Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adversarial Reinforcement Learning
Paper and Code
Feb 14, 2021

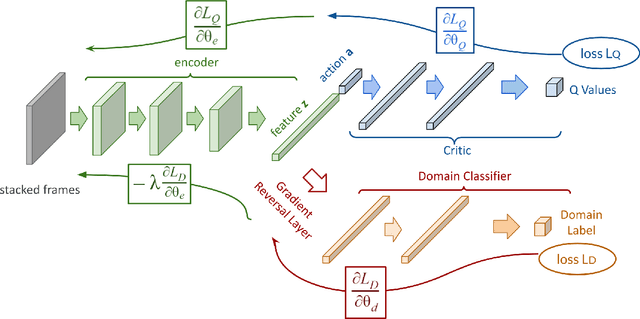
We consider the problem of generalization in reinforcement learning where visual aspects of the observations might differ, e.g. when there are different backgrounds or change in contrast, brightness, etc. We assume that our agent has access to only a few of the MDPs from the MDP distribution during training. The performance of the agent is then reported on new unknown test domains drawn from the distribution (e.g. unseen backgrounds). For this "zero-shot RL" task, we enforce invariance of the learned representations to visual domains via a domain adversarial optimization process. We empirically show that this approach allows achieving a significant generalization improvement to new unseen domains.
View paper on