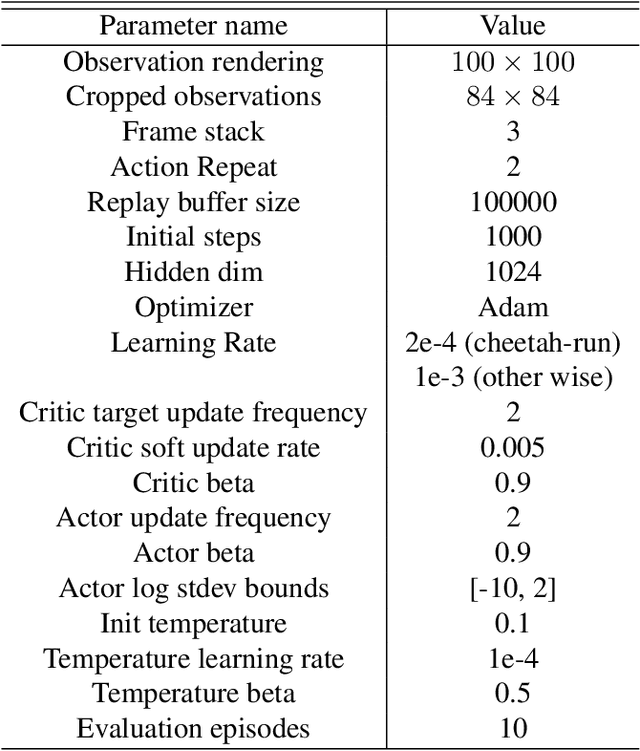
We consider the problem of generalization in reinforcement learning where visual aspects of the observations might differ, e.g. when there are different backgrounds or change in contrast, brightness, etc. We assume that our agent has access to only a few of the MDPs from the MDP distribution during training. The performance of the agent is then reported on new unknown test domains drawn from the distribution (e.g. unseen backgrounds). For this "zero-shot RL" task, we enforce invariance of the learned representations to visual domains via a domain adversarial optimization process. We empirically show that this approach allows achieving a significant generalization improvement to new unseen domains.
Novelty Search in Representational Space for Sample Efficient Exploration
Oct 21, 2020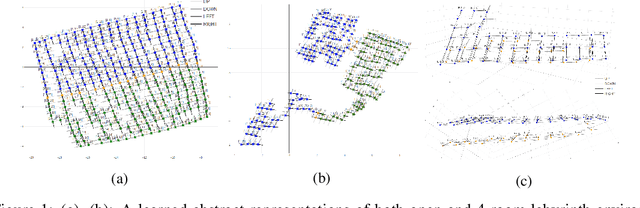
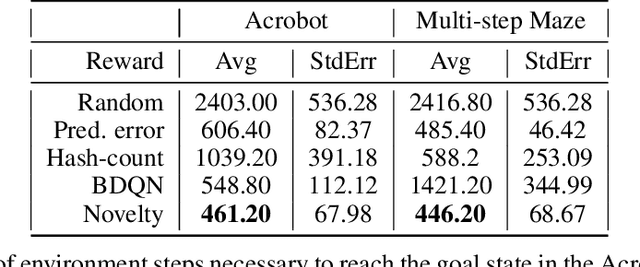
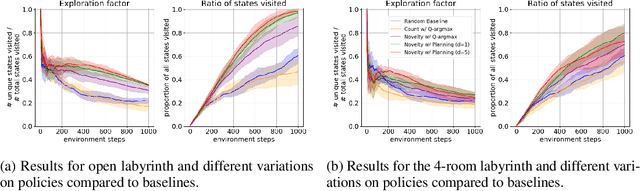
We present a new approach for efficient exploration which leverages a low-dimensional encoding of the environment learned with a combination of model-based and model-free objectives. Our approach uses intrinsic rewards that are based on the distance of nearest neighbors in the low dimensional representational space to gauge novelty. We then leverage these intrinsic rewards for sample-efficient exploration with planning routines in representational space for hard exploration tasks with sparse rewards. One key element of our approach is the use of information theoretic principles to shape our representations in a way so that our novelty reward goes beyond pixel similarity. We test our approach on a number of maze tasks, as well as a control problem and show that our exploration approach is more sample-efficient compared to strong baselines.